

AttentionLayer
入力のある部分に注意を払うことを学ぶ,訓練可能なネット層を表す.
AttentionLayer[net]
入力のある部分にスコアを与える特定のネットを指定する.
AttentionLayer[net,opts]
重みの正規化,マスキング,その他のパラメータのためのオプションを含む.
詳細とオプション






- AttentionLayer[net]は,キーベクトルの集合,値ベクトルの集合,1つあるいは複数のクエリベクトルを取り,net[<"Input"key,"Query"query>]からのソフトマックス正規化されたスコアを使って各クエリベクトルについて値ベクトルの加重和を計算する.
- AttentionLayer[net]は,その一般的な単一の頭部を持つ形式で,次元 d1×…×dn×k のキー配列K,次元 d1×…×dn×v の値の配列V,次元 q1×…×qm×q のクエリ配列Qを取る.キー配列と値配列は,要素がベクトルのサイズ d1×…×dnの配列と見ることができる.Kについては,これらのベクトルはサイズ k の k で表され,Vについては,これらのベクトルはサイズ v の v で表される.同様に,クエリ配列は,要素がサイズ q のqで表されるベクトルであるサイズ q1×…×qm の配列と見ることができる.クエリ配列は,m が0ならサイズ q の単一のクエリベクトルでよい点に注意のこと.したがって,d1×…×dn キーベクトルkと q1×…×qm クエリベクトルqの各計算にスコアリングネット f を使ってスケールスコア s=f(k,q)が計算される.これらのスカラースコアを使って加重和 o=
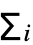 wiviを含むサイズ q1×…×qmの出力配列Oが生成される.ただし,重みは w=softmax(S)でSは指定のクエリベクトルについて生成された d1×…×dn スカラースコアの配列である.
wiviを含むサイズ q1×…×qmの出力配列Oが生成される.ただし,重みは w=softmax(S)でSは指定のクエリベクトルについて生成された d1×…×dn スカラースコアの配列である. - AttentionLayer[net]は,一般的に,キーがサイズ n×k の行列,値がサイズ n×v の行列で,クエリがサイズ q の単一のベクトルのときに使われることが多い.このとき,AttentionLayerは n 値の行ベクトルの加重和 o=
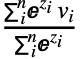 (ただし zi=f(ki,q))である単一の出力ベクトル o を計算する.Wolfram言語では,これは Total[values*weights]と書くことができる.ただし,weights はSoftmaxLayer[][Map[net[<"Input"#,"Query"query>]&,keys]]である.
(ただし zi=f(ki,q))である単一の出力ベクトル o を計算する.Wolfram言語では,これは Total[values*weights]と書くことができる.ただし,weights はSoftmaxLayer[][Map[net[<"Input"#,"Query"query>]&,keys]]である. - AttentionLayer[net]のスコアリングネットワーク net は以下のいずれかでよい.
-
"Dot" s=Dot[k,q]を計算するNetGraph "Bilinear" s=Dot[k,W,q]を計算するNetGraph.ただし,W は学習可能行列である(デフォルト) NetGraph[…] "Input"ベクトルおよび "Query"ベクトルを取ってスカラーの"Output"値を生成する特定のNetGraph - 次の選択的パラメータを含めることができる.
-
"Dropout" 0 注意の重みについてのドロップアウト率 LearningRateMultipliers Automatic スコアリングネットワークの学習率乗数 "Mask" None 注意の特定のパターンを阻止する "MultiHead" False 頭部が複数の注意を行うかどうか.ただし,最後から2番目の次元は別の頭部に対応する "ScoreRescaling" None スコアをスケールするためのメソッド - 次は"Mask"の可能な設定である.
-
None マスキングなし "Causal" 因果マスキング "Causal"n ウィンドウサイズが n の局所的因果マスキング - "Dropout"p を指定すると確率 p のドロップアウトが注意の重みに適用される.ここで,p は0を含んで0から1まで(1は含まない)のスカラーである.
- "Mask""Causal"の設定のとき,クエリ入力はキーと同じ長さのベクトルと値の入力の連続に限られ,キーと値の入力で t'<=t の位置だけが位置 t の出力の計算に使われる.
- "Mask""Causal"n(n は正の整数)の設定では,キーと値の入力の t-n<t'<=t の位置だけが位置 t の出力の計算に使われる.
- "MultiHead"Trueの設定では,キーと値の入力は少なくとも階数3,クエリ入力は少なくとも階数2で,最後から2番目の次元は注意の頭部を表しすべての入力に対して同じでなければならない.注意の各頭部は独特の注意メカニズムに対応し,全頭部の出力が結合される.
- "ScoreRescaling""DimensionSqrt"の設定では,ソフトマックス
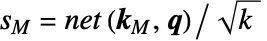 による正規化の前に,スコアがキーの入力次元の平方根で分割される.
による正規化の前に,スコアがキーの入力次元の平方根で分割される. - AttentionLayerはNetGraphの中で使われることが多い.
- AttentionLayerは,NetGraph等の中で使うために次の入力ポートを開放する.
-
"Key" サイズ d1×…×dn×k の配列(あるいは多頭部の注意がある d1×…×dn×h×k) "Value" サイズ d1×…×dn×v の配列(あるいは多頭部の注意がある d1×…×dn×h×k) "Query" サイズ q1×…×qm×q の配列(あるいは多頭部の注意がある q1×…×qm×h×k) - AttentionLayerは,NetGraph等の中で使うために次の出力ポートを開放する.
-
"Output" 次元 q1×…×qm×v の出力の配列(あるいは多頭部の注意がある q1×…×qm×h×v) - AttentionLayerは内部の注意の重みにアクセスするために追加のポートを開放する.
-
"AttentionWeights" 次元 d1×…×dn×q1×…×qm(あるいは多頭部の注意がある d1×…×dn×h×q1×…×qm)の重みの配列 - AttentionLayer[…,"Key"->shape1,"Value"->shape2,"Query"->shape3]で入力の形状が指定できる.shapeiの使用可能な形状には以下がある.
-
NetEncoder[…] 一連の配列を生成するエンコーダ {d1,d2,…} 次元 d1×d2×…の配列 {"Varying",d1,d2,…} 最初の次元が可変で残りの次元が d1×d2×…の配列 {Automatic,…} 次元が推測される配列 {"Varying",Automatic,…} それぞれサイズが推測された,さまざまな数の配列 - キー,値,クエリ配列の大きさは,大抵の場合,NetGraph内で自動的に推測される.
- AttentionLayer[…][<"Key"key,"Value"value,"Query"query>]は層を適用して出力を明示的に計算する.
- AttentionLayer[…][<"Key"{key1,key2,…},"Value"{value1,value2,…},"Query"{query1,query2,…}>]は,入力バッチ内の keyi,valuei,queryiのそれぞれについて出力を明示的に計算する.
- AttentionLayer[…][input,NetPort["AttentionWeights"]]を使って特定の入力についてのソフトマックス正規化されたスコアにアクセスできる.
- NumericArrayが入力内で与えられると,出力はNumericArrayになる.
- NetExtract[…,"ScoringNet"]を使ってAttentionLayer[net]オブジェクトから net が抽出できる.
- Options[AttentionLayer]は層を構築する際のデフォルトオプションのリストを与える.Options[AttentionLayer[…]]はデータについて層を評価する際のデフォルトオプションのリストを与える.
- Information[AttentionLayer[…]]は層についてのレポートを与える.
- Information[AttentionLayer[…],prop]はAttentionLayer[…]の特性 prop の値を与える.使用可能な特性はNetGraphと同じである.
例題
すべて開く すべて閉じる例 (2)
AttentionLayerを作る:
二次元のキーの列,三次元の値,一次元のクエリの列を取る,ランダムに初期化されたAttentionLayerを作る:
スコープ (4)
スコアリングネット (2)
"Dot"スコアリングネットを使ってAttentionLayerを作る:
スコアリングネットをNetGraphオブジェクトとして明示的に指定して,新たなAttentionLayerを作る:
カスタムのスコアリングネットを利用するAttentionLayerを作り初期化する:
注意の重み (2)
AttentionLayerを作成する:
AttentionLayerに基づいたモデルを取る:
このネットは,例えば12の頭部がある,いくつかの多頭自己注意層を含んでいる:
オプション (7)
"Dropout" (1)
注意の重みのマスキングについてのドロップアウトがあるAttentionLayerを定義する:
訓練特有の動作がなければ,この層はドロップアウトがない場合と同じ結果を返す:
NetEvaluationMode"Train"とすると,この層は別の結果を返す:
LearningRateMultipliers (1)
このスコアリングネットを,オプションLearningRateMultipliersで重みをフリーズしてAttentionLayerで使う:
"Mask" (2)
因果マスキングでAttentionLayerを定義する:
指定されたステップにおける出力はそのステップまでのキーと値にのみ依存する.特に,最初の出力ベクトルは値の最初のベクトルである.
ウィンドウサイズ3の局所的因果マスキングを持つAttentionLayerを定義する:
1つのクエリベクトルおよび長さ5の列を持つ注意層を適用する:
"MultiHead" (2)
2つの頭部を持つAttentionLayerを定義する:
結果は単頭の注意層を各頭部に別々に適用して結果を結合したものと同じである:
6つの頭部による多頭自己注意を実行するためのNetGraphを定義する:
長さが3の列を持つNumericArrayに適用する:
"ScoreRescaling" (1)
入力次元について注意スコアを再スケールするAttentionLayerを作る:
アプリケーション (1)
数のリストをソートするために,1から6までの整数のリストからなる検定集合と訓練集合を生成する:
AttentionLayerでNetGraphを定義する:
特性と関係 (4)
クエリ,キー,値の入力が行列の場合は,AttentionLayer[net]は計算を行う:
AttentionLayerを定義し,スコアリングサブネットを抽出する:
いくつかの検定データについてAttentionLayerを評価する:
AttentionLayer[net,"ScoreRescaling""DimensionSqrt"]は計算を行う:
AttentionLayerを定義し,スコアリングサブネットを抽出する:
いくつかの検定データについてAttentionLayerを評価する:
AttentionLayer[scorer,"Mask""Causal","ScoreRescaling""DimensionSqrt"]は計算を行う:
AttentionLayerを定義し,スコアリングサブネットを抽出する:
いくつかの検定データについてAttentionLayerを評価する:
"Key"入力と"Value"入力が同じなら,AttentionLayerはサポートされなくなったSequenceAttentionLayerと同じである:
考えられる問題 (1)
AttentionLayer[net]のスコアリングネット net に"Dot"の設定を使うときは,入力キーとクエリベクトルが同じサイズでなければならない:
テキスト
Wolfram Research (2019), AttentionLayer, Wolfram言語関数, https://reference.wolfram.com/language/ref/AttentionLayer.html (2022年に更新).
CMS
Wolfram Language. 2019. "AttentionLayer." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2022. https://reference.wolfram.com/language/ref/AttentionLayer.html.
APA
Wolfram Language. (2019). AttentionLayer. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/AttentionLayer.html