TSV (.tsv)
- ImportとExportはTSV形式を完全にサポートし,種々のデータ変換と形式オプションを提供する.
- ImportはCやFortranの表記法を含む一般的な数の形式を自動的に認識する.
- 小数点のない数は整数としてインポートされる.
予備知識
-
- MIMEタイプ:text/tab-separated-values
- TSV表データ形式.
- フィールドの区切り文字としてタブを使用して,数値,テキスト情報の記録を行として保管する.
- TSVはTab-Separated Valuesの頭字語である.
- テキスト形式.
- CSVに類似する.
ImportとExport
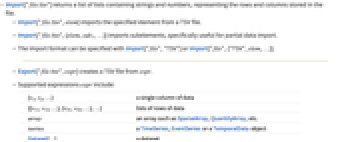
- Import["file.tsv"]は,ファイルに保管された行と列を表す文字列と数を含むリストのリストを返す.
- Import["file.tsv",elem]はTSVファイルから指定の要素をインポートする.
- Import["file.tsv",{elem,sub1,…}]はサブ要素をインポートし,部分的なデータのインポートに特に便利である.
- インポート形式はImport["file","TSV"]またはImport["file",{"TSV",elem,…}]で指定できる.
- Export["file.tsv",expr]は expr からTSVファイルを作成する.
- サポートされている式 expr:
-
{v1,v2,…} 1列のデータ {{v11,v12,…},{v21,v22,…},…} データの行のリスト array SparseArray,QuantityArray等の配列 tseries TimeSeries,EventSeries,TemporalDataオブジェクト Dataset[…] データ集合 Tabular[…] 表形式オブジェクト - 一般的な情報は,以下の関数ページを参照のこと.
-
Import, Export ファイルからインポートする,あるいはファイルへエキスポートする CloudImport, CloudExport クラウドオブジェクトからインポートする,あるいはクラウドオブジェクトへエキスポートする ImportString, ExportString 文字列からインポートする,あるいは文字列へエキスポートする ImportByteArray, ExportByteArray バイト配列からインポートする,あるいはバイト配列へエキスポートする
Import要素


- 一般的なImport要素:
-
"Elements" ファイル中の有効な要素とオプションのリスト "Rules" 使用可能なすべての要素の規則のリスト "Summary" ファイルの概要 - データ表現要素:
-
"Data" 二次元配列 "Grid" Gridオブジェクトで表された表データ "RawData" 文字列の二次元配列 "Dataset" Datasetで表された表データ "Tabular" Tabularオブジェクトで表された表形式データ - データ表現要素:
-
"ColumnLabels" 列の名前 "ColumnTypes" 列の名前と型の連想 "Schema" TabularSchemaオブジェクト - ImportとExportはデフォルトで"Data"要素を使用する.
- 任意の要素 elem に対して,データを部分的にインポートするためのサブ要素は,{elem, rows, cols}という形式で行と列の指定を取ることができる.ここで rows と cols は以下のいずれでもよい:
-
n n 番目の行または列 -n 最後から数える n;;m n から m まで n;;m;;s n から m までステップ s で {n1,n2,…} 特定の行または列 ni - メタデータ要素:
-
"ColumnCount" 列の数 "Dimensions" 行数と最大列数のリスト "RowCount" 行の数
オプション




- ImportとExportのオプション:
-
"EmptyField" "" 空のフィールドの表現方法 "QuotingCharacter" "\"" 数値でないフィールドの区切りに使われる文字 - コンマと行区切りを含むデータフィールドは通常ダウブルクォート文字でラップされる.デフォルトではExportは区切り文字としてダブルクォート文字を使用する.別の文字は"QuotingCharacter"を使って指定できる.
- テキストフィールドを区切るダブルクォート文字はデフォルトではインポートされない.
- Importオプション:
-
CharacterEncoding "UTF8ISOLatin1" ファイルで使用される生の文字コード "ColumnTypeDetectionDepth" Automatic 見出し検出のために使用される行数 "CurrencyTokens" None 数値的な値をインポートする際に省く通貨単位 "DateStringFormat" None DateString指定で与えられた日付の形式 "FieldSeparator" "\t" 列を分割するために取られる文字列トークン "FillRows" Automatic 行を列の最大長まで埋めるかどうか "HeaderLines" Automatic 見出しであると仮定する行の数 "IgnoreEmptyLines" False 空白行を無視するかどうか MissingValuePattern Automatic 欠落している要素を指定するために使用するパターン "NumberPoint" "." 小数点の文字列 "Numeric" Automatic 可能な場合にデータフィールドを数としてインポートするかどうか "Schema" Automatic Tabular オブジェクトを構築するために使われるスキーマ "SkipInvalidLines" False 無効な行を省くかどうか "SkipLines" Automatic ファイルの最初の省く行数 - デフォルトでは,Importはデータが"UTF8"で符号化されたテキストであるとして解釈を試みる.ファイルに保存されたバイト列で"UTF8"で表せないものがある場合は,Importは代りに"ISOLatin1"を使用する.
