KernelMixtureDistribution
KernelMixtureDistribution[{x1,x2,…}]
データ値 xiに基づいたカーネル混合分布を表す.
KernelMixtureDistribution[{{x1,y1,…},{x2,y2,…},…}]
データ値{xi,yi,…}に基づいた多変量カーネル混合分布を表す.
KernelMixtureDistribution[…,bw]
帯域幅が bw のカーネル混合分布を表す.
KernelMixtureDistribution[…,bw,ker]
帯域幅が bw,平滑化カーネルが ker のカーネル混合分布を表す.
詳細とオプション



- KernelMixtureDistributionは他の確率分布と同じように使えるDataDistributionオブジェクトを返す.
- 値
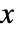 についてのKernelMixtureDistributionの確率密度関数は,平滑化カーネル
についてのKernelMixtureDistributionの確率密度関数は,平滑化カーネル 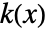 ,帯域幅母数
,帯域幅母数 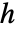 では
では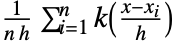 で与えられる.
で与えられる. - 使用可能な帯域幅指定 bw
-
h 使用する帯域幅 {"Standardized",h} 標準偏差の単位による帯域幅 {"Adaptive",h,s} 初期帯域幅 h,感度 s の適応的帯域幅 Automatic 自動計算された帯域幅 "name" 名前付き帯域幅選択法を使う {bwx,bwy,…} x, y 等に別々の帯域幅指定 - 多変量密度については,h は正定値対称行列でもよい.
- 適応的帯域幅については,感度 s は0から1までの実数あるいはAutomaticでなければならない.Automaticの場合,s は
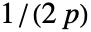 に設定される.ただし,
に設定される.ただし,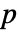 はデータの次元である.
はデータの次元である. - 使用可能な名前付き帯域幅選択法
-
"LeastSquaresCrossValidation" 最小二乗交差検定法を使う "Oversmooth" 標準Gaussianの1.08倍広い "Scott" Scottの規則を使った帯域幅選択 "SheatherJones" Sheather–Jonesプラグイン推定器を使う "Silverman" Silvermanの規則を使った帯域幅の決定 "StandardDeviation" 帯域幅として標準偏差を使う "StandardGaussian" 標準正規データの最適帯域幅 - デフォルトで"Silverman"メソッドが使われる.
- 帯域幅の自動計算では,定配列が単位分散を持つものとみなされる.
- 次のカーネル指定 ker が使える.
-
"Biweight" 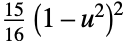
"Cosine" 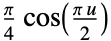
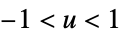
"Epanechnikov" 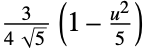
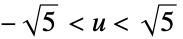
"Gaussian" 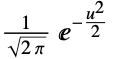
"Rectangular" 
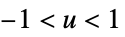
"SemiCircle" 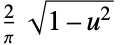
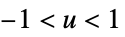
"Triangular" 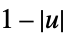
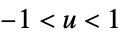
"Triweight" 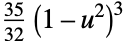
func 

- KernelMixtureDistributionが真の密度推定を生成するためには,関数 fn は有効な一変量確率密度関数でなければならない.
- デフォルトで"Gaussian"カーネルが使われる.
- 多変量密度については,カーネル関数 ker は積およびラジアルタイプとしてそれぞれ{"Product",ker}と{"Radial",ker}を使って指定することができる.積タイプのカーネルはタイプの指定がない場合に使われる.
- 密度推定に使われる精度は bw とデータで与えられる最低精度である.
- 使用可能なオプション
-
MaxMixtureKernels Automatic 使用するカーネルの最大数 - KernelMixtureDistributionはMean,CDF,RandomVariate等の関数で使うことができる.
例題
すべて開くすべて閉じる例 (3)
スコープ (47)
基本的な用法 (8)
分布特性 (10)
帯域幅の選択 (19)
感度をAutomaticに設定すると![]() が使われる.ただし,
が使われる.ただし,![]() はデータの次元である:
はデータの次元である:
スカラー h を与えると事実上 h IdentityMatrix[p]が使われる:
対角要素 d を指定すると事実上DiagonalMatrix[d]が使われる:
デフォルトで各次元に別々に帯域幅を選ぶのにはSilvermanメソッドが使われる:
別々に対角の帯域幅要素を選ぶためには,どの自動メソッドを使ってもよい:
適応的帯域幅,過剰平滑化帯域幅,一定の帯域幅をそれぞれの次元に用いる:
非零の対角から外れた要素を使うために,完全に指定された帯域幅行列を使う:
いくつかの名前付き帯域幅メソッドは経験的アプローチに従っている:
帯域幅は ![]() に対する最小二乗交差確認関数を最小化することで求まる:
に対する最小二乗交差確認関数を最小化することで求まる:
カーネル関数 (10)
これはNormalDistribution[0,1]の確率密度関数を使うことに等しい:
多変量データにいくつかのカーネル関数の中から任意のものを指定する:
多変量データについて積タイプとラジアルタイプのカーネル関数のどちらかを選ぶ:
オプション (7)
MaxMixtureKernels (7)
アプリケーション (6)
高解像度が望ましい場合は適応的帯域幅と多くの混合カーネルを使う:
NASDAQのApple株の日ごとの点変化の分布を推定する:
裾部が重いデータの場合は,より滑らかな推定を得るためにMaxMixtureKernelsオプションを大きくする:
偽造紙幣を見分けるのに最も役に立つ測定法を6つの中から選ぶ:
測定法6が2種類の紙幣を見分けるのに最も適しているようである:
140.5mmで切り捨て,測定法6を分類器として使って,見分け損ないの確率を求める:
KernelMixtureDistributionを使って楕円分布を作ることができる.楕円分布は多変量正規分布を一般化したものである:
周辺分布にNormalDistribution[0,1]を使うとMultinormalDistribution[μ,Σ]が与えられる:
特性と関係 (9)
KernelMixtureDistributionはもとになっている分布の一定推定器である:
実際に使われているカーネル数がサンプルサイズより大きいことはない:
帯域幅が無限大に近付くにつれ,推定量がカーネルの形に近付く:
KernelMixtureDistributionの線形補間はSmoothKernelDistributionである:
KernelMixtureDistributionは結果としてカーネルのMixtureDistributionになる:
KernelMixtureDistributionは,入力がTimeSeriesあるいはEventSeriesのときにのみ,値に使うことができる:
KernelMixtureDistributionは,入力がTemporalDataのときは,すべての値に同時に働く:
考えられる問題 (5)
初期帯域幅を大きくする,MaxMixtureKernels,感度を下げる,等を試す:
記号データの場合,カーネルは各データ点に置かれなければならない:
MaxMixtureKernelsをAllかAutomaticに設定する:
記号データは"SheatherJones"と"LeastSquaresCrossValidation"のメソッドでは使えない:
カーネル関数の中には境界がありプロットで除外部分が出ることがある:
ExclusionsオプションをNoneに設定することで大きいギャップができずプロットにかかる時間も短縮することができる:
おもしろい例題 (2)
テキスト
Wolfram Research (2010), KernelMixtureDistribution, Wolfram言語関数, https://reference.wolfram.com/language/ref/KernelMixtureDistribution.html (2016年に更新).
CMS
Wolfram Language. 2010. "KernelMixtureDistribution." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2016. https://reference.wolfram.com/language/ref/KernelMixtureDistribution.html.
APA
Wolfram Language. (2010). KernelMixtureDistribution. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/KernelMixtureDistribution.html