Working with String Patterns
Working with String Patterns
The general symbolic string patterns in the Wolfram Language allow you to perform powerful string manipulation efficiently. What follows discusses the details of string patterns, including usage and implementation notes. The emphasis is on issues not mentioned elsewhere in the help system.
At the heart of the Wolfram Language is a powerful language for describing patterns in general expressions. This language is used in function definitions, substitutions, and searches, with constructs like x_, ab, x.., and so on:
A Wolfram Language string pattern uses the same constructs to describe patterns in a text string. You can think of a string as a sequence of characters and apply the principles of general Wolfram Language patterns. In addition there are several useful string-specific pattern constructs:
Regular expressions can be used as an alternative way to specify string patterns. These tend to be more compact, but less readable:
| StringMatchQ["s",patt] | test whether s matches patt |
| StringFreeQ["s",patt] | test whether s is free of substrings matching patt |
| StringCases["s",patt] | give a list of the substrings of s that match patt |
| StringCases["s",lhs->rhs] | replace each case of lhs by rhs |
| StringPosition["s",patt] | give a list of the positions of substrings that match patt |
| StringCount["s",patt] | count how many substrings match patt |
| StringReplace["s",lhs->rhs] | replace every substring that matches lhs |
| StringReplaceList["s",lhs->rhs] | give a list of all ways of replacing lhs |
| StringSplit["s",patt] | split s at every substring that matches patt |
| StringSplit["s",lhs->rhs] | split at lhs, inserting rhs in its place |
A general string pattern is formed from pattern objects similar to the general pattern objects in the Wolfram Language. To join several string pattern objects, use the StringExpression operator ~~:
StringExpression is closely related to StringJoin, except nonstrings are allowed and lists are not flattened. For pure strings, they are equivalent:
The list of objects that can appear in a string pattern closely matches the list for ordinary Wolfram Language patterns. In terms of string patterns, a string is considered a sequence of characters, that is, "abc" can be thought of as something like String[a,b,c], to which the ordinary pattern constructs apply.
| "string" | a literal string of characters |
| _ | any single character |
| __ | any substring of one or more characters |
| ___ | any substring of zero or more characters |
| x_
,
x__
,
x___ | substrings given the name x |
| x:pattern | pattern given the name x |
| pattern.. | pattern repeated one or more times |
| pattern... | pattern repeated zero or more times |
| {patt1,patt2,…} or patt1patt2… | a pattern matching at least one of the patti |
| patt/;cond | a pattern for which cond evaluates to True |
| pattern?test | a pattern for which test yields True for each character |
| Whitespace | a sequence of whitespace characters |
| NumberString | the characters of a number |
| DatePattern[spec] | the characters of a date |
| charobj |
an object representing a character class (see below)
|
| RegularExpression["regexp"] | substring matching a regular expression |
| StringExpression[…] | an arbitrary string expression |
| {c1,c2,…} | any of the "ci" |
| Characters["c1c2…"] | any of the "ci" |
| CharacterRange["c1","c2"] | any character in the range "c1" to "c2" |
| HexadecimalCharacter | hexadecimal digit 0–9, a–f, A–F |
| DigitCharacter | digit 0–9 |
| LetterCharacter | letter |
| WhitespaceCharacter |
space, newline, tab, or other whitespace character
|
| WordCharacter | letter or digit |
| Except[p] | any character except ones matching p |
| StartOfString | start of the whole string |
| EndOfString | end of the whole string |
| StartOfLine | start of a line |
| EndOfLine | end of a line |
| WordBoundary | boundary between word characters and others |
| Except[WordBoundary] | anywhere except a word boundary |
| Shortest[p] | the shortest consistent match for p |
| Longest[p] | the longest consistent match for p (default) |
The _, __, and ___ wildcards match any characters including newlines. To match any character except newline (analogous to the "." in regular expressions), use Except["\n"], Except["\n"].., and Except["\n"]...:
A list of patterns, such as {"a","b","c"}, is equivalent to a list of alternatives, such as "a""b""c". This is convenient in that functions like Characters and CharacterRange can be used to specify classes of characters:
When Condition (/;) is used, the patterns involved are treated as strings as far as the rest of the Wolfram Language is concerned, so you need to use ToExpression in some cases:
Similar to ordinary Wolfram Language patterns, the function in PatternTest (?) is applied to each individual character:
You can insert a RegularExpression object into a general string pattern:
This inserts a lookbehind constraint (see "Regular Expressions") to ensure that you only pick words preceded by "the ":
StringExpression objects can be nested:
The Except construct for string patterns takes a single argument that should represent a single character or a class of single characters.
When trying to match patterns of variable length (such as __ and patt..), the longest possible match is tried first by default. To force the matcher to try the shortest match first, you can wrap the relevant part of the pattern in Shortest[ ]:
If for some reason you need a longest match within the short match, you can use Longest:
You could alternatively rewrite this pattern without use of Longest:
The regular expression syntax follows the underlying Perl Compatible Regular Expressions (PCRE) library, which is close to the syntax of Perl. (See [1] for further information and documentation.) A regular expression in the Wolfram Language is denoted by the head RegularExpression.
| c | the literal character c |
| . | any character except newline |
| [c1c2…] | any of the characters ci |
| [c1-c2] | any character in the range c1–c2 |
| [^c1c2…] | any character except the ci |
| p* | p repeated zero or more times |
| p+ | p repeated one or more times |
| p? | zero or one occurrence of p |
| p{m,n} | p repeated between m and n times |
| p*?
,
p+?
,
p?? | the shortest consistent strings that match |
| p*+
,
p++
,
p?+ | possessive match |
| (p1p2…) | strings matching the sequence p1, p2, … |
| p1p2 | strings matching p1 or p2 |
| \\d | digit 0–9 |
| \\D | nondigit |
| \\s |
space, newline, tab, or other whitespace character
|
| \\S | non‐whitespace character |
| \\w |
word character (letter, digit, or
_
)
|
| \\W | nonword character |
| [[:class:]] | characters in a named class |
| [^[:class:]] | characters not in a named class |
The following named classes can be used: alnum, alpha, ascii, blank, cntrl, digit, graph, lower, print, punct, space, upper, word, and xdigit.
| ^ |
the beginning of the string (or line)
|
| $ |
the end of the string (or line)
|
| \\A | the beginning of the string |
| \\z | the end of the string |
| \\Z |
the end of the string (allowing for a single newline character first)
|
| \\b | word boundary |
| \\B | anywhere except a word boundary |
| (?i) |
treat uppercase and lowercase as equivalent (ignore case)
|
| (?m) | make ^ and $ match start and end of lines (multiline mode) |
| (?s) | allow . to match newline |
| (?x) | disregard all whitespace and treat everything between "#" and "\n" as comments |
| (?-∖#c) | unset options |
| (?=p) | the following text must match p |
| (?!p) | the following text cannot match p |
| (?<= p) | the preceding text must match p |
| (?<!p) | the preceding text cannot match p |
With the possessive "+" quantifier, as many characters as possible are grabbed by the matcher, and no characters are given up, even if the rest of the patterns require it:
The complete list of characters that need to be escaped in a regular expression consists of ., \, ?, (, ), {, }, [, ], ^, $, *, +, and . For instance, to write a literal period, use "\\." and to write a literal backslash, use "\\\\".
By default, ^ and $ match the beginning and end of the string, respectively. In multiline mode, these match the beginning/end of lines instead:
The (?x) modifier allows you to add whitespace and comments to a regular expression for readability:
Named subpatterns are achieved by surrounding them with parentheses (subpatt); they then become numbered subpatterns. The number of a given subpattern counts the opening parenthesis, starting from the start of the pattern. You can refer to these subpatterns using \\n for the n th pattern later in the pattern, or by "$n" in the right-hand side of a rule. "$0" refers to all of the matched pattern:
If you need a literal $ in this context (when the head of the left-hand side is RegularExpression), you can escape it by using backslashes (for example, "\\$2"):
If you happen to need a single literal backslash followed by a literal $ under these circumstances, you need to be a bit tricky and split into two strings temporarily:
If you need to group a part of the pattern, but you do not want to count the group as a numbered subpattern, you can use the (?:patt) construct:
Lookahead and lookbehind patterns are used to ensure a pattern is matched without actually including that text as part of the match.
