SemanticImport
SemanticImport[file]
试图语义导入一个文件以给出一个 Dataset 对象.
SemanticImport[file,type]
试图将文件中的所有元素解释成都属于指定类型.
SemanticImport[file,{type1,type2,…}]
试图将连续列的元素解释成都属于指定类型.
SemanticImport[file,col1->type1,col2->type2,…]
只保留由他们的位置或名字所指明的列 coli.
SemanticImport[file,typespec,form]
以指定形式表述结果.
更多信息和选项



- 在 SemanticImport[file] 中,file 可被指定为 File["path"] 或 "path".
- SemanticImport 主要是为一维和二维元素的数组.
- SemanticImport 可使用自由形式的语言学来解释给出的结构中的元素.
- 返回的对象类型包括数,Quantity 对象,Entity 对象,DateObject,GeoPosition 等等.
- SemanticImport 通过检查输入中特定的行或列中的所有元素作出详细的假定,例如关于日期格式.
- type 可能的值包括:
-
Automatic 自动选取类型 "String" Unicode 字符串 "Number" 任何标准格式的数 "Integer" 十进制记数的整数 "Real" 十进制记数的实数 "Quantity" 有单位的量 "Currency" 货币数量 "Date" 任何标准格式的日期 "DateTime" 日期和时间 "Time" 一天当中的时间 "GeoCoordinates" 以纬度、经度给出的地理位置 "URL" 正确格式的 URL "EmailAddress" 正确格式的电子邮件地址 "Country" 用自然语言给出的国家 "City" 用自然语言给出的城市 None 跳过一列 ispec Interpreter 使用的任何形式 - 给出以下选项来表明输入特征:
-
CharacterEncoding Automatic 假定的输入文件编码 Delimiters Automatic 元素之间的定界符 HeaderLines Automatic 被视为标头的行号 ExcludedLines {} 需从结果中排出的行 MissingDataRules {} 取代被认为是"missing"的数据的规则 - form 的可能的值包括:
-
"Dataset" 一个行定向的数据集 "List" 一个作为列表的单列 "Columns" 一个列的列表,每列都以列表形式给出 "NamedColumns" 将列名与内容列表相关联的一个关联 "Rows" 一个行的列表,每行都以列表形式给出 "NamedRows" 一个行的列表,每行都以列名到内容列表的关联的形式给出 - 当元素无法被解释时,返回的取而代之的形式包括:
-
Missing["Empty"] 一个空的或空白字符的元素 Missing["Invalid","string"] 有无效或无意义的数据字段 Missing["Unrecognized","string"] 不能被语法分析的元素 Missing["ByDesignation",value] 与 MissingDataRules 匹配的元素 Missing[custom] 由 MissingDataRules 提供的 Missing[…]
范例
打开所有单元关闭所有单元基本范例 (7)
只导入某些列,为需要被删除的列指定 None:
范围 (3)
以 Missing["UnknownData"] 的特殊形式返回缺失值("Unknown" 形式):
选项 (7)
SemanticImport 使用很多与 SemanticImportString 相同的选项. 参照SemanticImportString 得到更多例子.
CharacterEncoding (1)
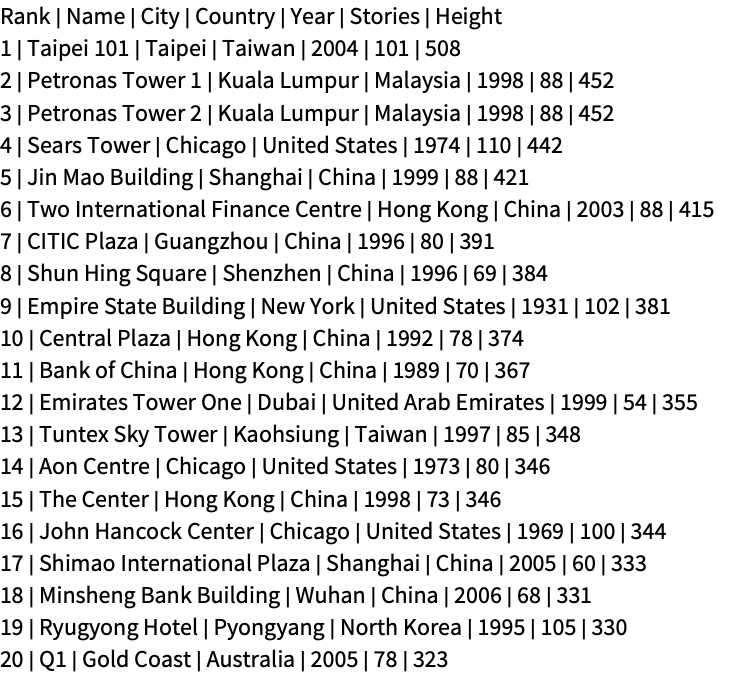
文本
Wolfram Research (2014),SemanticImport,Wolfram 语言函数,https://reference.wolfram.com/language/ref/SemanticImport.html (更新于 2016 年).
CMS
Wolfram 语言. 2014. "SemanticImport." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2016. https://reference.wolfram.com/language/ref/SemanticImport.html.
APA
Wolfram 语言. (2014). SemanticImport. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/SemanticImport.html 年