Sequence Learning and NLP with Neural Networks
Sequence Learning and NLP with Neural Networks
| Sequence Regression | Question Answering |
| Sequence Classification | Language Modeling |
| Sequence-to-Sequence Learning |
Sequence learning refers to a variety of related tasks that neural nets can be trained to perform. What all these tasks have in common is that the input to the net is a sequence of some kind. This input is usually variable length, meaning that the net can operate equally well on short or long sequences.
- A variable-length array, encoded from a string using a "Characters" or "Tokens" NetEncoder.
- A variable-length array, encoded from an Audio object using an "Audio", "AudioSpectrogram", "AudioSTFT", etc. NetEncoder.
- Fixed-length forms of the above, e.g. by using the "TargetLength" option to the NetEncoder.
What distinguishes the various sequence learning tasks is the form of the output of the net. Here, there is wide diversity of techniques, with corresponding forms of output:
- For autoregressive language models, used to model the probability of
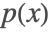 of a particular sequence x, the output is the next element of the sequence. In the case of a textual model, this is a character or token, as decoded via a "Class", "Characters" or "Token" NetDecoder.
of a particular sequence x, the output is the next element of the sequence. In the case of a textual model, this is a character or token, as decoded via a "Class", "Characters" or "Token" NetDecoder.
- For sequence tagging models, the output is a sequence of classes of the same length as the input. For example, in the case of a part-of-speech tagger, these classes are "Noun", "Verb", etc. For this, a "Class" NetDecoder is appropriate.
- For translation models, e.g. an English to French translator, the output is itself a language model, albeit one that is conditional on the source sequence. In other words, there are two inputs to the net: the complete source sequence, and the target sequence so far, and the output is a prediction of the next element of the target sequence.
- For CTC models, the input sequence is used to form a sequence of intermittent predictions for the target sequence, which is always shorter than the input sequence. Examples of this include handwriting recognition from pixel or stroke data, in which the input is segmented into individual characters, or audio transcription, in which features of the audio are segmented into characters or phonemes. For these, a "CTCBeamSearch" NetDecoder must be used.
Integer Addition
In this example, a net is trained to add two two-digit integers together. What makes the problem hard is that the inputs are strings rather than numeric values, whereas the output is a numeric value. For example, the net takes as input "25+33" and needs to return a real number close to 58. Note that the input is variable length, as the training data contains examples of length 3 ("5+5"), length 4 ("5+10") and length 5 ("10+10").
Create training data based on strings that describe two-digit additions and the corresponding numeric result:
enc = NetEncoder[{"Characters", {DigitCharacter, "+"}}];
makeRule[a_, b_] := IntegerString[a] <> "+" <> IntegerString[b] -> a + b;
trainingData = Flatten@Table[makeRule[i, j], {i, 0, 99}, {j, 0, 99}];
RandomSample[trainingData, 4]//InputFormCreate a net composed of a chain of recurrent layers to read an input string and predict the numeric result:
net = NetChain[{UnitVectorLayer[], LongShortTermMemoryLayer[40], LongShortTermMemoryLayer[20], SequenceLastLayer[], LinearLayer[]}, "Input" -> enc, "Output" -> "Real"];result = NetTrain[net, trainingData, All, BatchSize -> 64, MaxTrainingRounds -> 200, ValidationSet -> Scaled[0.1]]
trained = result["TrainedNet"]Round@trained[{"5+2", "10+25", "9+11", "44+44"}]Sentiment Analysis
trainingData = ExampleData[{"MachineLearning", "MovieReview"}, "TrainingData"];
testData = ExampleData[{"MachineLearning", "MovieReview"}, "TestData"];RandomSample[trainingData, 2]net = NetChain[{EmbeddingLayer[40], DropoutLayer[0.3], LongShortTermMemoryLayer[20], SequenceLastLayer[], LinearLayer[2], SoftmaxLayer[]},
"Input" -> NetEncoder[{"Tokens"}], "Output" -> NetDecoder[{"Class", {"positive", "negative"}}]
]result = NetTrain[net, trainingData, All, ValidationSet -> testData, MaxTrainingRounds -> 2]
trained = result["TrainedNet"]ex = testData[[50, 1]]trained[ex, "Probabilities"]Sequence-to-sequence learning is a learning task where both the input and the predicted output are sequences. Tasks such as translating German to English, transcribing speech from an audio file, sorting lists of numbers, etc. are examples of this task.
Integer Addition with Fixed-Length Output
This example demonstrates how to train nets that take a variable-length sequence as input and predict a fixed-length sequence as output. We take a string that describes a sum, e.g. "250+123", and produce an output string that describes the answer, e.g. "373".
Create training data based on strings that describe three-digit additions and the corresponding result as a string. In order for the output to be fixed length, all outputs are padded to the maximum length of 4 (as the maximum value is 999+999=1998):
makeRule[a_, b_] := IntegerString[a] <> "+" <> IntegerString[b] -> IntegerString[a + b];
data = RandomSample[Flatten@Table[makeRule[i, j], {i, 0, 999}, {j, 0, 999}], 40000];
data[[ ;; , 2]] = StringPadRight[data[[ ;; , 2]], 4];
{testData, trainingData} = TakeDrop[data, 4000];RandomSample[trainingData, 4]//InputFormnet = NetChain[{UnitVectorLayer[11], LongShortTermMemoryLayer[128], SequenceLastLayer[], ReplicateLayer[4], LongShortTermMemoryLayer[128], NetMapOperator[LinearLayer[]], SoftmaxLayer[]},
"Input" -> NetEncoder[{"Characters", {DigitCharacter, "+"}}], "Output" -> NetDecoder[{"Characters", {DigitCharacter, " "}}]]result = NetTrain[net, trainingData, All, ValidationSet -> testData, MaxTrainingRounds -> 40]
trainedNet = result["TrainedNet"]StringTrim@trainedNet[{"2+432", "100+43", "400+500"}]prediction = trainedNet[testData[[ ;; , 1]]];
accuracy = N@Count[prediction - testData[[ ;; , 2]], 0] / Length[prediction]Integer Addition with Variable-Length Output
This example demonstrates how to train nets on sequences where both the input and output are variable-length sequences, and those sequences are not the same. One sophisticated example of this task is translating English to German, but the example we cover is a simpler problem: taking a string that describes a sum, e.g. "250+123", and producing an output string that describes the answer, e.g. "373". The method used is based on I. Sutskever et al., "Sequence to Sequence Learning with Neural Networks", 2014.
Create training data based on strings that describe three-digit additions and the corresponding result as a string:
makeRule[a_, b_] := IntegerString[a] <> "+" <> IntegerString[b] -> IntegerString[a + b];
data = Flatten@Table[makeRule[i, j], {i, 0, 999}, {j, 0, 999}];
data = RandomSample@Catenate@GroupBy[data, First /* StringLength, RandomSample[#, UpTo[10000]]&];
{testData, trainingData} = TakeDrop[data, 2500];RandomSample[trainingData, 4]Create a NetEncoder that uses a special code for the start and end of a string, which will be used to indicate the beginning and end of the output sequence:
targetEnc = NetEncoder[{"Characters", {DigitCharacter, {StartOfString, EndOfString} -> Automatic}}]targetEnc["1"]inputEnc = NetEncoder[{"Characters", {DigitCharacter, "+"}}]encoderNet = NetChain[{UnitVectorLayer[], GatedRecurrentLayer[150], SequenceLastLayer[]}]Define a net that takes an input vector of size 150 and a sequence of vectors as input and returns a sequence of vectors as output:
decoderNet = NetGraph[{
UnitVectorLayer[11],
SequenceMostLayer[],
GatedRecurrentLayer[150],
NetMapOperator[LinearLayer[]],
SoftmaxLayer[]},
{NetPort["Input"] -> 1 -> 2 -> 3 -> 4 -> 5,
NetPort["State"] -> NetPort[3, "State"]}
]Define a net with a CrossEntropyLossLayer and containing the encoder and decoder nets:
trainingNet = NetGraph[<|"encoder" -> encoderNet, "decoder" -> decoderNet, "loss" -> CrossEntropyLossLayer["Index"], "rest" -> SequenceRestLayer[]|>,
{NetPort["Input"] -> "encoder" -> NetPort["decoder", "State"],
NetPort["Target"] -> NetPort["decoder", "Input"],
"decoder" -> NetPort["loss", "Input"],
NetPort["Target"] -> "rest" -> NetPort["loss", "Target"]},
"Input" -> inputEnc, "Target" -> targetEnc]result = NetTrain[trainingNet, trainingData, All, ValidationSet -> testData, MaxTrainingRounds -> 50]
trainedNet = result["TrainedNet"]In this case of three-digit integer addition, there are only 1999 possible outputs. It is feasible to calculate the loss for each possible output and find the one that minimizes the loss:
predict[input_] := First@Ordering[trainedNet[<|"Input" -> ConstantArray[input, 1999], "Target" -> Table[ToString[i], {i, 1999}]|>], 1]predict /@ {"34+200", "32+87", "344+77"}input = "200+300";
ListPlot[trainedNet[<|"Input" -> ConstantArray[input, 1999], "Target" -> Table[IntegerString[i], {i, 1999}]|>], AxesLabel -> {"sum", "loss"}]A more efficient way of obtaining predictions is to generate the output until the EndOfString virtual character is reached.
First, extract the trained "encoder" and "decoder" subnets from the trained NetGraph, and attach appropriate encoders and decoders:
trainedEncoder = NetReplacePart[NetExtract[trainedNet, "encoder"], "Input" -> inputEnc]trainedDecoder = NetExtract[trainedNet, "decoder"]Use a SequenceLastLayer to make a version of the decoder that only produces predictions for the last character of the answer, given the previous characters. Here a character decoder is attached for the probability vector using the same alphabet as the "Target" input:
targetDec = NetDecoder[{"Characters", {DigitCharacter, {StartOfString, EndOfString} -> Automatic}, "InputDepth" -> 1}];
charPredictor1 = NetGraph[{trainedDecoder, SequenceLastLayer[]}, {1 -> 2}, "Input" -> targetEnc, "Output" -> targetDec]state = trainedEncoder["25+25"];
charPredictor1[<|"Input" -> "5", "State" -> state|>]//InputFormcharPredictor1[<|"Input" -> "50", "State" -> state|>]//InputFormNow define a prediction function that takes the "encoder" and "decoder" nets and an input string. The function will compute successively longer results until the decoder claims to be finished:
predict2[input_] := Module[
{encoded = trainedEncoder[input], result = "", prediction},
Do[
prediction = charPredictor1[<|"Input" -> result, "State" -> encoded|>];
If[prediction === "", Break[]];
result = result <> prediction,
100]; (* stop at length 100, just in case *)
result
]predict2["564+200"]//InputForminputs = {"564+200", "44+87", "344+67"};
predict2 /@ inputspredict /@ inputsThe naive technique of generating by passing in each partial answer to the decoder net to derive the next character has time complexity of n2, where n is the length of the output sequence, and so is not appropriate for generating longer sequences. NetStateObject can be used to generate with time complexity of n.
First, a decoder is created that takes a single character and predicts the next character. The recurrent state of the GatedRecurrentLayer is handled by a NetStateObject at a later point.
gru = NetExtract[trainedNet, {"decoder", 3}]
linear = NetExtract[trainedNet, {"decoder", 4, "Net"}]Define a "Class" encoder and decoder that will encode and decode individual characters, as well as the special classes to indicate the start and end of the string:
digits = Characters["0123456789"];
classEnc = NetEncoder[{"Class", Append[digits, StartOfString]}];
classDec = NetDecoder[{"Class", Append[digits, EndOfString]}];Define a net that takes a single character, runs one step of the GatedRecurrentLayer, and produces a single softmax prediction:
charPredictor2 = NetChain[{UnitVectorLayer[], ReshapeLayer[{1, 11}], gru, ReshapeLayer[{150}], linear, SoftmaxLayer[]}, "Input" -> classEnc, "Output" -> classDec]This predictor has an internal recurrent state, as revealed by Information:
Information[charPredictor2, "RecurrentStatesPositionList"]Create a function that uses NetStateObject to memorize the internal recurrent state, which is seeded from the code produced by the trained encoder:
predict3[input_] := Module[{code, sobj, res},
code = trainedEncoder[input];
sobj = NetStateObject[charPredictor2, <|{3, "State"} -> code|>];
res = NestWhileList[sobj, StartOfString, # =!= EndOfString&];
StringJoin@res[[2 ;; -2]]
]predict3["111+111"]//FullFormpredict3 /@ {"564+200", "44+87", "344+67"}prediction = predict3 /@ Keys[testData];
accuracy = N@Mean@Boole@MapThread[Equal, {prediction, Values[testData]}]Integer Sorting
In this example, a net is trained to sort lists of integers. For example, the net takes as input {3,2,4} and needs to return {2,3,4}. This example also demonstrates the use of an AttentionLayer, which significantly improves the performance of neural nets on many sequence learning tasks.
digits = Range[6];
seqs = RandomSample[Flatten[Table[Tuples[digits, n], {n, 3, 6}], 1]];
data = Map[# -> Sort[#]&, seqs];
{testData, trainData} = TakeDrop[data, Ceiling[Length[data] / 10]];RandomSample[trainData, 3]net = NetGraph[<|
"enc" -> {EmbeddingLayer[12], LongShortTermMemoryLayer[50]}, "dec" -> LongShortTermMemoryLayer[50],
"key" -> NetMapOperator[50],
"value" -> NetMapOperator[50],
"attend" -> AttentionLayer["Dot"],
"cat" -> CatenateLayer[2], "classify" -> {NetMapOperator[LinearLayer[]], SoftmaxLayer[]}
|>, {
"enc" -> "key" -> NetPort["attend", "Key"], "enc" -> "value" -> NetPort["attend", "Value"],
"enc" -> "dec" -> NetPort["attend", "Query"],
"dec" -> "cat", "attend" -> "cat", "cat" -> "classify"}, "Input" -> {"Varying", NetEncoder[{"Class", digits}]}, "Output" -> {"Varying", NetDecoder[{"Class", digits}]}
]result = NetTrain[net, trainData, All, MaxTrainingRounds -> 3, ValidationSet -> testData]
trained = result["TrainedNet"]trained[{6, 6, 1, 4, 2}]Optical Character Recognition (OCR) on a Toy Dataset
The optical character recognition problem is to take an image containing a sequence of characters and return the list of characters. One simple approach is to preprocess the image to produce images containing only a single character and do classification. This is a fragile approach and completely fails for domains such as cursive handwriting, where the characters run together.
First, generate training and test data, which consists of images of words and the corresponding word string:
imgMap = <|" " -> [image], "a" -> [image], "b" -> [image], "c" -> [image], "d" -> [image], "e" -> [image], "f" -> [image], "g" -> [image], "h" -> [image], "i" -> [image], "j" -> [image], "k" -> [image], "l" -> [image], "m" -> [image], "n" -> [image], "o" -> [image], "p" -> [image], "q" -> [image], "r" -> [image], "s" -> [image], "t" -> [image], "u" -> [image], "v" -> [image], "w" -> [image], "x" -> [image], "y" -> [image], "z" -> [image]|>;maxLen = 7;
wordList = ToLowerCase[Select[WordList[], StringLength[#] ≤ maxLen && LetterQ[#]&]];
SeedRandom[1234];
wordList = RandomSample[StringPadRight[wordList, maxLen]];
dataset = Dataset@Map[<|"Input" -> ImageAssemble[Lookup[imgMap, Characters[#]]], "Output" -> StringTrim[#]|>&, wordList];{testData, trainData} = TakeDrop[dataset, Ceiling[Length[dataset] / 10]];Take a RandomSample of the training set:
RandomSample[trainData, 4]chars = CharacterRange["a", "z"]decoder = NetDecoder[{"CTCBeamSearch", chars, "BeamSize" -> 50}]Define a net that takes an image and then treats the width dimension as a sequence dimension. A sequence of probability vectors over the width dimension is produced:
ocrNet = NetChain[{ConvolutionLayer[20, 3], BatchNormalizationLayer[], Ramp, PoolingLayer[2], ConvolutionLayer[15, 3], BatchNormalizationLayer[], Ramp, PoolingLayer[2], FlattenLayer[1], TransposeLayer[], GatedRecurrentLayer[19], GatedRecurrentLayer[19], NetMapOperator[LinearLayer[Length[chars] + 1]], SoftmaxLayer[]}, "Input" -> NetEncoder[{"Image", {63, 15}, "Grayscale"}], "Output" -> decoder]loss = CTCLossLayer["Target" -> NetEncoder[{"Characters", chars}]]result = NetTrain[ocrNet, trainData, All, LossFunction -> loss, MaxTrainingRounds -> 20, ValidationSet -> testData]
trainedNet = result["TrainedNet"]testIms = Normal@testData[1 ;; 3, "Input"]trainedNet[testIms]trainedNet[[image], {"TopNegativeLogLikelihoods", 5}]Simple RNN Trained on the bAbI QA Dataset
Train a question-answering net on the first task (Single Supporting Fact) of the bAbI QA dataset using a recurrent network.
ro = ResourceObject["The 20-Task bAbI Question-Answering Dataset v1.2"]traindata = ResourceData[ro, "TrainingData"]["Task1"];
testdata = ResourceData[ro, "TestData"]["Task1"];traindata[[All, 100]]dict = Union@@TextWords[Join[traindata["Context"], traindata["Question"]]]classes = Union[traindata["Answer"]]enc = NetEncoder[{"Tokens", Join[dict, {"."}]}];
net = NetGraph[<|
"context" -> {EmbeddingLayer[50], DropoutLayer[0.3]}, "question" -> {EmbeddingLayer[50], DropoutLayer[0.3], LongShortTermMemoryLayer[50], SequenceLastLayer[]}, "cat" -> CatenateLayer[], "classifier" -> {LongShortTermMemoryLayer[50], SequenceLastLayer[], DropoutLayer[0.3], LinearLayer[Length[classes]], SoftmaxLayer[]}|>,
{NetPort["Context"] -> "context", NetPort["Question"] -> "question",
{"question", "context"} -> "cat", "cat" -> "classifier" -> NetPort["Answer"]},
"Context" -> enc, "Question" -> enc, "Answer" -> NetDecoder[{"Class", classes}]]Train the network for three training rounds. NetTrain will automatically attach a CrossEntropyLossLayer using the same classes that were provided to the decoder:
result = NetTrain[net, traindata, All, ValidationSet -> testdata, MaxTrainingRounds -> 30]
trainedNet = result["TrainedNet"]trainedNet[<|"Context" -> "Sandra went to the office. Sandra travelled to the bathroom. Mary went back to the bedroom. Daniel moved to the garden. John journeyed to the garden. Daniel went back to the hallway. John journeyed to the bedroom. Mary travelled to the kitchen. Sandra went to the bedroom. Daniel went to the garden.", "Question" -> "Where is Daniel?"|>]N@Count[trainedNet[KeyDrop[testdata, "Answer"]] - testdata["Answer"], 0] / Length[testdata["Answer"]]Memory Network Trained on the bAbI QA Dataset
Train a question-answering net on the first task (Single Supporting Fact) of the bAbI QA dataset, using a memory network based on Sukhbaatar et al., "End-to-End Memory Networks", 2015.
ro = ResourceObject["The 20-Task bAbI Question-Answering Dataset v1.2"]traindata = ResourceData[ro, "TrainingData"]["Task1"];
testdata = ResourceData[ro, "TestData"]["Task1"];traindata[[All, 100]]The memory net has layers (such as TransposeLayer) that currently do not support variable-length sequences.
Convert all strings to lists of tokens and use left padding (which has better performance than right padding for this example) to ensure these lists are the same length:
maxContextLen = 68;
maxQueryLen = 4;
stringPreprocess[strings_] := PadLeft[#, maxContextLen, Padding]& /@ StringSplit[strings, {" ", ", " -> ",", ". " -> ".", "?" -> "?", "." -> "."}];traindata["Context"] = stringPreprocess[traindata["Context"]];
testdata["Context"] = stringPreprocess[testdata["Context"]];
traindata["Question"] = StringSplit[traindata["Question"], {"?" -> "?", " "}];
testdata["Question"] = StringSplit[testdata["Question"], {"?" -> "?", " "}];traindata[[All, 3]]dict = Union@Flatten[Join[traindata["Context"], traindata["Question"]]]classes = Union[traindata["Answer"]]embedDim = 64;
enc = NetEncoder[{"Class", dict}];
memNet = NetGraph[<|
"context1" -> {EmbeddingLayer[embedDim], DropoutLayer[0.3]}, "context2" -> {EmbeddingLayer[maxQueryLen], DropoutLayer[0.3]}, "question" -> {EmbeddingLayer[embedDim], DropoutLayer[0.3]}, "trans1" -> TransposeLayer[], "trans2" -> TransposeLayer[],
"featureMatch" -> DotLayer[], "softmax" -> SoftmaxLayer[],
"featureCat" -> CatenateLayer[2], "response" -> TotalLayer[], "classify" -> {LongShortTermMemoryLayer[32], SequenceLastLayer[], DropoutLayer[0.3], LinearLayer[], SoftmaxLayer[]}|>, {
NetPort["Question"] -> "question",
NetPort["Context"] -> "context1",
NetPort["Context"] -> "context2",
"question" -> "trans1",
{"context1", "trans1"} -> "featureMatch" -> "softmax",
{"softmax", "context2"} -> "response" -> "trans2",
{"trans2", "question"} -> "featureCat" -> "classify" -> NetPort["Answer"]
}, "Context" -> {maxContextLen, enc}, "Question" -> {maxQueryLen, enc}, "Answer" -> NetDecoder[{"Class", classes}]];Train the net using the "RMSProp" optimization method, which improves learning performance for this example:
result = NetTrain[memNet, traindata, All, MaxTrainingRounds -> 65, ValidationSet -> testdata, Method -> "RMSProp", BatchSize -> 32]
trainedNet = result["TrainedNet"]N@Count[trainedNet[KeyDrop[testdata, "Answer"]] - testdata["Answer"], 0] / Length[testdata["Answer"]]Character-Level Language Model
corpus = StringJoin[ResourceData["The American"], " ", ResourceData["Don Quixote - English"]];sampleCorpus[corpus_, len_, num_] := Module[
{positions = RandomInteger[{len + 1, StringLength[corpus] - 1}, num]},
Thread[StringTake[corpus, {# - len, #}& /@ positions] -> StringPart[corpus, positions + 1]]];
trainingData = sampleCorpus[corpus, 25, 300000];The data is of the form of a classification problem: given a sequence of characters, predict the next one. A sample of the data:
RandomSample[trainingData, 5]//Map[InputForm]//TableFormcharacters = Union[Characters[corpus]]net = NetChain[{UnitVectorLayer[], GatedRecurrentLayer[128], GatedRecurrentLayer[128], SequenceLastLayer[], LinearLayer[], SoftmaxLayer[]},
"Input" -> NetEncoder[{"Characters", characters}],
"Output" -> NetDecoder[{"Class", characters}]]Train the net. This can take up to an hour on a CPU, so use TargetDevice->"GPU" if you have an NVIDIA graphics card available. A modern GPU should be able to complete this example in about 7 minutes:
results = NetTrain[net, trainingData, All, ValidationSet -> Scaled[0.1], BatchSize -> 64, MaxTrainingRounds -> 10, TargetDevice -> "CPU"]trainedNet = results["TrainedNet"]trainedNet["Why are th"]Generate 100 characters of text, given a start text. Note that this method uses NetStateObject to efficiently generate long sequences of text:
generate[net_, start_, len_] := StringJoin@NestList[NetStateObject[net], start, len]generate[trainedNet, "Why are w", 100]generateSample[net_, start_, len_] := Block[{obj = NetStateObject[net]},
StringJoin@NestList[obj[#, "RandomSample"]&, start, len]]generateSample[trainedNet, "Why are w", 100]An alternative and equivalent formulation of this learning problem, requiring only a single string as input, is to separate the last character from the rest of the sequence inside the net.
Use SequenceMostLayer and SequenceLastLayer in a graph to separate the last character from the rest:
netAlt = NetGraph[
<|"rnn" -> net, "most" -> SequenceMostLayer[], "last" -> SequenceLastLayer[], "loss" -> CrossEntropyLossLayer["Index"]|>,
{NetPort["Input"] -> "most" -> "rnn" -> "loss",
NetPort["Input"] -> "last" -> NetPort["loss", "Target"]},
"Input" -> NetEncoder[{"Characters", characters}]]Train this net on the input sequences from the original training data (technically, this means you end up training the net on slightly shorter sequences):
result = NetTrain[netAlt, <|"Input" -> Keys[trainingData]|>, All, ValidationSet -> Scaled[0.1], BatchSize -> 64, MaxTrainingRounds -> 10]
netAltTrained = result["TrainedNet"]A more efficient way to train language models is to use "teacher forcing", in which the net simultaneously predicts the entire sequence, rather than just the last letter.
First, build the net that does prediction of an entire sequence at once. This differs from the previous prediction nets in that the LinearLayer is mapped and a matrix softmax is performed, instead of taking the last element and doing an ordinary vector softmax:
n = Length[characters];
predict = NetChain[{UnitVectorLayer[n], GatedRecurrentLayer[128], GatedRecurrentLayer[128], NetMapOperator[LinearLayer[n]], SoftmaxLayer[]}]Now build the forcing network, which takes a target sentence and presents it to the network in a "staggered" fashion: for a length-26 sentence, present characters 1 through 25 to the net so that it produces predictions for characters 2 through 26, which are compared with the real characters via the CrossEntropyLossLayer to produce a loss:
teacherForcingNet = NetGraph[
<|"predict" -> predict, "rest" -> SequenceRestLayer[], "most" -> SequenceMostLayer[], "loss" -> CrossEntropyLossLayer["Index"]|>,
{NetPort["Input"] -> "most" -> "predict" -> NetPort["loss", "Input"], NetPort["Input"] -> "rest" -> NetPort["loss", "Target"]},
"Input" -> NetEncoder[{"Characters", characters}]]Train the net on the input sequences from the original data. On a typical CPU, this should take around 15 minutes, compared to around 2 minutes on a modern GPU. As teacher forcing is a more efficient technique, you can afford to use a smaller number of training rounds:
result = NetTrain[teacherForcingNet, <|"Input" -> Keys[trainingData]|>, All, BatchSize -> 64, MaxTrainingRounds -> 5, TargetDevice -> "CPU", ValidationSet -> Scaled[0.1]]trained = NetExtract[result["TrainedNet"], "predict"]predictNet = NetJoin[
NetTake[trained, 3, "Input" -> Automatic],
{SequenceLastLayer[], NetExtract[trained, {4, "Net"}], SoftmaxLayer[]},
"Input" -> NetEncoder[{"Characters", characters}],
"Output" -> NetDecoder[{"Class", characters}]]predictNet["Why are th"]Generate 100 characters of text, given a start text. Note that this method uses NetStateObject to efficiently generate long sequences of text:
generate[predictNet, "It was ", 100]generateSample[predictNet, "Why are w", 100]