This tries to pick out all even numbers in the string, but it will find matches that include partial numbers:
Using lookbehind/lookahead, you can ensure that the characters before/after the match are not digits (note that the lookbehind test is superfluous in this particular case):
There is a close correspondence between the various pattern objects that can be used in general symbolic string patterns and in regular expressions. Here is a list of examples of patterns written as regular expressions and as symbolic string patterns.
regular expression | general string pattern | explanation |
| "abc" | "abc" | the literal string "abc" |
| "." | Except["\n"] | any character except newline |
| "(?s)." | _ | any character |
| "(?s).+" | __ |
one or more characters (greedy)
|
| "(?s).+?" | Shortest[__] |
one or more characters (nongreedy)
|
| "(?s).*" | ___ | zero or more characters |
| ".*" | Except["\n"]... |
zero or more characters (except newlines)
|
| "a?b" | "a"""~~"b" | zero or one "a" followed by a "b" (that is, "b" or "ab") |
| "[abef]" | Characters["abef"] | any of the characters "a", "b", "e", or "f" |
| "[abef]+" | Characters["abef"].. | one or more of the characters "a", "b", "e", or "f" |
| "[a-f]" | CharacterRange["a","f"] | any character in the range between "a" and "f" |
| "[^abef]" | Except[Characters["abef"]] | any character except the characters "a", "b", "e", or "f" |
| "abefg" | "ab""efg" | match the strings "ab" or "efg" |
| "(abef)gh" or "(?:abef)gh" | ("ab""ef")~~"gh" | "ab" or "ef" followed by "gh" (that is, "abgh" or "efgh") |
| "\\s" | WhitespaceCharacter | any whitespace character |
| "\\s+" | Whitespace | one or more characters of whitespace |
| "(ab)\\1" | x:"a""b"~~x_ | this will match either "aa" or "bb" |
| "\\d" | DigitCharacter | any digit character |
| "\\D" | Except[DigitCharacter] | any nondigit character |
| "\\d+" | DigitCharacter.. | one or more digit characters |
| "\\w" | WordCharacter"_" | any digit, letter, or "_" character |
| "[[:alpha:]]" | LetterCharacter | any letter character |
| "[^[:alpha:]]" | Except[LetterCharacter] | any nonletter character |
| "^abf" or "\\Aabc" | StartOfString~~"abf" | the string "abf" at the start of the string |
| "(?m)^abf" | StartOfLine~~"abf" | the string "abf" at the start of a line |
| "wxz$" or "wxz\\z" | "wxz"~~EndOfString | the string "wxz" at the end of the string |
| "wxz\\Z" | "wxz"~~"\n"""~~EndOfString | the string "wxz" at the end of the string or before newline at the end of the string |
Pattern objects that can be used in general string patterns, but not in regular expressions, include conditions (/;) and pattern tests (?) that can access general Wolfram Language code during the match.
Some special constructs in regular expressions are not directly available in general string patterns. These include lookahead/lookbehinds and repeats of a given length. They can be embedded into a larger general string pattern by inserting a RegularExpression object.
The following discusses some particulars and subtleties in the various string manipulation functions (see the reference pages for more information on these functions).
StringMatchQ
StringMatchQ is used to check whether a whole string matches a certain pattern:
StringMatchQ is special in that it also allows the metacharacters * and @ to be entered as wildcards (for backward compatibility reasons). * is equivalent to Shortest[___] (RegularExpression["(?s).*?"]) and @ is equivalent to Except[CharacterRange["A","Z"]] (RegularExpression["[^A-Z]"]).
Note that technically the appearance of Shortest does not make a difference here, since we are only looking for a possible match.
If you need to access parts of the string matched by subpatterns in the pattern, use StringCases instead.
StringMatchQ has a SpellingCorrection option for finding matches allowing for a small number of discrepancies. This only works for patterns consisting of a single literal string:
StringFreeQ
StringFreeQ is used to check whether a string contains a substring matching the pattern. You cannot extract the matching substring; to do this you would use StringCases:
StringContainsQ
StringContainsQ is used to check whether a string contains a substring matching the pattern. You cannot extract the matching substring; to do this you would use StringCases:
StringStartsQ
StringStartsQ is used to check whether a string starts with a substring matching the pattern. You cannot extract the matching substring; to do this you would use StringCases:
StringEndsQ
StringEndsQ is used to check whether a string ends with a substring matching the pattern. You cannot extract the matching substring; to do this you would use StringCases:
StringCases
StringCases is a general purpose function for finding occurrences of patterns in a string, picking out subpatterns, and processing the results.
