

SpeechRecognize
SpeechRecognize[audio]
recognizes speech in audio and returns it as a string.
SpeechRecognize[audio,level]
returns a list of strings at the specified structural level.
SpeechRecognize[audio,level,prop]
returns prop for text at the given level.
Details and Options
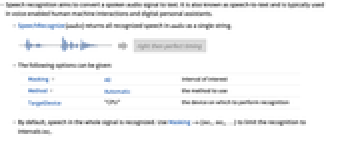


- Speech recognition aims to convert a spoken audio signal to text. It is also known as speech-to-text and is typically used in voice-enabled human-machine interactions and digital personal assistants.
- SpeechRecognize[audio] returns all recognized speech in audio as a single string.
- Structural elements specified in level include:
-
Automatic speech found in the whole audio signal (default) "Segment" a list of transcription segments "Sentence" a list of sentences "Word" a list of words - The property prop can be one of the following:
-
"Audio" trimmed audio containing the recognized text "Confidence" strength of the recognized text "Interval" interval containing the text "SubtitleRules" a list of time intervals and texts "Text" recognized text (default) {prop1,prop2,…} a list of properties - The following options can be given:
-
Language Automatic the language to recognize Masking All interval of interest Method Automatic the method to use PerformanceGoal $PerformanceGoal aspects of performance to try to optimize ProgressReporting $ProgressReporting whether to report the progress of the computation TargetDevice "CPU" the device on which to perform recognition - Use Languagelang1lang2 to recognize speech assumed to be in language lang1 and return translated text in language lang2.
- By default, speech in the whole signal is recognized. Use Masking->{int1,int2,…} to limit the recognition to intervals inti.
- Possible settings for Method are:
-
Automatic automatic method "GoogleSpeech" uses Google speech-to-text "NeuralNetwork" uses built-in neural networks "OpenAI" uses OpenAI speech-to-text - By default, if a method returns non-speech tokens (e.g. [applause]), they are returned in the result. Use Method{method,"NonSpeechReplacement"replacements} to specify different replacements. Use "NonSpeechReplacement""" to remove them.
- SpeechRecognize works for English speech as well as various other languages, such as Chinese, Dutch, French, Japanese and Spanish.
- SpeechRecognize uses machine learning. Its methods, training sets and biases included therein may change and yield varied results in different versions of the Wolfram Language.
- SpeechRecognize may download resources that will be stored in your local object store at $LocalBase, and can be listed using LocalObjects[] and removed using ResourceRemove.
Examples
open all close allScope (4)
Basic Uses (2)
Level Specification (1)
Options (3)
Masking (1)
Use the Masking option to recognize parts of a signal:
Method (1)
Applications (4)
Use AudioIntervals to select which parts of the signal to recognize:
Show the recognized city on the map:
Text
Wolfram Research (2019), SpeechRecognize, Wolfram Language function, https://reference.wolfram.com/language/ref/SpeechRecognize.html (updated 2024).
CMS
Wolfram Language. 2019. "SpeechRecognize." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2024. https://reference.wolfram.com/language/ref/SpeechRecognize.html.
APA
Wolfram Language. (2019). SpeechRecognize. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/SpeechRecognize.html