"KernelDensityEstimation" (Machine Learning Method)
- Method for LearnDistribution.
- Models probability density with a mixture of simple distributions.
Details & Suboptions
- "KernelDensityEstimation" is a nonparametric method that models the probability density of a numeric space with a mixture of simple distributions (called kernels) centered around each training example, as in KernelMixtureDistribution.
- The probability density function for a vector
 is given by
is given by 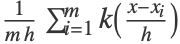 for a kernel function
for a kernel function  , kernel size
, kernel size 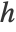 and a number of training examples m.
and a number of training examples m. - The following options can be given:
-
Method "Fixed" kernel size method "KernelSize" Automatic size of the kernels when Method"Fixed" "KernelType" "Gaussian" type of kernel used "NeighborsNumber" Automatic kernel size expressed as a number of neighbors - Possible settings for "KernelType" include:
-
"Gaussian" each kernel is a Gaussian distribution "Ball" each kernel is a uniform distribution on a ball - Possible settings for Method include:
-
"Adaptive" kernel sizes can differ from each other "Fixed" all kernels have the same size - When "KernelType""Gaussian", each kernel is a spherical Gaussian (product of independent normal distributions
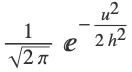 ), and "KernelSize" h refers to the standard deviation of the normal distribution.
), and "KernelSize" h refers to the standard deviation of the normal distribution. - When "KernelType""Ball", each kernel is a uniform distribution inside a sphere, and "KernelSize" refers to the radius of the sphere.
- The value of "NeighborsNumber"k is converted into kernel size(s), so that a kernel centered around a training example typically "contains" k other training examples. If "KernelType""Ball", "contains" refers to examples that are inside the ball. If "KernelType""Gaussian", "contains" refers to examples that are inside a ball of radius h
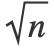 where n is the dimension of the data.
where n is the dimension of the data. - When Method"Fixed" and "NeighborsNumber"k, a unique kernel size is found such that training examples contain on average k other examples.
- When Method"Adaptive" and "NeighborsNumber"k, each training example adapts its kernel size such that it contains about k other examples.
- Because of preprocessing, the "NeighborsNumber" option is typically a more convenient way to control kernel sizes than "KernelSize". When Method"Fixed", the value of "KernelSize" supersedes the value of "NeighborsNumber".
- Information[LearnedDistribution[…],"MethodOption"] can be used to extract the values of options chosen by the automation system.
- LearnDistribution[…,FeatureExtractor"Minimal"] can be used to remove most preprocessing and directly access the method.
Examples
open all close allBasic Examples (3)
Train a "KernelDensityEstimation" distribution on a numeric dataset:
ld = LearnDistribution[{1.2, 2.1, 3.5, 4.3}, Method -> "KernelDensityEstimation"]Look at the distribution Information:
Information[ld]Information[ld, "MethodOption"]Obtain an option value directly:
Information[ld, "KernelType"]Compute the probability density for a new example:
PDF[ld, 1.3]Plot the PDF along with the training data:
Show[Plot[PDF[ld, x], {x, -6, 12}, Filling -> Bottom], NumberLinePlot[{1.2, 2.1, 3.5, 4.3}, Spacings -> 0, PlotStyle -> Red]]Generate and visualize new samples:
Histogram[RandomVariate[ld, 10000], 50]Train a "KernelDensityEstimation" distribution on a two-dimensional dataset:
iris = ExampleData[{"MachineLearning", "FisherIris"}, "Data"][[All, 1, {1, 3}]];ld = LearnDistribution[iris, Method -> "KernelDensityEstimation"]Plot the PDF along with the training data:
Show[ContourPlot[PDF[ld, {x, y}], {x, 4, 8}, {y, 1, 7}, PlotRange -> All, Contours -> 10], ListPlot[iris, PlotStyle -> Red]]Use SynthesizeMissingValues to impute missing values using the learned distribution:
SynthesizeMissingValues[ld, {5.5, Missing[]}]Histogram[Table[Last@SynthesizeMissingValues[ld, {5.5, Missing[]}], 1000]]Train a "KernelDensityEstimation" distribution on a nominal dataset:
ld = LearnDistribution[{"A", "A", "B", "B", "B"}, Method -> "KernelDensityEstimation"]Because of the necessary preprocessing, the PDF computation is not exact:
PDF[ld, "A"]PDF[ld, "A"]Use ComputeUncertainty to obtain the uncertainty on the result:
PDF[ld, "A", ComputeUncertainty -> True]Increase MaxIterations to improve the estimation precision:
PDF[ld, "A", MaxIterations -> 1000, ComputeUncertainty -> True]Options (4)
"KernelSize" (1)
Train a kernel mixture distribution with a kernel size of 0.2:
iris = ExampleData[{"MachineLearning", "FisherIris"}, "Data"][[All, 1, {1, 3}]];ld = LearnDistribution[iris, Method -> {"KernelDensityEstimation", "KernelSize" -> 0.2}]Evaluate the PDF of the distribution at a specific point:
PDF[ld, {6, 4}]Visualize the PDF obtained after training a kernel mixture distribution with various kernel sizes:
plots = (
ld = LearnDistribution[iris, Method -> {"KernelDensityEstimation", "KernelSize" -> #}, FeatureExtractor -> "Minimal"];
Show[ContourPlot[PDF[ld, {x, y}], {x, 2, 10}, {y, 0, 8}, PlotRange -> All, Contours -> 10], ListPlot[iris, PlotStyle -> Red], ImageSize -> 250, PlotLabel -> "h = " <> ToString[#]]
) & /@ {0.05, 0.1, 0.2, 0.35, 0.5, 1};Grid[Partition[plots, 2]]"KernelType" (1)
Train a "KernelDensityEstimation" distribution with a "Ball" kernel:
iris = ExampleData[{"MachineLearning", "FisherIris"}, "Data"][[All, 1, {1, 3}]];ld = LearnDistribution[iris, Method -> {"KernelDensityEstimation", "KernelType" -> "Ball"}]Evaluate the PDF of the distribution at a specific point:
PDF[ld, {6, 4}]Visualize the PDF obtained after training a kernel mixture distribution with a "Ball" and a "Gaussian" kernel:
plots = (ld = LearnDistribution[iris, Method -> {"KernelDensityEstimation", "KernelType" -> #}, FeatureExtractor -> "Minimal"];
Show[ContourPlot[PDF[ld, {x, y}], {x, 2, 10}, {y, 0, 8}, PlotRange -> All, Contours -> 10, PlotLabel -> #], ListPlot[iris, PlotStyle -> Red], ImageSize -> 250]) & /@ {"Ball", "Gaussian"};Row[plots]Method (1)
Train a "KernelDensityEstimation" distribution with the "Adaptive" method:
iris = ExampleData[{"MachineLearning", "FisherIris"}, "Data"][[All, 1, {1, 3}]];ld = LearnDistribution[iris, Method -> {"KernelDensityEstimation", Method -> "Adaptive"}]Evaluate the PDF of the distribution at a specific point:
PDF[ld, {6, 4}]Visualize the PDF obtained after training a kernel mixture distribution with a "Ball" and a "Gaussian" kernel:
plots = (ld = LearnDistribution[iris, Method -> {"KernelDensityEstimation", Method -> #}, FeatureExtractor -> "Minimal"];
Show[ContourPlot[PDF[ld, {x, y}], {x, 2, 10}, {y, 0, 8}, PlotRange -> All, Contours -> 10, PlotLabel -> #], ListPlot[iris, PlotStyle -> Red], ImageSize -> 250]) & /@ {"Fixed", "Adaptive"};Row[plots]"NeighborsNumber" (1)
Train a kernel mixture distribution with a kernel size of about 10 neighbors:
iris = ExampleData[{"MachineLearning", "FisherIris"}, "Data"][[All, 1, {1, 3}]];ld = LearnDistribution[iris, Method -> {"KernelDensityEstimation", "NeighborsNumber" -> 10}]Evaluate the PDF of the distribution at a specific point:
PDF[ld, {6, 4}]Visualize the PDF obtained after training a kernel mixture distribution with various kernel sizes expressed as neighbors numbers:
plots = (
ld = LearnDistribution[iris, Method -> {"KernelDensityEstimation", "NeighborsNumber" -> #}, FeatureExtractor -> "Minimal"];
Show[ContourPlot[PDF[ld, {x, y}], {x, 2, 10}, {y, 0, 8}, PlotRange -> All, Contours -> 10], ListPlot[iris, PlotStyle -> Red], ImageSize -> 250, PlotLabel -> "k = " <> ToString[#]]
) & /@ {1, 2, 5, 10, 20, 50};Grid[Partition[plots, 2]]