"NeighborhoodContraction" (機械学習メソッド)
"NeighborhoodContraction" (機械学習メソッド)
- FindClusters, ClusterClassifyとClusteringComponentsのためのメソッドである.
- "NeighborhoodContraction" クラスタリングアルゴリズムを使ってデータを類似要素のクラスタに分割する.
詳細とサブオプション
- "NeighborhoodContraction"は近傍に基づくクラスタリング法である."NeighborhoodContraction"は任意の形状とサイズのクラスタに使用できるが,クラスタの密度が異なったりクラスタ同士が絡み合ったりしている場合はあまりうまくいかないかもしれない.
- 次のプロットは,"NeighborhoodContraction"法をトイデータ集合に適用した結果を示している.
-

- "NeighborhoodContraction"法は,より密度が高い領域に向けて反復的にデータ点をシフトする.この手続き中に,データ点は,それぞれがクラスタを表す別の固定点に折りたたまれる傾向にある.
- 正式には,各ステップで,各データ点
 がその近傍の点
がその近傍の点 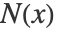 ,
, 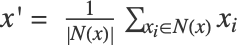 の平均に設定される.
の平均に設定される. - 近傍の点
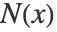 は半径 ϵ の球内のすべての点として定義される.このアルゴリズムは点が動かなくなるまで更新を続ける.次に,クラスタに属するすべての点が(許容範囲まで)折りたたまれる.このアルゴリズムは"MeanShift"法と同等であるが,近傍の定義が異なる.
は半径 ϵ の球内のすべての点として定義される.このアルゴリズムは点が動かなくなるまで更新を続ける.次に,クラスタに属するすべての点が(許容範囲まで)折りたたまれる.このアルゴリズムは"MeanShift"法と同等であるが,近傍の定義が異なる. - 次は,使用可能なサブオプションである.
-
"NeighborhoodRadius" Automatic 半径 ϵ
例題
すべて開く すべて閉じる例 (3)
"NeighborhoodContraction"クラスタリング法を使って近くの値のクラスタを求める:
"NeighborhoodContraction"法を使い,ClassifierFunctionを色のリストで訓練する:
ClassifierFunctionを二次元正規分布の混合について訓練する:
オプション (3)
DistanceFunction (2)
DistanceFunction オプションを指定してクラスタを求める:
異なるDistanceFunction オプションを指定して異なるクラスタリング構造を求める: