

VarianceTest
VarianceTest[data]
data の分散が1つであるかどうかの検定を行う.
VarianceTest[{data1,data2}]
data1と data2の分散が等しいかどうかの検定を行う.
VarianceTest[dspec,σ02]
σ02に対する分散量度の検定を行う.
VarianceTest[dspec,σ02,"property"]
"property"の値を返す.
詳細とオプション




- VarianceTestは,帰無仮説
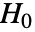 と対立仮説
と対立仮説 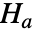 で検定を行う.
で検定を行う. -
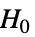
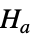
data 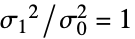
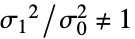
{data1,data2} 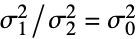
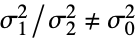
- ただし,σi2は dataiの母分散である.
- デフォルトで,確率値すなわち
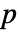 値が返される.
値が返される. 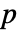 値が小さければ
値が小さければ 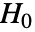 が真である可能性は低い.
が真である可能性は低い.- dspec 中の data は一変量{x1,x2,…}でなければならない.
- 引数
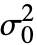 は任意の正の実数でよい.
は任意の正の実数でよい. - VarianceTest[dspec,
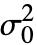 ]は dspec に適用可能な中で最も強力な検定を選ぶ.
]は dspec に適用可能な中で最も強力な検定を選ぶ. - VarianceTest[dspec,
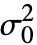 ,All]は dspec に適用可能なすべての検定を選ぶ.
,All]は dspec に適用可能なすべての検定を選ぶ. - VarianceTest[dspec,
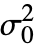 ,"test"]は"test"に従って
,"test"]は"test"に従って 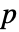 値をレポートする.
値をレポートする. - ほとんどの検定には正規分布に従うデータが必要である.ある検定が正規性の仮説についてそれほど敏感ではない場合,その検定は強力であると呼ばれる.データが中央値について対称であると仮定する検定もある.
- 使用可能な検定
-
"BrownForsythe" ロバスト 強力なLevene検定 "Conover" 対称性 data の順位の平方に基づく "FisherRatio" 正規性 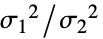 に基づく
に基づく"Levene" ロバスト,対称性 個々の分散と集合の分散を比較する "SiegelTukey" 対称性 集められた data の順位に基づく - VarianceTest[data,
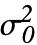 ,"HypothesisTestData"]はHypothesisTestDataオブジェクト htd を返す.htd["property"]を使うと追加的な検定結果と特性が抽出できる.
,"HypothesisTestData"]はHypothesisTestDataオブジェクト htd を返す.htd["property"]を使うと追加的な検定結果と特性が抽出できる. - VarianceTest[data,
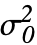 ,"property"]は"property"の値を直接与えるために使うことができる.
,"property"]は"property"の値を直接与えるために使うことができる. - 検定結果のレポートに関連する特性
-
"AllTests" 適用可能な検定すべてのリスト "AutomaticTest" Automaticが使われた場合に選ばれる検定 "DegreesOfFreedom" 検定で使われる自由度 "PValue" 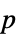 値のリスト
値のリスト"PValueTable" 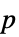 値のフォーマットされた表
値のフォーマットされた表"ShortTestConclusion" 検定結果の短い説明 "TestConclusion" 検定結果の説明 "TestData" 検定統計と 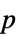 値のペアのリスト
値のペアのリスト"TestDataTable" 検定統計と 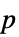 値のフォーマットされた表
値のフォーマットされた表"TestStatistic" 検定統計のリスト "TestStatisticTable" 検定統計のフォーマットされた表 - 使用可能なオプション
-
AlternativeHypothesis "Unequal" 対立仮説のための不等式 SignificanceLevel 0.05 診断とレポートのための切捨て VerifyTestAssumptions Automatic 実行する診断検定を設定する - 分散の検定では,
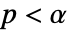 の場合にのみ
の場合にのみ 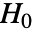 が棄却されるように切捨て
が棄却されるように切捨て 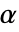 が選ばれる."TestConclusion"特性と"ShortTestConclusion"特性に使われる
が選ばれる."TestConclusion"特性と"ShortTestConclusion"特性に使われる 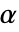 の値はSignificanceLevelオプションで制御される.この値
の値はSignificanceLevelオプションで制御される.この値 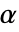 は正規性診断や対称性診断を含む仮定の診断検定にも用いられる.デフォルトで
は正規性診断や対称性診断を含む仮定の診断検定にも用いられる.デフォルトで 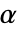 は0.05に設定されている.
は0.05に設定されている. - VarianceTestにおけるVerifyTestAssumptionsの名前付き設定
-
"Normality" すべてのデータが正規分布に従うことを証明する "Symmetry" 共通の中央値について対称性を証明する
例題
すべて開く すべて閉じる例 (3)
さらに特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
スコープ (15)
検定 (11)
Automaticを使うと,一般に最も強力で適切な検定が適用される:
特性"AutomaticTest"は,どの検定が選ばれたのかを調べるのに使える:
特性"AllTests"を使ってどの検定が使われたのかを調べる:
繰り返し特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
HypothesisTestDataオブジェクトから特性をいくつか抽出する:
オプション (10)
AlternativeHypothesis (3)
SignificanceLevel (3)
アプリケーション (2)
特性と関係 (7)
検定のサイズを0.05に設定すると,5%の割合で ![]() が誤って退けられる結果になる:
が誤って退けられる結果になる:
6つの異なるレベルにおける検定の力.Siegel–Tukey検定が最も低い力を持つ:
Brown–Forsythe検定とルベーン(Levene)検定は1つのサンプルについてフィッシャー(Fisher)の比率検定に等しい:
分散検定は,入力がTimeSeriesのときにのみ値に使うことができる:
分散検定は,入力がTemporalDataのときはすべての値に同時に使うことができる:
考えられる問題 (2)

テキスト
Wolfram Research (2010), VarianceTest, Wolfram言語関数, https://reference.wolfram.com/language/ref/VarianceTest.html.
CMS
Wolfram Language. 2010. "VarianceTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/VarianceTest.html.
APA
Wolfram Language. (2010). VarianceTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/VarianceTest.html