Fit
Fit[data,{f1,…,fn},{x,y,…}]
変数{x,y,…}の関数 f1,…,fnについての data のリストに対するフィット a1 f1+…+an fnを求める.
Fit[{m,v}]
計画行列 m について![]() を最小化するフィットベクトル a を求める.
を最小化するフィットベクトル a を求める.
Fit[…,"prop"]
どのフィット特性 prop を返すべきかを指定する.
詳細とオプション




- Fitは,線形回帰あるいは最小二乗フィットとしても知られている.正則化では,LASSO回帰およびリッジ回帰としても知られている.
- Fitは,一般に,多項式や指数関数を含む関数の組合せをデータにフィットする際に使用される.これは,データからモデルを得る最も簡単な方法の一つを提供する.
- 最適フィットは,平方の和
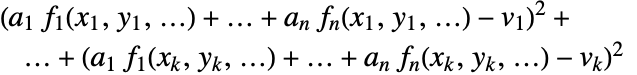 を最小にする.
を最小にする. - data は次の形式でよい.
-
{v1,…,vn} {{1,v1},…,{n,vn}}と同等 {{x1,v1},…,{xn,vn}} 座標 xiにおける値 viを持った一変量データ {{x1,y1,v1},…} 値 vi と座標{xi,yi}を持った二変量データ {{x1,y1,…,v1},…} 座標{xi,yi,…}における値 viを持った多変量データ - 計画行列 m は座標位置で関数を評価して得られる要素
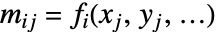 を持つ.行列表現では,最適フィットはノルム
を持つ.行列表現では,最適フィットはノルム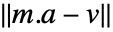 を最小化する.ただし,
を最小化する.ただし,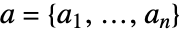 かつ
かつ 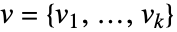 である.
である. - 関数 fi が依存するのは変数{x,y,…}だけでなければならない.
- 可能なフィット特性"prop"には次がある.
-
"BasisFunctions" funs 基底関数 "BestFit" 
基底関数の最適フィット線形結合 "BestFitParameters" 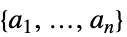
最適フィットを与えるベクトル 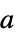
"Coordinates" {{x1,y1,…},…} data 中の vars の座標 "Data" data データ "DesignMatrix" m 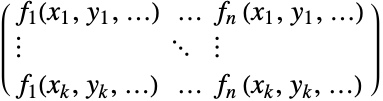
"FitResiduals" 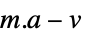
座標におけるモデルとフィットの差 "Function" Function[{x,y,…},a1 f1+…+an fn] 最適フィット純関数 "PredictedResponse" 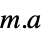
data 座標についてフィットされた値 "Response" 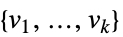
入力 data からの応答ベクトル 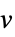
{"prop1","prop2",…} いくつかのフィット特性 - Fitは次のオプションを取る.
-
NormFunction Norm 最小化する偏差の測定値 FitRegularization None フィットパラメータ 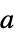 についての正規化
についての正規化WorkingPrecision Automatic 使用精度 - NormFunction->normf かつFitRegularization->rfun のとき,Fitは normf[{a.f(x1,y1,…)-v1,…,a.f(xk,yk,…)-vk}] + rfun[a]を最小化する係数 a ベクトルを求める.
- NormFunctionの設定は次の形式で与えることができる.
-
normf 偏差に適用される関数 normf {"Penalty", pf} 偏差の各成分に適用されたペナルティ関数 pf の和 {"HuberPenalty",α} 各成分についてのHuberペナルティ関数の和 {"DeadzoneLinearPenalty",α} 各成分についてのデッドゾーン線形ペナルティ関数の和 - FitRegularizationの設定は次の形式で与えることができる.
-
None 正規化は行わない rfun rfun[a]による正規化 {"Tikhonov",λ} 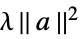 による正規化
による正規化{"LASSO",λ} 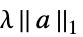 による正規化
による正規化{"Variation",λ} ![lambda||TemplateBox[{Differences, paclet:ref/Differences}, RefLink, BaseStyle -> {2ColumnTableMod}][a]||^2](Files/Fit.ja/19.png "lambda||TemplateBox[{Differences, paclet:ref/Differences}, RefLink, BaseStyle -> {2ColumnTableMod}][a]||^2") による正規化
による正規化{"TotalVariation",λ} ![lambda||TemplateBox[{Differences, paclet:ref/Differences}, RefLink, BaseStyle -> {2ColumnTableMod}][a]||_1](Files/Fit.ja/20.png "lambda||TemplateBox[{Differences, paclet:ref/Differences}, RefLink, BaseStyle -> {2ColumnTableMod}][a]||_1") による正規化
による正規化{"Curvature",λ} ![lambda||TemplateBox[{Differences, paclet:ref/Differences}, RefLink, BaseStyle -> {2ColumnTableMod}][a,2]||^2](Files/Fit.ja/21.png "lambda||TemplateBox[{Differences, paclet:ref/Differences}, RefLink, BaseStyle -> {2ColumnTableMod}][a,2]||^2") による正規化
による正規化{r1,r2,…} r1,…の項目の和による正規化 - WorkingPrecision->Automaticのとき,Fitへの入力として与えられた厳密数は機械精度の近似数に変換される.
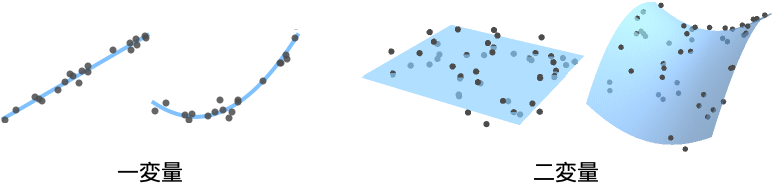
例題
すべて開くすべて閉じる例 (2)
スコープ (2)
オプション (6)
FitRegularization (2)
NormFunction (3)
アプリケーション (6)
チェビシェフ(Chebyshev)基底を使ってデータへの高次多項式フィットを計算する:
正規化を使って ![]() が摂動する場合の
が摂動する場合の ![]() の
の ![]() に対する数値解を安定させる:
に対する数値解を安定させる:
LinearSolveによって求まった解には非常に大きい項がある:

正規化なしでは,予想された応答は信号に非常に近いが,計算された入力には大きな振動がある:
残差のノルムと変動のノルムの間のトレードオフをプロットする:
全変動の正規化を使ってジャンプがある破損信号を滑らかにする:
![]() の値を小さくするとあまり滑らかではなくなるが,残差ノルムは小さくなる:
の値を小さくするとあまり滑らかではなくなるが,残差ノルムは小さくなる:
LASSO (L1)正規化を使って疎なフィット(基底追跡)を求める:
目標は,何千とあるGabor基底関数のいくつかを使って信号を近似することである:
![]() のときのフィットは基底要素のたった41個を使って求めることができる:
のときのフィットは基底要素のたった41個を使って求めることができる:
基底の重要な要素が見付かったら,これらの要素の最小二乗フィットを求めることで誤差を小さくすることができる:
特性と関係 (5)
Fitは最適フィットの関数を与える:
LinearModelFitはフィットに関する追加的な情報の抽出を許す:
以下はFitで与えられる係数である:
厳密係数はWorkingPrecision->Infinityを使うと求まるかもしれない:
これは,二次方程式a+b x+c x^2の誤差の平方和である:
これらはFitで与えられる係数である:
多項式のフィットが十分高い次数で行われるとき,Fitは補間多項式を返す:
結果はInterpolatingPolynomialで返されるものと矛盾しない:
Fit は,TimeSeriesのタイムスタンプを変数として使う:
Fitは,複数の経路があるTemporalDataについては,経路ごとに作用する:
テキスト
Wolfram Research (1988), Fit, Wolfram言語関数, https://reference.wolfram.com/language/ref/Fit.html (2019年に更新).
CMS
Wolfram Language. 1988. "Fit." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2019. https://reference.wolfram.com/language/ref/Fit.html.
APA
Wolfram Language. (1988). Fit. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/Fit.html