"MeanShift" (機械学習メソッド)
- FindClusters,ClusterClassify,ClusteringComponentsのためのメソッドである.
- "MeanShift"クラスタリングアルゴリズムを使って,データを類似要素のクラスタに分割する.
詳細とサブオプション
- "MeanShift"は密度に基づくクラスタリングメソッドである.密度は近傍に基づくアプローチで推定される."MeanShift"は任意の形状とサイズのクラスタに使うことができるが,クラスタの密度が違ったりクラスタ同士が絡み合っていたりするとうまくクラスタ化できないことがある.
- 次のプロットは,"MeanShift"法をトイデータ集合に適用した結果を示している.
-

- "MeanShift"法は,反復的に点を高密度領域にシフトさせる.この手続きの間にデータ点は,それぞれがクラスタを表す異なる固定点に畳み込まれがちである.
- 正式には,各ステップで,各データ点
 が
が 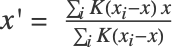 に設定される.ただし,
に設定される.ただし, であり,
であり, は実質的な近傍半径を定義する.
は実質的な近傍半径を定義する. が与える差は平均シフトと呼ばれる.このアルゴリズムは点が動かなくなり,あるクラスタに属するすべての点が(許容限度まで)折りたたまれるまで平均シフトを繰返し更新する.このアルゴリズムは"NeighborhoodContraction"法に等しいが,近傍の定義は異なる.
が与える差は平均シフトと呼ばれる.このアルゴリズムは点が動かなくなり,あるクラスタに属するすべての点が(許容限度まで)折りたたまれるまで平均シフトを繰返し更新する.このアルゴリズムは"NeighborhoodContraction"法に等しいが,近傍の定義は異なる. - 使用する距離はオプションDistanceFunctionを使って定義できる.
- 次は,使用可能なサブオプションである.
-
"NeighborhoodRadius" Automatic 半径 ϵ
例題
すべて開くすべて閉じる例 (3)
"MeanShift"クラスタリング法を使って近くの値のクラスタを求める:
"MeanShift"法を使って,ClassifierFunctionを色のリストで訓練する:
ClassifierFunctionを文字列のリストで訓練する: