"MeanShift" (Machine Learning Method)
"MeanShift" (Machine Learning Method)
- Method for FindClusters, ClusterClassify and ClusteringComponents.
- Partitions data into clusters of similar elements using "MeanShift" clustering algorithm.
Details & Suboptions
- "MeanShift" is a density-based clustering method where the density is estimated using a neighbor-based approach. "MeanShift" works for arbitrary cluster shapes and sizes; however, it can fail when clusters have different densities or are intertwined.
- The following plots show the results of the "MeanShift" method applied to toy datasets:
-

- The "MeanShift" method iteratively shifts data points toward higher-density regions. During this procedure, data points tend to collapse to different fixed points, each of them representing a cluster.
- Formally, at each step, each data point
 is set to
is set to 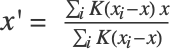 with
with  ,
, 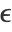 defining an effective neighborhood radius. The difference
defining an effective neighborhood radius. The difference  is called mean shift. The algorithm repeats the mean-shift updates until points stop moving; all points belonging to a cluster are then collapsed (up to a tolerance). This algorithm is equivalent to the "NeighborhoodContraction" method but with a different neighborhood definition.
is called mean shift. The algorithm repeats the mean-shift updates until points stop moving; all points belonging to a cluster are then collapsed (up to a tolerance). This algorithm is equivalent to the "NeighborhoodContraction" method but with a different neighborhood definition. - The option DistanceFunction can be used to define which distance to use.
- The following suboption can be given:
-
"NeighborhoodRadius" Automatic radius ϵ
Examples
open all close allBasic Examples (3)
Find clusters of nearby values using the "MeanShift" clustering method:
FindClusters[{1, 2, 10, 12, 3, 1, 13, 25}, Method -> "MeanShift"]Train the ClassifierFunction on a list of colors using the "MeanShift" method:
colors = RandomColor[200];
c = ClusterClassify[colors, Method -> "MeanShift"]Gather the elements by their class number:
GatherBy[colors, c]Train a ClassifierFunction on a list of strings:
string = {"c", "a", "b", "xxx", "xxxxx", "uuuuu4u", "u5uuuuu"};
c = ClusterClassify[string, Method -> "MeanShift"]Find the cluster assignments and gather the elements by their cluster:
components = c[string]
GatherBy[string, c]Options (3)
DistanceFunction (1)
"NeighborhoodRadius" (2)
Find clusters by specifying the "NeighborhoodRadius" suboption:
FindClusters[{1, 2, 10, 12, 3, 1, 13, 25}, Method -> {"MeanShift", "NeighborhoodRadius" -> 1}]Generate a list of 100 random colors:
colors = RandomColor[100]Cluster the colors using the "MeanShift" method:
FindClusters[colors, Method -> "MeanShift"]Try different "NeighborhoodRadius" suboptions for clustering the colors:
Grid[{Table[FindClusters[colors, Method -> {"MeanShift", "NeighborhoodRadius" -> r}], {r, {1, 5, 10}}]}, Frame -> All]