

SynthesizeMissingValues
SynthesizeMissingValues[{example1,example2,…}]
replaces missing values in each example by generated values.
SynthesizeMissingValues[dist,data]
uses the distribution dist to generate values.
Details and Options
- SynthesizeMissingValues is used to synthesize missing elements in a dataset, inferring them from the known part of the data.
- SynthesizeMissingValues can be used on many types of data, including numerical, nominal and images.
- Each examplei can be a single data element, a list of data elements or an association of data elements. Examples can also be given as a Dataset object.
- The distribution dist must be a LearnedDistribution[…].
- The following options can be given:
-
FeatureNames Automatic feature names to assign for input data FeatureTypes Automatic feature types to assume for input data Method Automatic which modeling algorithm to use MissingValuePattern _MissingIndeterminate the pattern of the assumed missing values PerformanceGoal Automatic aspects of performance to optimize RandomSeeding 1234 what seeding of pseudorandom generators should be done internally TimeGoal Automatic how long to spend for training TrainingProgressReporting Automatic how to report progress during training ValidationSet Automatic the set of data on which to evaluate the model during training - Possible settings for PerformanceGoal include:
-
"Quality" maximize the synthesis quality "Speed" maximize the synthesis speed Automatic automatic tradeoff between speed and quality - Possible settings for Method include:
-
Automatic automatically choose distribution method and synthesis strategy None do not use any missing synthesizer method use the specified method strategy how to synthesize from the distribution assoc specify both distribution method and synthesis strategy - Possible settings for method include:
-
"Multinormal" use a multivariate normal (Gaussian) distribution "ContingencyTable" discretize data and store each possible probability "KernelDensityEstimation" use a kernel mixture distribution "DecisionTree" use a decision tree to compute probabilities "GaussianMixture" use a mixture of Gaussian (normal) distributions - Possible settings for strategy include:
-
Automatic automatically choose the synthesis strategy "MarginalSampling" sample from each feature's marginal distribution "ModeFinding" find the mode of the distribution conditioned on known values "RandomSampling" sample from the distribution conditioned on known values (default) - In the form Methodassoc, the association assoc should be of the form <"LearningMethod"method,"EvaluationStrategy"strategy>.
- The following settings for TrainingProgressReporting can be used:
-
"Panel" show a dynamically updating graphical panel "Print" periodically report information using Print "ProgressIndicator" show a simple ProgressIndicator "SimplePanel" dynamically updating panel without learning curves None do not report any information - Possible settings for RandomSeeding include:
-
Automatic automatically reseed every time the function is called Inherited use externally seeded random numbers seed use an explicit integer or strings as a seed - SynthesizeMissingValues[…,FeatureExtractor"Minimal"] indicates that the internal preprocessing should be as simple as possible.

Examples
open all close allBasic Examples (2)
Fill in missing values in a numeric dataset:
SynthesizeMissingValues[{{1.1, 1.4}, {2.3, 3.1}, {3, 4}, {Missing[], 5.4}, {8.7, 7.5}}]Train a distribution on a two-dimensional dataset:
𝒟 = LearnDistribution[{{1.1, 1.4}, {2.3, 3.1}, {4.4, 5.4}, {8.7, 7.5}}]Fill in missing values based on the learned distribution:
SynthesizeMissingValues[𝒟, {4.2, Missing[]}]Scope (5)
Fill in missing values in a vector:
SynthesizeMissingValues[{0.01, 0.76, Missing[], 0.55, 0.8}]Fill in missing values in a list of vectors:
SynthesizeMissingValues[{{0.06, Missing[], 0.35}, {0.29, 0.18, 0.23}, {0.37, Missing[], 0.57}, {0.97, 0.27, 0.5}, {0.52, 0.41, Missing[]}}]Fill in missing values in a list of associations:
SynthesizeMissingValues[{<|"A" -> 0.06, "B" -> Missing[], "C" -> 0.35|>, <|"A" -> 0.29, "B" -> 0.18, "C" -> 0.23|>, <|"A" -> 0.37, "B" -> Missing[], "C" -> 0.57|>}]Fill in missing values in a dataset:
SynthesizeMissingValues[Dataset[{Association["A" -> 0.06308583355576602, "B" -> Missing[], "C" -> 0.34776641792328333],
Association["A" -> 0.2887127211500238, "B" -> 0.18134408155346105, "C" -> 0.23219728427557107],
Association["A" -> 0.37096010240823185, "B" -> Missing[], "C" -> 0.5690059940858374],
Association["A" -> 0.9699161793933853, "B" -> 0.2708731719060653, "C" -> 0.4956222644053283],
Association["A" -> 0.5153902747338797, "B" -> 0.4082388784233735, "C" -> Missing[]]}]]Fill in values using a pretrained LearnedDistribution[…]:
SynthesizeMissingValues[LearnedDistribution[Association["ExampleNumber" -> 5,
"Preprocessor" -> MachineLearning`MLProcessor["ToMLDataset",
Association["Input" -> Association["f1" -> Association["Type" -> "Numerical"]],
"Output" -> Association["f1" -> Associa ... 0.12995356920788412, 0.1339778434516855}, "LeftBoundary" -> -3.357741463415896,
"LeftScale" -> 0.8219474061282864, "LeftTailNorm" -> 0.011]],
"Entropy" -> Around[0.4407477981827473, 0.02312635896789104], "EntropySampleSize" -> 1000]], {0.01, 0.76, Missing[], 0.55, 0.8}]This can be used to synthesize a single example:
SynthesizeMissingValues[LearnedDistribution[Association["ExampleNumber" -> 5,
"Preprocessor" -> MachineLearning`MLProcessor["ToMLDataset",
Association["Input" -> Association["f1" -> Association["Type" -> "Numerical"]],
"Output" -> Association["f1" -> Associa ... 0.12995356920788412, 0.1339778434516855}, "LeftBoundary" -> -3.357741463415896,
"LeftScale" -> 0.8219474061282864, "LeftTailNorm" -> 0.011]],
"Entropy" -> Around[0.4407477981827473, 0.02312635896789104], "EntropySampleSize" -> 1000]], Missing[]]Options (9)
FeatureTypes (1)
Specify that the first feature should be interpreted as a nominal variable, while the others should be determined automatically:
SynthesizeMissingValues[{{1, 1.1, 3}, {1, 1.5, 2}, {1, 2, 4.2}, {2, 3.2, 3}, {2, 4.4, 5}, {2, 5.2, 6.0}, {2, 7, 7.3}, {Missing[], 9.1, 7}}, FeatureTypes -> {"Nominal", Automatic, Automatic}]FeatureNames (1)
Replace missing values and specify that the feature named "gender" should be considered nominal:
SynthesizeMissingValues[{
<|"age" -> 32, "gender" -> 1|>,
<|"age" -> 41, "gender" -> Missing[]|>,
<|"age" -> 17, "gender" -> 2|>,
<|"age" -> 11, "gender" -> 1|>}, FeatureNames -> {"age", "gender"}, FeatureTypes -> <|"gender" -> "Nominal"|>]Method (2)
Replace Missing[] values using "Multinormal" method for computing the distribution:
SynthesizeMissingValues[{1, 2, 3, Missing[], 5, 6}, Method -> "Multinormal"]Use "KernelDensityEstimation" method for replacing the missing values:
SynthesizeMissingValues[{{1, 2.2}, {2, 3.2}, {3, Missing[]}, {5, 6.2}, {6, 7}}, Method -> "KernelDensityEstimation"]Specify the method as an association, choosing the evaluation strategy and the learning method for computing the distribution:
SynthesizeMissingValues[{{1, 2.2}, {2, 3.2}, {3, Missing[]}, {5, 6.2}, {6, 7}}, Method -> <|"LearningMethod" -> "Multinormal", "EvaluationStrategy" -> "ModeFinding"|>]MissingValuePattern (2)
Specify values that should be assumed missing using MissingValuePattern:
SynthesizeMissingValues[(| | | |
| ---- | ---- | ---- |
| 1.25 | 0.88 | "?" |
| 0.96 | 3.29 | 4.25 |
| "?" | 3.98 | 3.23 |
| 3.25 | 3.99 | 1.31 |
| 2.96 | 4.88 | "?" |
| 2.89 | "?" | 2.48 |), MissingValuePattern -> "?"]Use a pattern to specify the values:
SynthesizeMissingValues[{{1.1, 3, "A"}, {2, 4.2, "A"}, {3.2, 3, "B"}, {4.4, 5, "B"}, {5.2, 6.0, "A"}, {7, 7.3, "B"}, {9.1, 10.2, "B"}}, MissingValuePattern -> _Integer]Specify missing values with Condition:
SynthesizeMissingValues[{{1.1, 3}, {2, 4.2}, {3, 4}, {4.4, 5}, {5, 6}, {7, 8.3}, {9, 10}}, MissingValuePattern -> x_ /; x < 3]PerformanceGoal (1)
Synthesize missing values by specifying the PerformanceGoal:
data = RandomReal[{-1, 1}, {10000, 3}];AbsoluteTiming[SynthesizeMissingValues[data, MissingValuePattern -> x_ /; x > .8, TrainingProgressReporting -> None, PerformanceGoal -> "Speed"]]Compare the missing imputation time with the default PerformanceGoal:
AbsoluteTiming[SynthesizeMissingValues[data, MissingValuePattern -> x_ /; x > .8, TrainingProgressReporting -> None]]TrainingProgressReporting (2)
Print the training progress periodically during training:
SynthesizeMissingValues[RandomReal[{-1, 1}, {1000, 3}], MissingValuePattern -> x_ /; x > .8, TrainingProgressReporting -> "Print"];Show training progress interactively without the plots:
SynthesizeMissingValues[RandomReal[{-1, 1}, {10000, 3}], MissingValuePattern -> x_ /; x > .5, TrainingProgressReporting -> "SimplePanel"]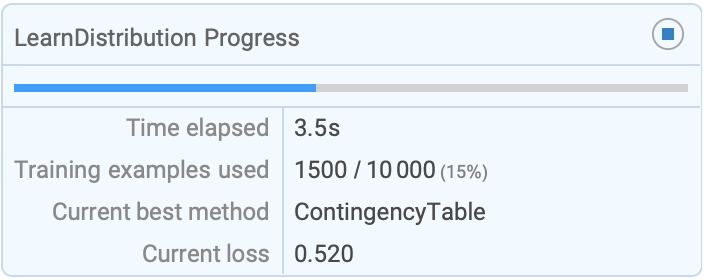
| |
Applications (2)
data = RandomSample[ResourceData["MNIST", "TrainingData"][[All, 1]], 10000];RandomSample[data, 10]Train a distribution on the images:
ld = LearnDistribution[ImageData /@ data]Replace the value that should be considered missing with the samples that are generated from the learned distribution:
synthdata = SynthesizeMissingValues[ld, ImageData /@ {[image], [image]}, MissingValuePattern -> 0.5, Method -> "ModeFinding"];Image /@ synthdataObtain a dataset related to features of moons of Jupiter that contains missing values:
data = Values@ExampleData[{"Dataset", "Planets"}]["Jupiter", "Moons"];
RandomSample[data, 10]Replace missing values in the dataset:
SynthesizeMissingValues[data]Properties & Relations (1)
The "EvaluationStrategy" setting affects the type of sampling that will be performed.
data = RandomVariate[MultinormalDistribution[{{1, .9}, {.9, 1}}], 1000];ListPlot[data]𝒟 = LearnDistribution[data]p = {Missing[], 2};samples = AssociationMap[
method |-> Table[SynthesizeMissingValues[𝒟, p, Method -> method], 50], {"MarginalSampling", "RandomSampling", "ModeFinding"}
];Compare the different sample points distributions:
Histogram[samples[[All, All, 1]], {-3, 3, .1}, "LogPDF", ChartLegends -> Automatic, ChartStyle -> ColorData[97]]Plot the sampled points together with the original data:
Show[
ListPlot[data, PlotStyle -> LightGray],
ListPlot[samples, PlotStyle -> {PointSize[Medium], PointSize[Medium], PointSize@Large}]
]Text
Wolfram Research (2019), SynthesizeMissingValues, Wolfram Language function, https://reference.wolfram.com/language/ref/SynthesizeMissingValues.html.
CMS
Wolfram Language. 2019. "SynthesizeMissingValues." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/SynthesizeMissingValues.html.
APA
Wolfram Language. (2019). SynthesizeMissingValues. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/SynthesizeMissingValues.html