You can also give a list of strings as the first argument for efficient processing of many strings (see "Tips and Tricks for Efficient Matching" for a discussion):
The Overlaps Option
The Overlaps option for StringCases, StringPosition, and StringCount deals with how the matcher proceeds after finding a match. It has three possible settings: False, True, or All. The default is False for StringCases and StringCount, while it is True for StringPosition.
With Overlaps->False, the matcher continues the match testing at the character following the last matched substring:
With Overlaps->True, the matcher continues at the character following the first character of the last matched substring (when a single pattern is involved):
With Overlaps->All, the matcher keeps starting at the same position until no more new matches are found:
If multiple patterns are given in a list, Overlaps->True will cause the matcher to start at the same position once for each of the patterns before proceeding to the next character:
Note that with Overlaps->True, there can thus be a difference between specifying a list of patterns and using the alternatives operator ():
StringPosition
StringPosition works much like StringCases, except the positions of the matching substrings are returned:
StringCount
StringCount returns the number of matching substrings (which are found by StringPosition or StringCases). It is useful for cases with many matches where memory for storing all the substrings might be an issue:
StringReplace
StringReplace is used for substituting substrings matching the given patterns:
Named patterns can be used as strings on the right-hand side of the replacement rules. Note the use of RuleDelayed () to avoid premature evaluation:
When using regular expressions, it is convenient to remember that "$0" on the right-hand side refers to the whole matched substring:
Note that the replacement does not have to be a string. If the result is not a string, a StringExpression is returned:
There is limited support for using the old MetaCharacters option in conjunction with general string patterns, but this option is deprecated and its use should be avoided.
StringReplaceList
StringReplaceList returns a list of strings where a single string replacement has been made in all possible ways:
StringSplit
StringSplit is useful for splitting a string into many strings at delimiters matching a pattern. By default, the splits happen at runs of whitespace:
For instance, to split a normal sentence into words, you need to also include punctuation in the delimiter:
These can be included by specifying All as a third argument:
You can also split at patterns that match positions, such as StartOfLine. This keeps the newline characters in the result:
You can keep the delimiters, or parts of the delimiters, in the output by using a rule as the second argument:
You can give a list of patterns and rules as well; the delimiters matching the patterns will be left out of the result:
Overview
With the addition of general string patterns, the Wolfram Language can be a powerful alternative to languages like Perl and Python for many general, everyday programming tasks. For people familiar with Perl syntax, and the way Perl does string manipulation, the following rough guide shows how to get similar functionality in the Wolfram Language.
Perl construct | Wolfram Language function | explanation |
| m/ .../ | StringFreeQ or StringCases |
match a string with a regular expression, possibly extracting subpatterns
|
| s/ .../ .../ | StringReplace | replace substrings matching a regular expression |
| split(...) | StringSplit | split a string at delimiters matching a regular expression |
| tr/ .../ .../ | StringReplace | replace characters by other characters |
| /i | IgnoreCase->True or "(?i)" | case-insensitive modifier |
| /s | "(?s)" | force "." to match all characters (including newlines) |
| /x | "(?x)" | ignore whitespace and allow extended comments in regular expression |
| /m | "(?m)" | multiline mode ("^" and "$" match start/end of lines) |
m/.../
The match operator m/regex/ tests whether a string contains a substring matching the regex. For simple matches of this sort in the Wolfram Language, use StringFreeQ.
If parts of the matched string need to be accessed later, using 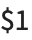 ,
, 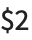 , … in Perl, the best Wolfram Language function to use is normally StringCases.
, … in Perl, the best Wolfram Language function to use is normally StringCases.
In the Wolfram Language, this is done with StringCases:
The same thing is easily done with StringCases in the Wolfram Language:
s/.../.../
Using the evaluation  modifier, Perl can use subpatterns as part of the replacement. This is easily done in the Wolfram Language:
modifier, Perl can use subpatterns as part of the replacement. This is easily done in the Wolfram Language:
split(...)
A  with capturing parentheses in the pattern, for which the captured substrings are included in the result, can be done in the Wolfram Language using rules in the second argument of StringSplit. Compared to Perl, in the Wolfram Language it is easy to then apply a function to these substrings:
with capturing parentheses in the pattern, for which the captured substrings are included in the result, can be done in the Wolfram Language using rules in the second argument of StringSplit. Compared to Perl, in the Wolfram Language it is easy to then apply a function to these substrings:
tr/.../.../
The Perl  command can be simulated using Wolfram Language StringReplace together with the appropriate list of rules.
command can be simulated using Wolfram Language StringReplace together with the appropriate list of rules.
This generates the appropriate rules in the Wolfram Language using Thread:
Here is an example where the replacement list is shorter than the character list, so  ,
,  , and
, and  are all replaced by
are all replaced by  :
:
Character ranges in Perl are emulated using CharacterRange in the Wolfram Language:
Highlight Patterns
HTML Parsing
Here is the source from www.google.com:
Find Money
Here is the same search using regular expressions (note that you must remember to escape the dollar sign):
There is also a built-in pattern object, NumberString, for this particular situation:
Find Text in Files
Here is a very simple grep-like function for finding lines in a text file containing text matching a given pattern:
StringExpression versus RegularExpression
Since a string pattern written in Wolfram Language syntax is immediately translated to a regular expression and then compiled and cached, there is very little overhead in using the Wolfram Language syntax as opposed to the regular expression syntax directly. An exception to this happens when many different patterns are used a few times; in that case the overhead might be noticeable.
Conditions and PatternTests
If a pattern contains Condition (/;) or PatternTest (?) statements, the general Wolfram Language evaluator must be invoked during the match, thus slowing it down. If a pattern can be written without such constructs, it will typically be faster:
Avoid Nested Quantifiers
Because of the nondeterministic finite automaton (NFA) algorithm used in the match, patterns involving nested quantifiers (such as __ and patt.. or the regular expression equivalents) can become arbitrarily slow. Such patterns can usually be "unrolled" into more efficient versions (see Friedl [2] for additional information).
Avoid Many Calls to a Function
If you are searching through a long list of strings for certain matches, it is more efficient to feed the whole list to a string function at once, rather than using something like Select and StringMatchQ (see the earlier dictionary example for an illustration). Here is another example that generates a list of 2000 strings with 10 characters each and searches for the strings that start with an "a" and contain "ggg" as a substring:
If you instead feed the whole list to StringMatchQ at once, it will be much faster. Then Pick can be used to extract the wanted elements:
Alternatively, you could use StringCases, which is also fast. Note that you need to anchor the pattern using StartOfString to ensure that the "a" is at the start (the EndOfString is superfluous in this particular case):
Rewrite General Expression Searches as String Searches
Because the string-matching algorithm is different than the algorithm the Wolfram Language uses for general expression matching (string matching can assume a finite alphabet and a flat structure, for instance), there are cases where it is advantageous to translate a normal expression-matching problem to a string-matching problem. A typical case is matching a long list of symbols against a pattern involving several occurrences of __ and ___.
As an example, assume you want to find primes (after prime number 1000000, say) that have at least four identical digits. Using ordinary pattern matching, it could be accomplished like this:
String pattern matching in the Wolfram Language is built on top of the PCRE (Perl Compatible Regular Expressions) library by Philip Hazel [1].
In some cases the pre-5.1 Wolfram Language algorithms are used (for example, when the pattern is just a single, literal string).
Any symbolic string pattern is first translated to a regular expression. You can see this translation by using the internal StringPattern`PatternConvert function:
The first element returned is the regular expression, while the rest of the elements have to do with conditions, replacement rules, and named patterns.
The regular expression is then compiled by PCRE, and the compiled version is cached for future use when the same pattern appears again. The translation from symbolic string pattern to regular expression only happens once.
Wolfram Language conditions in the pattern are handled by external call-outs from the PCRE library to the Wolfram Language evaluator, so this will slow down the matching.
Explicit RegularExpression objects embedded into a general string pattern will be spliced into the final regular expression (surrounded by noncapturing parentheses "(?:...)"), so the counting of named patterns can become skewed compared to what you might expect.
Because PCRE currently does not support preset character classes with characters beyond character code 255, the word and letter character classes (such as WordCharacter and LetterCharacter) only include character codes in the Unicode range 0–255. Thus LetterCharacter and _?LetterQ do not give equivalent results beyond character code 255.
Because of a similar PCRE restriction, case-insensitive matching (for example, with IgnoreCase->True) will only apply to letters in the Unicode range 0–127 (that is, the normal English letters "a"–"z" and "A"–"Z").
[1] Hazel, P. "PCRE—Perl Compatible Regular Expressions." 2004. www.pcre.org
[2] Friedl, J. E. F. Mastering Regular Expressions, 2nd ed. O'Reilly & Associates, 2002.