"KernelDensityEstimation" (机器学习方法)
"KernelDensityEstimation" (机器学习方法)
- LearnDistribution 的方法.
- 模拟带有混合简单分布的概率密度.
Details & Suboptions
- "KernelDensityEstimation" 是一种非参数方法,它使用以每个训练示例为中心的简单分布(称为内核)的混合来模拟数值空间的概率密度,如在 KernelMixtureDistribution 中的一样.
- 向量
 的概率密度函数为:
的概率密度函数为: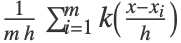 ,其中,内核函数
,其中,内核函数 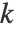 、内核大小
、内核大小 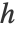 以及培训范例数 m.
以及培训范例数 m. - 可以给出以下选项:
-
Method "Fixed" 内核大小方法 "KernelSize" Automatic 当 Method"Fixed" 时的内核大小 "KernelType" "Gaussian" 使用的内核类型 "NeighborsNumber" Automatic 表示为邻域数的内核大小 - "KernelType" 的可能设置包括:
-
"Gaussian" 每个内核是一个高斯分布 "Ball" 每个内核是球中的均匀分布 - Method 的可能设置包括:
-
"Adaptive" 内核大小彼此不同 "Fixed" 所有内核有同样的大小 - 当 "KernelType""Gaussian",每个内核是个球形高斯(独立正态分布
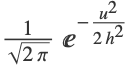 的乘积),并且 "KernelSize" h 指的是正态分布的标准偏差.
的乘积),并且 "KernelSize" h 指的是正态分布的标准偏差. - 当 "KernelType""Ball",每个内核是球内的均匀分布,并且 "KernelSize" 指的是球的半径.
- "NeighborsNumber"k 的值被转换成内核大小,因此,以培训范例为中心的内核一般 "包含" k 个其他培训范例. 如果 "KernelType""Ball","包含" 指的是球内的范例. 如果 "KernelType""Gaussian","包含" 指的是半径为 h
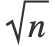 的球内的范例,其中,n 是数据的维数.
的球内的范例,其中,n 是数据的维数. - 当 Method"Fixed" 并且 "NeighborsNumber"k,则找到唯一的内核大小,例如,培训范例包含平均 k 个其他范例.
- 当 Method"Adaptive" 并且 "NeighborsNumber"k, 每个培训范例自适应其内核大小,例如包含大概 k 个其他范例.
- 因为预处理,"NeighborsNumber" 选项一般比 "KernelSize" 更方便控制内核大小. 当 Method"Fixed","KernelSize" 值取代 "NeighborsNumber" 值.
- Information[LearnedDistribution[…],"MethodOption"] 可用于提取由自动系统选择的选项值.
- LearnDistribution[…,FeatureExtractor"Minimal"] 可用于删除大部分预处理和直接访问的方法.
范例
打开所有单元 关闭所有单元基本范例 (3)
在数值数据集上培训 "KernelDensityEstimation" 分布:
查询分布 Information:
在二维数据集上培训 "KernelDensityEstimation" 分布:
使用 SynthesizeMissingValues 估算使用学习分布的丢失值:
在标称数据集上,培训 "KernelDensityEstimation" 分布:
使用 ComputeUncertainty 获取结果中的不确定性:
增加 MaxIterations 提高估计精度: