

KernelMixtureDistribution
KernelMixtureDistribution[{x1,x2,…}]
represents a kernel mixture distribution based on the data values xi.
KernelMixtureDistribution[{{x1,y1,…},{x2,y2,…},…}]
represents a multivariate kernel mixture distribution based on data values {xi,yi,…}.
KernelMixtureDistribution[…,bw]
represents a kernel mixture distribution with bandwidth bw.
KernelMixtureDistribution[…,bw,ker]
represents a kernel mixture distribution with bandwidth bw and smoothing kernel ker.
Details and Options
- KernelMixtureDistribution returns a DataDistribution object that can be used like any other probability distribution.
- The probability density function for KernelMixtureDistribution for a value
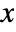 is given by
is given by 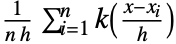 for a smoothing kernel
for a smoothing kernel 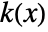 and bandwidth parameter
and bandwidth parameter 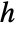 .
. - The following bandwidth specifications bw can be given:
-
h bandwidth to use {"Standardized",h} bandwidth in units of standard deviation {"Adaptive",h,s} adaptive bandwidth with initial bandwidth h and sensitivity s Automatic automatically computed bandwidth "name" use a named bandwidth selection method {bwx,bwy,…} separate bandwidth specifications for x, y, etc. - For multivariate densities, h can be a positive definite symmetric matrix.
- For adaptive bandwidths, the sensitivity s must be a real number between 0 and 1 or Automatic. If Automatic is used, s is set to
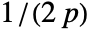 , where
, where 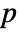 is the dimensionality of the data.
is the dimensionality of the data. - Possible named bandwidth selection methods include:
-
"LeastSquaresCrossValidation" uses the method of least-squares cross-validation "Oversmooth" 1.08 times wider than the standard Gaussian "Scott" uses Scott's rule to determine bandwidth "SheatherJones" uses the Sheather–Jones plugin estimator "Silverman" uses Silverman's rule to determine bandwidth "StandardDeviation" uses the standard deviation as bandwidth "StandardGaussian" optimal bandwidth for standard normal data - By default, the "Silverman" method is used.
- For automatic bandwidth computation, constant arrays are assumed to have unit variance.
- The following kernel specifications ker can be given:
-
"Biweight" 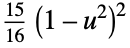
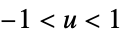
"Cosine" 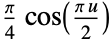
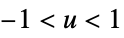
"Epanechnikov" 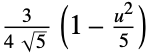
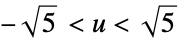
"Gaussian" 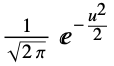
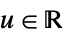
"Rectangular" 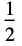
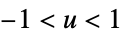
"SemiCircle" 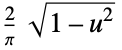
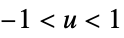
"Triangular" 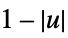
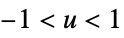
"Triweight" 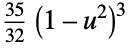
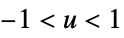
func 

- In order for KernelMixtureDistribution to generate a true density estimate, the function fn should be a valid univariate probability density function.
- By default, the "Gaussian" kernel is used.
- For multivariate densities, the kernel function ker can be specified as product and radial types using {"Product",ker} and {"Radial",ker}, respectively. Product-type kernels are used if no type is specified.
- The precision used for density estimation is the minimum precision given in the bw and data.
- The following options can be given:
-
MaxMixtureKernels Automatic max number of kernels to use - KernelMixtureDistribution can be used with such functions as Mean, CDF, and RandomVariate.
Examples
open all close allBasic Examples (3)
Create a kernel density estimate of univariate data:
BlockRandom[SeedRandom[1];data = RandomVariate[NormalDistribution[], 10 ^ 4]];𝒟 = KernelMixtureDistribution[data];Use the resulting distribution to perform analysis, including visualizing distribution functions:
Table[Plot[f[𝒟, x], {x, -4, 4}, Filling -> Axis, PlotLabel -> f], {f, {PDF, CDF}}]Compute moments and quantiles:
Moment[𝒟, 2]Quantile[𝒟, .8]Create a kernel density estimate of some bivariate data:
BlockRandom[SeedRandom[1];data = RandomVariate[BinormalDistribution[.75], 10 ^ 3];];𝒟 = KernelMixtureDistribution[data];Visualize the estimated PDF and CDF:
Table[ContourPlot[f[𝒟, {x, y}], {x, -3, 3}, {y, -3, 3}, PlotRange -> All, PlotLabel -> f], {f, {PDF, CDF}}]Compute covariance and general moments:
Covariance[𝒟]//MatrixFormMoment[𝒟, {1, 2}]Create symbolic representations of kernel density estimates:
data = {Subscript[x, 1], Subscript[x, 2], Subscript[x, 3]};𝒟 = KernelMixtureDistribution[data, h];Investigate symbolic properties:
PDF[𝒟, x]//ExpandVariance[𝒟]Skewness[𝒟]Scope (47)
Basic Uses (8)
Create a kernel density estimate for some data:
data = RandomVariate[NormalDistribution[], 100];𝒟 = KernelMixtureDistribution[data];Show[Histogram[data, Automatic, "PDF"], Plot[PDF[𝒟, x], {x, -4, 4}, PlotStyle -> Thick]]Compute probabilities from the distribution:
Probability[x > 2, x𝒟]Create a kernel density estimate for data with quantities:
data = RandomVariate[GammaDistribution[1, Quantity[2, "s"]], 10 ^ 3]𝒟 = KernelMixtureDistribution[data]#[𝒟]& /@ {Mean, Variance, Skewness, Kurtosis}Increase the bandwidth for smoother estimates:
data = RandomVariate[NormalDistribution[], 50];bw = {.1, .2, .3, .5};Table[Plot[PDF[KernelMixtureDistribution[data, i], x]//Evaluate, {x, -4, 4}, PlotRange -> {0, 2}, PlotLabel -> Row[{"band width = ", i}], Filling -> 0], {i, bw}]//QuietAllow the bandwidth to vary adaptively with local density:
data = RandomVariate[𝒹 = MixtureDistribution[{2, 1}, {NormalDistribution[], NormalDistribution[2, 1 / 2]}], 10^4];𝒟 = KernelMixtureDistribution[data, {"Adaptive", Automatic, Automatic}];Plot[{PDF[𝒹, x], PDF[𝒟, x]}, {x, -4, 4}, PlotLegends -> {"𝒹", "𝒟"}]Identify features in data to aid in parametric model fitting:
data = ExampleData[{"Statistics", "OldFaithful"}][[All, 1]];𝒟 = KernelMixtureDistribution[data, "LeastSquaresCrossValidation"];Plot[PDF[𝒟, x], {x, 1, 6}]The estimate suggests both the form and starting values for maximum likelihood estimation:
est = EstimatedDistribution[data, MixtureDistribution[{1 / 3, 2 / 3}, {NormalDistribution[μ1, σ1], NormalDistribution[μ2, σ2]}], {{μ1, 2.0}, {σ1, .25}, {μ2, 4.3}, {σ2, .5}}];Plot[{PDF[𝒟, x], PDF[est, x]}, {x, 1, 6}, PlotLegends -> {"𝒟", "est"}]Use kernel density estimation in higher dimensions:
data = RandomVariate[MultinormalDistribution[{0, 0, 0, 0}, IdentityMatrix[4]], 25];A four-dimensional kernel density estimate:
𝒟 = KernelMixtureDistribution[data];Table[Plot[PDF[MarginalDistribution[𝒟, i], x]//Evaluate, {x, -4, 4}, PlotRange -> All, Filling -> Axis, PlotLabel -> i, Axes -> {True, False}], {i, 4}]data2 = RandomVariate[𝒟, 10^4];Table[Histogram[data2[[All, i]], 30, PlotRange -> {{-4, 4}, All}, Axes -> {True, False}], {i, 4}]Explore properties of kernel density estimators using custom kernel functions:
data = {χ[1], χ[2], χ[3]};𝒟 = KernelMixtureDistribution[data, h, PDF[StudentTDistribution[ν], #]&];PDF[𝒟, x]//FullSimplifyProbability[x > 0, x𝒟]//FullSimplifySpecify radial- or product-type kernels for multivariate estimates:
data = RandomVariate[BinormalDistribution[2 / 5], 250];𝓀ℯ𝓇𝓃ℯℓ = PDF[LaplaceDistribution[0, 1], #]&;𝒟 = Table[KernelMixtureDistribution[data, {{1, .25}, {.25, 1}}, 𝒦], {𝒦, {{"Radial", 𝓀ℯ𝓇𝓃ℯℓ}, {"Product", 𝓀ℯ𝓇𝓃ℯℓ}}}];Table[Plot3D[PDF[i, {x, y}], {x, -5, 5}, {y, -5, 5}, PlotRange -> All, Exclusions -> None, MeshFunctions -> (#3&)], {i, 𝒟}]Distribution Properties (10)
Estimate distribution functions:
𝒟 = KernelMixtureDistribution[RandomVariate[NormalDistribution[], 10^3]];Table[Plot[f[𝒟, x]//Evaluate, {x, -4, 4}, Frame -> True, Filling -> Axis, PlotLabel -> f], {f, {PDF, CDF, HazardFunction, SurvivalFunction}}]The first few terms of the PDF and CDF:
PDF[𝒟, x][[1 ;; 3]]CDF[𝒟, x][[1 ;; 3]]Compute moments of the distribution:
𝒟 = KernelMixtureDistribution[RandomVariate[NormalDistribution[], 1000], {"Adaptive", Automatic, .5}, "Biweight"];{Mean[𝒟], Variance[𝒟], Skewness[𝒟], Kurtosis[𝒟]}Table[Moment[𝒟, k], {k, 4}]Table[CentralMoment[𝒟, k], {k, 4}]Table[Cumulant[𝒟, k], {k, 4}]Table[FactorialMoment[𝒟, k], {k, 4}]Moments can often be computed in closed form:
𝒟 = KernelMixtureDistribution[Range[5], h, "Epanechnikov"];{Mean[𝒟], Variance[𝒟], Skewness[𝒟], Kurtosis[𝒟]}Compute a closed form expression for the variance with a symbolic adaptive bandwidth:
𝒟 = KernelMixtureDistribution[Range[3], {"Adaptive", h, 1 / 4}];Variance[𝒟]//Simplify𝒟 = KernelMixtureDistribution[RandomVariate[NormalDistribution[], 15]];Plot[Quantile[𝒟, p], {p, 0, 1}, Filling -> Axis, Exclusions -> None]Quartiles[𝒟]InterquartileRange[𝒟]Quantile[𝒟, {0.05, 0.95}]Median[𝒟]𝒟 = KernelMixtureDistribution[RandomVariate[NormalDistribution[], 1000]];RandomVariate[𝒟, 10]Compare with KernelMixtureDistribution:
Show[Histogram[RandomVariate[𝒟, 10^4], Automatic, "ProbabilityDensity"],
Plot[PDF[𝒟, x], {x, -4, 4}, Exclusions -> False, PlotStyle -> Thick]]Compute probabilities and expectations:
𝒟 = KernelMixtureDistribution[RandomVariate[NormalDistribution[], 10 ^ 3]];Probability[x < 3, x𝒟]Expectation[x^2, x𝒟]𝒟 = KernelMixtureDistribution[Range[5], h];MomentGeneratingFunction[𝒟, t]CharacteristicFunction[𝒟, t]Estimate bivariate distribution functions:
𝒟 = KernelMixtureDistribution[RandomVariate[BinormalDistribution[.75], 100]];Table[DiscretePlot3D[f[𝒟, {x, y}]//Evaluate, {x, -4, 4, .5}, {y, -4, 4, .5}, PlotLabel -> f, ExtentSize -> 1 / 2], {f, {PDF, CDF, HazardFunction, SurvivalFunction}}]Compute moments of a bivariate distribution:
𝒟 = KernelMixtureDistribution[RandomReal[BinormalDistribution[.75], 1000]];{Mean[𝒟], Variance[𝒟]}Covariance[𝒟]//MatrixFormCorrelation[𝒟]//MatrixFormMoment[𝒟, {1, 2}]CentralMoment[𝒟, {1, 2}]Cumulant[𝒟, {1, 2}]FactorialMoment[𝒟, {1, 2}]𝒟 = KernelMixtureDistribution[RandomReal[BinormalDistribution[.5], 10 ^ 4]];ListPlot[RandomVariate[𝒟, 10^4], PlotStyle -> PointSize[Tiny], PlotRange -> {{-4, 4}, {-4, 4}}]Bandwidth Selection (19)
Automatically select the bandwidth to use:
data1 = RandomVariate[𝒹 = NormalDistribution[], 10];
data2 = RandomVariate[𝒹, 10 ^ 4];𝒟1 = KernelMixtureDistribution[data1];
𝒟2 = KernelMixtureDistribution[data2];More data yields better approximations to the underlying distribution:
Table[Plot[{PDF[𝒟, x], PDF[𝒹, x]}, {x, -4, 4}, Filling -> Axis, Exclusions -> None], {𝒟, {𝒟1, 𝒟2}}]Explicitly specify the bandwidth to use:
data = RandomVariate[NormalDistribution[], 10 ^ 3];Use bandwidths of 0.1 and 1.0:
𝒟1 = KernelMixtureDistribution[data, 0.1];
𝒟2 = KernelMixtureDistribution[data, 1.0];Larger bandwidths yield smoother estimates:
Table[Plot[PDF[𝒟, x], {x, -4, 4}, Filling -> Axis, Exclusions -> None], {𝒟, {𝒟1, 𝒟2}}]The bandwidth need not be numeric:
data = Range[5];𝒟 = KernelMixtureDistribution[data, h];The PDF and CDF of the estimate:
PDF[𝒟, x]//ExpandCDF[𝒟, x]//ExpandSpecify bandwidths in units of standard deviation:
data = RandomVariate[NormalDistribution[], 10 ^ 3];𝒟1 = KernelMixtureDistribution[data, {"Standardized", 1 / 2}];
𝒟2 = KernelMixtureDistribution[data, {"Standardized", 1 / 8}];Table[Plot[PDF[𝒟, x], {x, -4, 4}, PlotRange -> {0, .4}, Filling -> Axis, Exclusions -> None, PlotLabel -> Row[{"Bandwidth = ", 𝒟["Bandwidth"]}]], {𝒟, {𝒟1, 𝒟2}}]Allow the bandwidth to vary adaptively with local density:
data = RandomVariate[NormalDistribution[], 10 ^ 3];Vary the local sensitivity from 0 (none) to 1 (full):
Table[Plot[PDF[KernelMixtureDistribution[data, {"Adaptive", Automatic, s}], x]//Evaluate, {x, -4, 4}, PlotLabel -> Row[{"s = ", s}]], {s, {0, .25, .75, 1}}]//QuietSetting the sensitivity to Automatic uses ![]() where
where ![]() is the dimension of the data:
is the dimension of the data:
data = RandomVariate[NormalDistribution[], 10^3];p = 1;𝒟1 = KernelMixtureDistribution[data, {"Adaptive", Automatic, (1/2 p)}];
𝒟2 = KernelMixtureDistribution[data, {"Adaptive", Automatic, Automatic}];Table[Plot[PDF[𝒟, x], {x, -4, 4}, Filling -> Axis, Exclusions -> None], {𝒟, {𝒟1, 𝒟2}}]Vary the initial bandwidth for an adaptive estimate:
data = RandomVariate[NormalDistribution[], 10 ^ 3];Specify an initial bandwidth of 1 and 0.1, respectively:
𝒟1 = KernelMixtureDistribution[data, {"Adaptive", 1, .5}];
𝒟2 = KernelMixtureDistribution[data, {"Adaptive", 0.1, .5}];Table[Plot[PDF[𝒟, x], {x, -4, 4}, Filling -> Axis, Exclusions -> None], {𝒟, {𝒟1, 𝒟2}}]Use any of several automatic bandwidth selection methods:
data = RandomVariate[NormalDistribution[], 100];Table[Plot[PDF[KernelMixtureDistribution[data, name], x]//Evaluate, {x, -4, 4}, Filling -> Axis, Exclusions -> None, PlotLabel -> name], {name, {"LeastSquaresCrossValidation", "Oversmooth", "Scott", "SheatherJones", "StandardDeviation", "StandardGaussian"}}]Silverman's method is used by default:
data = RandomVariate[NormalDistribution[], 10 ^ 3];𝒟1 = KernelMixtureDistribution[data, "Silverman"];
𝒟2 = KernelMixtureDistribution[data, Automatic];Table[Plot[PDF[𝒟, x], {x, -4, 4}, Filling -> Axis, Exclusions -> None], {𝒟, {𝒟1, 𝒟2}}]In the multivariate case, the bandwidth is a symmetric positive definite ![]() ×
×![]() matrix:
matrix:
p = 2;n = 2;data = Array[x, {n, p}];Giving a scalar h effectively uses h IdentityMatrix[p]:
PDF[KernelMixtureDistribution[data, h], {y1, y2}]PDF[KernelMixtureDistribution[data, h * IdentityMatrix[p]], {y1, y2}]Specifying diagonal elements d effectively uses DiagonalMatrix[d]:
d = Array[h, p]PDF[KernelMixtureDistribution[data, d], {y1, y2}]PDF[KernelMixtureDistribution[data, DiagonalMatrix[d]], {y1, y2}]Any ![]() ×
×![]() matrix that could be symmetric positive definite can be given:
matrix that could be symmetric positive definite can be given:
𝒟 = KernelMixtureDistribution[data, {{d1, od}, {od, d2}}]By default, Silverman's method is used to independently select bandwidths in each dimension:
data = RandomVariate[BinormalDistribution[.75], 25];Table[Plot3D[PDF[KernelMixtureDistribution[data, name], {x, y}]//Evaluate, {x, -3, 3}, {y, -3, 3}, PlotRange -> All, PlotLabel -> name, Exclusions -> None], {name, {Automatic, "Silverman"}}]Any automated method can be used to independently select diagonal bandwidth elements:
data = RandomVariate[BinormalDistribution[.75], 25];Table[Plot3D[PDF[KernelMixtureDistribution[data, name], {x, y}]//Evaluate, {x, -3, 3}, {y, -3, 3}, PlotRange -> All, PlotLabel -> name, Exclusions -> None], {name, {"LeastSquaresCrossValidation", "Oversmooth", "Scott", "SheatherJones", "StandardDeviation", "StandardGaussian"}}]Methods used to estimate the diagonal need not be the same:
data = RandomVariate[NormalDistribution[], {1000, 3}];Use adaptive, oversmoothed, and constant bandwidths in the respective dimensions:
𝒟 = KernelMixtureDistribution[data, {{"Adaptive", .05, 1}, "Silverman", 10}];Plot the univariate marginal PDFs:
Table[Plot[PDF[MarginalDistribution[𝒟, i], x]//Evaluate, {x, -4, 4}, Filling -> Axis, Exclusions -> None, PlotLabel -> i], {i, {1, 2, 3}}]//QuietGive a scalar value to use the same bandwidth in all dimensions:
data = RandomVariate[BinormalDistribution[.75], 25];ℬs = {.25, .5, 1.0};Table[Plot3D[PDF[KernelMixtureDistribution[data, bw], {x, y}]//Evaluate, {x, -3, 3}, {y, -3, 3}, PlotRange -> All, PlotLabel -> Row[{"bandwidth = ", bw * IdentityMatrix[2]}], Exclusions -> None], {bw, ℬs}]To use nonzero off-diagonal elements, give a fully specified bandwidth matrix:
bw = {{1 / 2, 1 / 4}, {1 / 4, 1 / 2}};𝒟 = KernelMixtureDistribution[RandomVariate[NormalDistribution[], {100, 2}], bw];ContourPlot[PDF[𝒟, {x, y}], {x, -3, 3}, {y, -3, 3}, PlotPoints -> 50, PlotRange -> All]The bandwidth matrix controls the variance and orientation of individual kernels:
𝒟 = Hold[KernelMixtureDistribution[{{0, 0}}, h]];Table[ContourPlot[PDF[𝒟 /. h -> i//ReleaseHold, {x, y}]//Evaluate, {x, -2, 2}, {y, -2, 2}, PlotRange -> All, PlotLabel -> i, Frame -> None], {i, {.25, .5, .75, 1.}}]Table[ContourPlot[PDF[𝒟 /. h -> i//ReleaseHold, {x, y}]//Evaluate, {x, -2, 2}, {y, -2, 2}, PlotRange -> All, PlotLabel -> i, Frame -> None], {i, {{.5, .5}, {.5, .75}, {.75, .75}, {.75, .5}}}]Fully specified bandwidth matrices:
Table[ContourPlot[PDF[𝒟 /. h -> i//ReleaseHold, {x, y}]//Evaluate, {x, -2, 2}, {y, -2, 2}, PlotRange -> All, PlotLabel -> i, Frame -> None], {i, {{{.75, 0}, {0, .5}}, {{.75, .25}, {.25, .5}}, {{.5, .25}, {.25, .75}}, {{.5, -.25}, {-.25, .75}}}}]Some named bandwidth methods follow a rule-of-thumb approach:
n = 10;data = RandomVariate[NormalDistribution[], n];iqr = (Quantile[data, .75] - Quantile[data, .25]);sd = StandardDeviation[data];Formulas for some named bandwidth methods:
silverman = .9 Min[(iqr/1.34), sd] n^-1 / 5;stdGauss = (2^2 / 5/3^1 / 5) Min[(iqr/1.34), sd] n^-1 / 5;overSmooth = 1.08 stdGauss;scott = sd * n^-1 / 5;pdf1 = Table[Plot[PDF[KernelMixtureDistribution[data, i], x]//Evaluate, {x, -4, 4}, Ticks -> None], {i, {silverman, stdGauss, overSmooth, scott}}];
pdf2 = Table[Plot[PDF[KernelMixtureDistribution[data, i], x]//Evaluate, {x, -4, 4}, Ticks -> None], {i, {"Silverman", "StandardGaussian", "Oversmooth", "Scott"}}];MapThread[Show[#1, #2, PlotLabel -> #3]&, {pdf1, pdf2, {"Silverman", "StandardGaussian", "Oversmooth", "Scott"}}]The method of least-squares cross-validation:
data = RandomVariate[NormalDistribution[], 25];The expectation of the PDF using a Gaussian kernel and bandwidth ![]() :
:
Rk[h_, data_] := With[{n = Length[data]}, 1 / (h Sqrt[π]) (Exp[-((Subtract@@@Subsets[data, {2}]) ^ 2 / (4 h ^ 2))].ConstantArray[1 / n ^ 2, Total[Range[1, n - 1]]] + 1 / (2 n))]The expectation of the PDF of the leave-one-out density estimator:
Ro[h_, data_] := Total[1 / ((Length[data] - 1) h Sqrt[2 π])Table[Plus@@Exp[-(data[[i]] - Delete[data, {i}]) ^ 2 / (2 h ^ 2)], {i, Length[data]}]]LSCV[h_, data_] := With[{n = Length[data]}, Rk[h, data] - (2/n) Ro[h, data]]The bandwidth is found by minimizing the least-squares cross-validation function over ![]() :
:
bw = FindMinimum[LSCV[h, data], {h}][[2]]Show[Plot[LSCV[h, data], {h, 0.01, 2}], Graphics[Arrow[{{h /. bw, 0}, {h /. bw, LSCV[h /. bw, data]}}]]]The method of Sheather and Jones uses a plugin estimator to solve for the bandwidth:
ϕIV[xsq_] := Total[(3 + xsq (-6 + xsq))E^-xsq / 2]ϕVI[xsq_] := Total[(-15 + xsq (45 + xsq (-15 + xsq)))E^-xsq / 2]The Sheather and Jones estimator:
SheatherJonesBW[data_] := Block[{n = Length[data], λ, a, b, δ2, α2, h},
λ = Min[(Quantile[data, .75] - Quantile[data, .25]) / 1.34, StandardDeviation[data]];
a = (92/100) λ n^-1 / 7;
b = (912 /1000)λ n^-1 / 9;
δ2 = Flatten[Table[(data - i)^2, {i, data}]];
α2 = (1357/1000) ((b^7 n (n - 1)ϕIV[δ2 / a^2]/-a^5 n (n - 1) ϕVI[δ2 / b^2]))^1 / 7 h^5 / 7;
FindRoot[((α2^5 n (n - 1)/ϕIV[δ2 / α2^2]))^1 / 5 - h (n Sqrt[2])^1 / 5 == 0, {h, λ}]
]data = RandomVariate[NormalDistribution[], 15];sjbw = SheatherJonesBW[data]Plot[{PDF[KernelMixtureDistribution[data, h /. sjbw], x], PDF[KernelMixtureDistribution[data, "SheatherJones"], x]}//Evaluate, {x, -3, 3}]Kernel Functions (10)
Specify any one of several kernel functions:
data = RandomVariate[NormalDistribution[], 100];Table[Plot[PDF[ KernelMixtureDistribution[data, Automatic, i], x]//Evaluate, {x, -4, 4}, Filling -> Axis, Ticks -> None, PlotLabel -> i, Exclusions -> None], {i, {"Biweight", "Cosine", "Epanechnikov", "Gaussian", "Rectangular", "SemiCircle", "Triangular", "Triweight"}}]Define the kernel function as a pure function:
data = RandomVariate[NormalDistribution[], 10];𝒟1 = KernelMixtureDistribution[data, Automatic];
𝒟2 = KernelMixtureDistribution[data, Automatic, (1/π (1 + #1^2))&];Table[Plot[PDF[𝒟, x]//Evaluate, {x, -4, 4}, Filling -> Axis, Exclusions -> None], {𝒟, {𝒟1, 𝒟2}}]By default, the Gaussian kernel is used:
data = RandomVariate[NormalDistribution[], 10];𝒟1 = KernelMixtureDistribution[data, Automatic];
𝒟2 = KernelMixtureDistribution[data, Automatic, "Gaussian"];Table[Plot[PDF[𝒟, x]//Evaluate, {x, -4, 4}, Filling -> Axis, Exclusions -> None, PlotRange -> All], {𝒟, {𝒟1, 𝒟2}}]This is equivalent to using the PDF of a NormalDistribution[0,1]:
𝒟3 = KernelMixtureDistribution[data, Automatic, PDF[NormalDistribution[], #]&];Plot[PDF[𝒟3, x], {x, -4, 4}, Filling -> Axis, Exclusions -> None, PlotRange -> All]Shapes of some univariate kernel functions:
kernels = {"Biweight", "Cosine", "Epanechnikov", "Gaussian", "Rectangular", "SemiCircle", "Triangular", "Custom"};dists = Table[KernelMixtureDistribution[{0}, 1, i], {i, (kernels /. {"Custom" -> (PDF[CauchyDistribution[0, 1], #]&)})}];Table[Plot[PDF[dists[[i]], x], {x, -3, 3}, PlotRange -> All, PlotLabel -> kernels[[i]], Filling -> Axis, Ticks -> None], {i, Length[kernels]}]Specify any one of several kernel functions for multivariate data:
data = RandomVariate[BinormalDistribution[.75], 100];Table[Plot3D[PDF[ KernelMixtureDistribution[data, Automatic, i], {x, y}]//Evaluate, {x, -4, 4}, {y, -4, 4}, Ticks -> None, PlotLabel -> i, Exclusions -> None, PlotRange -> All, MeshFunctions -> (#3&)], {i, {"Biweight", "Cosine", "Epanechnikov", "Gaussian", "Rectangular", "SemiCircle", "Triangular", "Triweight"}}]Shapes of some bivariate product kernels:
kernels = {"Gaussian", "Epanechnikov", "Biweight", "Triweight", "Cosine", "Triangular", "SemiCircle", "Custom"};dists = Table[KernelMixtureDistribution[{{0, 0}}, Automatic, i], {i, (kernels /. {"Custom" -> (PDF[CauchyDistribution[0, 1], #]&)})}];Table[Plot3D[PDF[dists[[i]], {x, y}]//Evaluate, {x, -2, 2}, {y, -2, 2}, PlotRange -> All, Exclusions -> None, PlotPoints -> 35, PlotLabel -> kernels[[i]], Filling -> Axis, Ticks -> None, Mesh -> None], {i, Length[kernels]}]Choose between product- and radial-type kernel functions for multivariate data:
data = {{0, 0}};kerns = {{"Product", "Biweight"}, {"Radial", "Biweight"}};Table[Plot3D[PDF[ KernelMixtureDistribution[data, 1, i], {x, y}]//Evaluate, {x, -1.5, 1.5}, {y, -1.5, 1.5}, Ticks -> None, PlotLabel -> i, Exclusions -> None, PlotRange -> All, PlotPoints -> 100, MeshFunctions -> (#3 &), Boxed -> False], {i, kerns}]Computation of a single biweight kernel in two dimensions:
biweight = ProbabilityDistribution[(15/16) (1 - x^2)^2, {x, -1, 1}];product[h_] := PDF[ProductDistribution[biweight, biweight], MatrixPower[h, -(1/2)].{x, y}] / Sqrt[Det[h]]ContourPlot[product[IdentityMatrix[2]]//Evaluate, {x, -1.5, 1.5}, {y, -1.5, 1.5}, PlotRange -> All]radial[h_] := PDF[biweight, Norm[MatrixPower[h, -(1/2)].{x, y}]] / (Sqrt[Det[h]])ContourPlot[radial[IdentityMatrix[2]]//Evaluate, {x, -1.5, 1.5}, {y, -1.5, 1.5}, PlotRange -> All]Bandwidths have similar effects for both radial- and product-type kernels:
kernel = PDF[LaplaceDistribution[0, 1], #]&;compare[bw_] := Table[Plot3D[PDF[KernelMixtureDistribution[{{0, 0}}, bw, k], {x, y}]//Evaluate, {x, -3, 3}, {y, -3, 3}, PlotRange -> All, PlotPoints -> 50, MeshFunctions -> (#3&), Axes -> False, PlotLabel -> Row[{k[[1]], ": ", bw}]], {k, {{"Product", kernel}, {"Radial", kernel}}}]bw = {.95 IdentityMatrix[2], DiagonalMatrix[{.95, .5}], {{.95, .5}, {.5, .95}}};Scalar bandwidths stretch the kernel equally in each dimension:
compare[bw[[1]]]Diagonal elements stretch the kernel independently along each axis:
compare[bw[[2]]]Nonzero off-diagonal elements change the orientation:
compare[bw[[3]]]The PDFs of the various kernel functions:
epanechnikov = (3 (5 - x^2) Boole[Abs[x] < Sqrt[5]]/20 Sqrt[5]);
biweight = (15/16) (1 - x^2)^2 Boole[Abs[x] < 1];
triweight = (35/32) (1 - x^2)^3 Boole[Abs[x] < 1];
cosine = (1/4) π Boole[Abs[x] < 1] Cos[(π x/2)];
semicircle = Piecewise[{{(2*Sqrt[1 - x^2])/Pi, -1 < x < 1}}, 0];
gaussian = (E^-(x^2/2)/Sqrt[2 π]);
rectangular = Piecewise[{{1/2, -1 <= x <= 1}}, 0];
triangular = Piecewise[{{1 + x, -1 <= x <= 0}, {1 - x, Inequality[0, Less, x, LessEqual, 1]}}, 0];The efficiency of kernels under the assumption of normally distributed data:
eff[kernel_] := (3/ 5 Sqrt[5])(Subsuperscript[∫, -∞, ∞]x^2 kernelⅆx)^-1 / 2(Subsuperscript[∫, -∞, ∞]kernel^2ⅆx)^-1.The built-in kernel functions all have relatively high statistical efficiency:
Table[{kern, eff[ToExpression[kern]]}, {kern, {"epanechnikov", "biweight", "triweight", "cosine", "semicircle", "gaussian", "rectangular", "triangular"}}]//TableFormOptions (7)
MaxMixtureKernels (7)
By default, a kernel is placed at each data point for sample sizes less than 300:
data = RandomVariate[NormalDistribution[1, 2], 20];𝒟 = KernelMixtureDistribution[data, MaxMixtureKernels -> Automatic];Plot[PDF[𝒟, x]//Evaluate, {x, -10, 10}, PlotRange -> All]For larger sample sizes, a maximum of 300 uniformly spaced kernels is used by default:
data = RandomVariate[NormalDistribution[], 10 ^ 4];dist = KernelMixtureDistribution[data, MaxMixtureKernels -> Automatic];Plot[PDF[dist, x]//Evaluate, {x, -4, 4}, PlotRange -> All]//QuietSpecify the maximum number of kernels to use in the estimate:
data = RandomVariate[NormalDistribution[], 15];dist = KernelMixtureDistribution[data, MaxMixtureKernels -> 5];Plot[PDF[dist, x], {x, -4, 4}, Filling -> Axis]A larger number of kernels gives a better estimate of the underlying distribution:
data = RandomVariate[NormalDistribution[], 10 ^ 4];estimates = Table[KernelMixtureDistribution[data, MaxMixtureKernels -> i], {i, {10, 15, 25, 100}}];Table[Plot[{PDF[i, x], PDF[NormalDistribution[], x]}, {x, -4, 4}, Filling -> Axis, PlotRange -> All], {i, estimates}]Place a kernel at each data point:
data = {-2, 0, 2};𝒟 = KernelMixtureDistribution[data, .25, MaxMixtureKernels -> All];Plot[PDF[𝒟, x], {x, -4, 4}, Filling -> Axis, Frame -> True, PlotRange -> All]Vary the bandwidth used for the same number of kernels:
Table[Plot[PDF[KernelMixtureDistribution[data, bw, MaxMixtureKernels -> All], x]//Evaluate, {x, -4, 4}, Filling -> Axis, PlotRange -> {0, .6}, PlotLabel -> Row[{"bandwidth = ", bw}]], {bw, {0.25, 0.5, 0.75, 1.0}}]Specify the number of kernels to use in each dimension for bivariate data:
data = RandomVariate[BinormalDistribution[.8], 200];Place at most 10 and 100 kernels, respectively:
estimates = Table[KernelMixtureDistribution[data, .15, MaxMixtureKernels -> i], {i, {10, 100}}];Table[DensityPlot[Evaluate[PDF[i, {x, y}]], {x, -4, 4}, {y, -4, 4}, PlotPoints -> 80, PlotRange -> All, ColorFunction -> "TemperatureMap"], {i, estimates}]//QuietSet a different maximum number of kernels in each dimension:
data = RandomVariate[BinormalDistribution[.8], 1000];Specify a maximum of 5 and 50 kernels, or 50 and 5:
estimates = Table[KernelMixtureDistribution[data, MaxMixtureKernels -> i], {i, {{5, 50}, {50, 5}}}];Table[Plot3D[PDF[i, {x, y}]//Evaluate, {x, -4, 4}, {y, -4, 4}, PlotPoints -> 50, PlotRange -> All], {i, estimates}]//QuietApplications (6)
Compare an estimated density to a theoretical model:
𝒹 = MixtureDistribution[Join[{1 / 2}, Table[(2 ^ (1 - i)) / 31, {i, -2, 2}]], Join[{NormalDistribution[]}, Table[NormalDistribution[i + 1 / 2, (2 ^ -i) / 10], {i, -2, 2}]]];data = RandomVariate[𝒹, 10 ^ 5];Use an adaptive bandwidth and many mixture kernels when high resolution is desired:
𝒟 = KernelMixtureDistribution[data, {"Adaptive", Automatic, .25}, MaxMixtureKernels -> 500];Plot[{PDF[𝒹, x], PDF[𝒟, x]}//Evaluate, {x, -4, 4}, Filling -> {1 -> 0}, PlotLegends -> {"𝒹", "𝒟"}]//QuietThe moments for the model and the estimate are similar:
{Mean[𝒹], Variance[𝒹], Skewness[𝒹], Kurtosis[𝒹]}//N{Mean[𝒟], Variance[𝒟], Skewness[𝒟], Kurtosis[𝒟]}//NEstimate the distribution of daily point changes for Apple stocks on the NASDAQ:
nasdaq = FinancialData["NASDAQ:AAPL", All, "Value"];
data = Log[Ratios[nasdaq]];𝒟 = KernelMixtureDistribution[data, MaxMixtureKernels -> 3000];Increase the MaxMixtureKernels option with heavy-tailed data for a smoother estimate:
Plot[PDF[𝒟, x]//Evaluate, {x, -.2, .2}, PlotRange -> All]//QuietCompute the probability of a 10% point change or more on a given day:
Probability[x ≥ Log[1.1], x𝒟]Estimate the distribution of snowfall in Buffalo, New York:
ExampleData[{"Statistics", "BuffaloSnow"}, "Description"]snow = QuantityArray[ExampleData[{"Statistics", "BuffaloSnow"}], "Inches"];Subscript[𝒟, BSnow] = KernelMixtureDistribution[snow];Plot[PDF[Subscript[𝒟, BSnow], Quantity[x, "Inches"]]//Evaluate, {x, 0, 150}, Filling -> Axis, AxesLabel -> {"in"}]Different bandwidths yield different descriptions of the snowfall distribution:
Table[Plot[PDF[KernelMixtureDistribution[snow, bw], Quantity[x, "Inches"]]//Evaluate, {x, 10, 150}, PlotRange -> {0, .025}, Filling -> Axis, Ticks -> {{0, 50, 100, 150}}, AxesLabel -> {"in"}, PlotLabel -> Row[{"Bandwidth: ", bw}]], {bw, Quantity[{4, 8, 12, 20}, "Inches"]}]Identify which of six measures might be most useful for identifying counterfeit bank notes:
sbn = ExampleData[{"Statistics", "SwissBankNotes"}];ExampleData[{"Statistics", "SwissBankNotes"}, "ColumnDescriptions"]c = QuantityArray[Transpose[Pick[sbn[[All, 1 ;; -2]], sbn[[All, -1]], 1]], "Milimeters"];
nc = QuantityArray[Transpose[Pick[sbn[[All, 1 ;; -2]], sbn[[All, -1]], 0]], "Milimeters"];Subscript[𝒟, c] = Table[KernelMixtureDistribution[i], {i, c}];
Subscript[𝒟, nc] = Table[KernelMixtureDistribution[i], {i, nc}];Measure 6 appears to best separate the two classes of notes:
Table[Plot[{PDF[Subscript[𝒟, c][[i]], Quantity[x, "Millimeters"]], PDF[Subscript[𝒟, nc][[i]], Quantity[x, "Millimeters"]]}//Evaluate, {x, Min[QuantityMagnitude[{c[[i]], nc[[i]]}]], Max[QuantityMagnitude[{c[[i]], nc[[i]]}]]}, Filling -> Axis, PlotLabel -> Row[{"Measure ", i}], ImageSize -> 150, PlotRange -> All], {i, Length[c]}]Using measure 6 as a classifier with a cutoff of 140.5 mm, find the probability of misclassification:
cutoff = Quantity[140.5, "Millimeters"];Probability[x ≤ cutoff, xSubscript[𝒟, nc][[6]]] + Probability[x ≥ cutoff, xSubscript[𝒟, c][[6]]]Find the bandwidth that minimizes the mean squared error (MSE) of the PDF:
data = RandomVariate[𝒹 = NormalDistribution[], n = 45];𝒟 = KernelMixtureDistribution[data, h];Plot[(fn = Total[((PDF[𝒟, #] - PDF[𝒹, #])^2/n)& /@ data]), {h, .01, 6}, PlotRange -> {0, .1}]minMSE = FindMinimum[fn, h]Use the bandwidth to estimate the PDF:
Plot[Evaluate[PDF[KernelMixtureDistribution[data, h /. Last[minMSE]], x]], {x, -5, 5}]KernelMixtureDistribution can be used to create an elliptical distribution. Elliptical distributions are a generalization of multivariate normal distributions:
ellipticalDistribution[marginal_, μ_, Σ_ ? SymmetricMatrixQ] /; PositiveDefiniteMatrixQ[Σ] && Length[μ] == Length[Σ] := KernelMixtureDistribution[{μ}, MatrixPower[Σ, 1 / 2], {"Radial", PDF[marginal, #]&}]Σ = {{1, 1 / 2}, {1 / 2, 1}};
μ = {0, 0};Using NormalDistribution[0,1] for the marginal gives MultinormalDistribution[μ,Σ]:
𝒟MN = ellipticalDistribution[NormalDistribution[], μ, Σ]MomentGeneratingFunction[𝒟MN, {t1, t2}]MomentGeneratingFunction[MultinormalDistribution[{0, 0}, {{1, 1 / 2}, {1 / 2, 1}}], {t1, t2}]//FullSimplifySome other elliptical distributions:
𝒟L = ellipticalDistribution[LaplaceDistribution[0, 1], μ, Σ];Plot3D[Evaluate@PDF[𝒟L, {x, y}], {x, -4, 4}, {y, -4, 4}, PlotRange -> All, PlotPoints -> 35, Mesh -> None]𝒟T = ellipticalDistribution[StudentTDistribution[3], μ, Σ];Plot3D[Evaluate@PDF[𝒟T, {x, y}], {x, -4, 4}, {y, -4, 4}, PlotRange -> All, PlotPoints -> 35, Mesh -> None]Properties & Relations (9)
The resulting density estimate integrates to unity:
data = RandomVariate[NormalDistribution[], 100];dist = KernelMixtureDistribution[data];NIntegrate[PDF[dist, x], {x, -∞, ∞}]The density is a weighted sum of kernel functions:
data = Range[-2, 2];dist = KernelMixtureDistribution[data, h, 𝒦[#]&, MaxMixtureKernels -> All];PDF[dist, x]//ExpandKernelMixtureDistribution is a consistent estimator of the underlying distribution:
data = Table[RandomVariate[NormalDistribution[], 10^i], {i, Range[4]}];𝒟l = Table[KernelMixtureDistribution[i], {i, data}];Table[Plot[{PDF[𝒟l[[i]], x], PDF[NormalDistribution[], x]}, {x, -5, 5}, PlotRange -> All, Axes -> {True, False}, PlotLabel -> Row[{"n=", Superscript[10, i]}]], {i, Range[4]}]The number of kernels actually used will be no larger than the sample size:
data = Table[RandomVariate[NormalDistribution[], j], {j, {3, 5, 10, 25, 50, 100, 150, 250}}];Placing at most 10000 kernels:
dists = Table[KernelMixtureDistribution[i, MaxMixtureKernels -> 10000], {i, data}];The number of terms corresponds to the number of kernels used:
Table[Length[PDF[i, x]], {i, dists}]As the bandwidth approaches infinity, the estimate approaches the shape of the kernel:
data = {-.5, 0, .5};𝒦 = {"Gaussian", "Epanechnikov", "Biweight", "Triweight", "Rectangular", "Triangular", "Cosine", "SemiCircle"};Table[Plot[Evaluate@PDF[KernelMixtureDistribution[data, {"Standardized", 200}, i], x], {x, -250, 250}, PlotRange -> All, Exclusions -> None, Ticks -> None, PlotLabel -> i], {i, 𝒦}]A linear interpolation of KernelMixtureDistribution is SmoothKernelDistribution:
data = {-1.5, -1.0, -.2, -.1, 0., 1.5};fn = PDF[KernelMixtureDistribution[data], #]&;pts = fn /@ Range[-4, 4, .1];{ListLinePlot[Transpose[{Range[-4, 4, .1], pts}]], Plot[Evaluate@PDF[SmoothKernelDistribution[data], x], {x, -4, 4}]}KernelMixtureDistribution results in a MixtureDistribution of kernels:
data = Range[5];𝒟 = KernelMixtureDistribution[data, h = 1, "Gaussian", MaxMixtureKernels -> All];PDF[𝒟, x]//SimplifyPDF[MixtureDistribution[ConstantArray[h, Length[data]], Table[NormalDistribution[i, h], {i, data}]], x]//Simplify% == %%KernelMixtureDistribution works with the values only when the input is a TimeSeries or an EventSeries:
ts = TemporalData[TimeSeries, {{{1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0,
1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1}}, {{0, 99, 1}}, 1, {"Continuous", 1}, {"Discrete", 1}, 1,
{ResamplingMethod -> {"Interpolation", InterpolationOrder -> 1}}}, False, 10.1];KernelMixtureDistribution[ts]KernelMixtureDistribution[ts["Values"]]% == %%KernelMixtureDistribution works with all the values together when the input is a TemporalData:
td = TemporalData[«4»];KernelMixtureDistribution[td]KernelMixtureDistribution[td["ValueList"]//Flatten]%% == %Possible Issues (5)
The kernel function needs to be a PDF:
data = {-1.5, -1.0, -.2, -.1, 0., 1.5};𝒟 = KernelMixtureDistribution[data, Automatic, Cos[#]&];The resulting density estimate is not a PDF:
Plot[PDF[𝒟, x], {x, -4, 4}, Filling -> Axis]Automatic adaptive bandwidths may be too small with large samples:
data = RandomVariate[NormalDistribution[], 10 ^ 6];𝒟1 = KernelMixtureDistribution[data, {"Adaptive", Automatic, 1}];Plot[PDF[𝒟1, x]//Evaluate, {x, -4, 4}, PlotRange -> All]//QuietTry increasing the initial bandwidth, MaxMixtureKernels, or decreasing the sensitivity:
𝒟2 = KernelMixtureDistribution[data, {"Adaptive", 1.5, 1}];Plot[PDF[𝒟2, x]//Evaluate, {x, -4, 4}, PlotRange -> All]//QuietA kernel must be placed at each data point with symbolic data:
data = Array[x, 10];𝒟 = KernelMixtureDistribution[data, MaxMixtureKernels -> 5]Set MaxMixtureKernels to All or Automatic:
𝒟 = KernelMixtureDistribution[data, MaxMixtureKernels -> Automatic]PDF[𝒟, x]//ExpandSymbolic data cannot be used with the "SheatherJones" and "LeastSquaresCrossValidation" methods:
data = Array[x, 3]KernelMixtureDistribution[data, "SheatherJones"]Specify bandwidths that do not require estimation:
validBWs = {"Silverman", Automatic, h, {"Adaptive", h, 1 / 2}, {"Standardized", 1}, .3};Table[Head[KernelMixtureDistribution[data, i]], {i, validBWs}]Some of the kernel functions are bounded and trigger exclusions in plots:
data = RandomVariate[NormalDistribution[], 1000];𝒟 = KernelMixtureDistribution[data, Automatic, "Biweight"];Set the Exclusions option to None to avoid spurious gaps and to decrease plot timings:
{Timing[Plot[PDF[𝒟, x], {x, -4, 4}]], Timing[Plot[PDF[𝒟, x], {x, -4, 4}, Exclusions -> None]]}Neat Examples (2)
Use KernelMixtureDistribution to apply a Gaussian blur to a binarized image:
img = Binarize[Import["ExampleData/spikey.tiff"]]data = Position[Reverse /@ Transpose@ImageData[img], 1];dist = KernelMixtureDistribution[N@data, {2, 2}];DensityPlot[Evaluate@PDF[dist, {x, y}], {x, 0, 120}, {y, 0, 120}, Evaluated -> True, PlotRange -> All, PlotPoints -> 100, ColorFunction -> "SolarColors", Frame -> False]//QuietCompute a completely symbolic trivariate density estimate:
data = Flatten[Table[Subscript[t, Sequence@@{i, j, k}], {i, 3}, {j, 3}, {k, 3}], 1]dist = KernelMixtureDistribution[data, {Subscript[h, 1], Subscript[h, 2], Subscript[h, 3]}, k[#]&];PDF[dist, {x, y, z}]//TraditionalFormText
Wolfram Research (2010), KernelMixtureDistribution, Wolfram Language function, https://reference.wolfram.com/language/ref/KernelMixtureDistribution.html (updated 2016).
CMS
Wolfram Language. 2010. "KernelMixtureDistribution." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2016. https://reference.wolfram.com/language/ref/KernelMixtureDistribution.html.
APA
Wolfram Language. (2010). KernelMixtureDistribution. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/KernelMixtureDistribution.html