- CharacterEncoding -> Automaticとすると,Importはファイルの文字コードの推測を試みる.
- "HeaderLines"と"SkipLines"は以下の設定が可能である:
-
Automatic 省略する行数または見出しとして使用する行数を自動的に決定しようとする n 省略またはDataset見出しとして使用する n 行 {rows,cols} 省略または見出しとして使用する行と列 - Importは"DateStringFormat"の指定に従ってフォーマットされた表の項目をDateObjectに変換する.
- Exportオプション:
-
Alignment None 表の列にデータがどのように並んでいるか CharacterEncoding "UTF8" ファイルで使用される生の文字コード "FillRows" False 行を列の最大長まで埋めるかどうか "IncludeQuotingCharacter" Automatic エキスポートした値を囲む引用符を追加するかどうか "TableHeadings" Automatic 表の行と列の見出し - Alignmentが取り得る設定はNone,Left,Center,Rightである.
- "IncludeQuotingCharacter"は以下の値に設定することができる:
-
None 値を引用符で囲まない Automatic 必要な場合にのみ値を引用符で囲む All 有効な値はすべて引用符で囲む - "TableHeadings"は以下の値を取ることができる:
-
None 列ラベルを省略する Automatic 列ラベルをエキスポートする {"col1","col2",…} 列ラベルのリスト {rhead,chead} 行と列に別々のラベルを指定する - Exportは,Wolframシステムが実行されているコンピュータシステムに従って行区切り文字を符号化する.
例題
すべて開くすべて閉じるスコープ (8)
Import (4)
見出しを自動で検出する Tabular オブジェクトとしてTSVファイルをインポートする:
Export (4)
Tabularオブジェクトをエキスポートする:
"TableHeadings"オプションを使って,Tabular オブジェクトから見出しを削除する:
TimeSeriesをエキスポートする:
EventSeriesをエキスポートする:
QuantityArrayをエキスポートする:
Import要素 (26)
"Data" (6)
"Dataset" (3)
"Grid" (1)
TSVデータをGridとしてインポートする:
"RawData" (3)
"Schema" (1)
TabularSchemaオブジェクトを取得する:
"Tabular" (6)
TabularオブジェクトとしてCSVファイルをインポートする:
Importオプション (15)
CharacterEncoding (1)
文字コードは$CharacterEncodingsの任意の値に設定できる:
"DateStringFormat" (1)
指定の日付形式を使って日付をDateObjectに変換する:
"HeaderLines" (1)
MissingValuePattern (1)
"Numeric" (1)
数を解釈するために"Numeric"->Trueを使用する:
"Schema" (1)
Import はTSVファイルに保存されたデータから列ラベルとタイプを自動的に推測する:
"SkipLines" (1)
Exportオプション (7)
CharacterEncoding (1)
文字コードは$CharacterEncodingsの任意の値に設定できる:
"IncludeQuotingCharacter" (1)
"QuotingCharacter" (1)
"TableHeadings" (1)
"TableHeadings"Noneを使って列の見出しを省略する:
考えられる問題 (12)
ファイル内のすべての行が同じ列数を持たない場合,いくつかの行は無効と考えられる:
"nnnDnnn"または"nnnEnnn"といった形式の項目は科学表記の数として解釈される:
"Numeric"オプションを使用して解釈をオーバーライドする:
"Numeric" オプションを使って,この解釈をオーバーライドする:
バージョン14.2からは,通貨のトークンが自動的には省略されない.
"CurencyTokens"オプションを使うと通貨のトークンが省略できる:
バージョン14.2からは,整数値の行にDeveloper`$MaxMachineIntegerより大きい数が含まれるときは引用符のついた文字が追加される:
"IncludeQuotingCharacter"->Noneを使うと,以前と同じ結果を得ることができる:
バージョン14.2からは,一部の文字列は自動的に空白とみなされる:
MissingValuePatternNone を使うと,この解釈はオーバーライドできる:
バージョン14.2からは,小数部分が0の実数は整数としてエキスポートされる:
"Backend"->"Table"を使うと以前と同じ結果が得られる:
バージョン14.2からは,Developer`$MaxMachineIntegerより大きい整数は実数としてインポートされる:
"Backend"->"Table"を使うと以前と同じ結果が得られる:
バージョン14.2からは,Tabularオブジェクトの日付と時間の行はDateStringを使ってエキスポートされる:
"Backend"->"Table" を使うと,以前と同じ結果を得られる:
Wolfram言語の古いバージョンから生成された一部のTSVデータでは,テキストフィールドが誤って区切られている可能性があり,バージョン11.2以降では期待どおりにインポートされない:
"QuotingCharacter""" を使うと事前に予想された結果を与えられる:
データの左上の角は,行と列の見出しを含むDatasetをインポートする際に失われる:
データの次元によってDatasetが異なる形になることもある: