"MeanShift" (机器学习方法)
- 用于 FindClusters、ClusterClassify 和 ClusteringComponents 的方法.
- 使用 "MeanShift" 聚类算法将数据划分为相似元素的聚类.
Details & Suboptions
- "MeanShift" 是一种基于密度的聚类方法,其中使用基于邻域的方法来估计密度. "MeanShift" 适用于任意形状和大小的聚类;但是,当聚类具有不同的密度或相互交织时,它可能会失败.
- 下图展示了将 "MeanShift" 方法应用于玩具数据集的结果:
-

- "MeanShift" 方法以迭代方式将数据点移向更高密度的区域. 在此过程中,数据点往往会收缩到不同的固定点,每个固定点都代表一个聚类.
- 形式上,在每一步中,每个数据点
 被设置为
被设置为 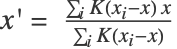 ,其中
,其中  ,
,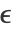 定义了一个有效的邻域半径.
定义了一个有效的邻域半径.  的差被称为均值偏移. 算法重复均值偏移更新,直到点停止移动;然后将属于一个聚类的所有点折叠(在一定容差范围内). 这个算法等同于 "NeighborhoodContraction" 方法,但使用了不同的邻域定义.
的差被称为均值偏移. 算法重复均值偏移更新,直到点停止移动;然后将属于一个聚类的所有点折叠(在一定容差范围内). 这个算法等同于 "NeighborhoodContraction" 方法,但使用了不同的邻域定义. - 选项 DistanceFunction 可用于定义要使用的距离.
- 可以给出以下子选项:
-
"NeighborhoodRadius" Automatic 半径 ϵ
范例
打开所有单元关闭所有单元基本范例 (3)
使用 "MeanShift" 方法在颜色列表上训练 ClassifierFunction:
在字符串列表上训练 ClassifierFunction: