CSV (.csv)
背景

-
- MIME 类型:text/comma-separated-values,text/csv
- CSV 表格数据格式.
- 按行来存储数值和文本信息,使用逗号分隔字段.
- 通常作为交换格式用于电子表格应用程序.
- CSV 是 Comma-Separated Values(逗号分隔的值)的缩写.
- 纯文本格式.
- 与 TSV 类似.
- 支持 RFC 4180.
导入与导出

- Import["file.csv"] 返回包含字符串和数字的列表的列表,表示存储在文件中的行与列.
- Import["file.csv",elem] 导入指定的参数.
- Import["file.csv",{elem,subelem1,…}] 导入子参数 subelemi,对于导入部分数据非常有用.
- 导入格式可以用 Import["file","CSV"] 或 Import["file",{"CSV",elem,…}] 指定.
- Export["file.csv",expr] 从 expr 创建一个 CSV 文件.
- 支持的表达式 expr 包括:
-
{v1,v2,…} 单列数据 {{v11,v12,…},{v21,v22,…},…} 数据行列表 array 诸如 SparseArray、QuantityArray 等的数组 tseries TimeSeries、EventSeries 或 TemporalData 对象 Dataset[…] 数据集 Tabular[…] 表格对象 - 有关完整的通用信息,请参阅以下参考页面:
-
Import, Export 从文件导入或导出到文件 CloudImport, CloudExport 从云对象导入或导出到云对象 ImportString, ExportString 从字符串导入或导出到字符串 ImportByteArray, ExportByteArray 从字节数组导入或导出到字节数组
导入参数

- Import 通用参数:
-
"Elements" 该文件可用的参数和选项列表 "Summary" 文件摘要 "Rules" 所有可用参数的规则列表 - 表示数据的参数:
-
"Data" 二维数组 "Grid" 将数据作为 Grid 对象表格 "RawData" 字符串的二维数组 "Dataset" 将数据作为 Dataset "Tabular" 表格数据作为 TableView 对象 - 数据描述符元素:
-
"ColumnLabels" 列名 "ColumnTypes" 列名和类型的关联 "Schema" TabularSchema 对象 - 默认情况下,Import 与 Export 使用"Data"参数.
- 导入部分数据的子参数,任何数据表示参数 elem 可以使用 {elem, rows, cols} 格式指定行列,其中 rows 和 cols 可为以下任意:
-
n 第 n 行或列 -n 从结尾计算 n;;m 从 n 到 m n;;m;;s 从 n 到 m,步长为 s {n1,n2,…} 指定行或列 ni - 元数据参数:
-
"ColumnCount" 列数 "Dimensions" 行数列表和最大列数 "RowCount" 行数
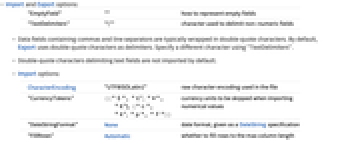
导入的选项

- Import 的选项:
-
ByteOrdering Automatic 字节的排序 CharacterEncoding "UTF8ISOLatin1" 文件中使用的原始字符编码 MissingValuePattern Automatic 用于指定缺失元素的模式 "ColumnTypeDetectionDepth" Automatic 用于标题检测的行数 "CurrencyTokens" None 当导入数值时会跳过货币单位 "DateStringFormat" None 日期格式,按 DateString 规范给出 "EmptyField" "" 怎样表示空字段 "FieldSeparator" "," 用于分隔列的字符串标记 "FillRows" Automatic 是否填满行最大化列长 "HeaderLines" Automatic 假定为标题的行数 "IgnoreEmptyLines" True 是否忽略空白行 "NumberPoint" "." 小数点字符串 "Numeric" Automatic 是否尽可能将数据字段导入为数字 "QuotingCharacter" "\"" 用于分隔非数字字段的字符 "Schema" Automatic 用于构建表格对象的架构 "SkipInvalidLines" False 是否跳过无效行 "SkipLines" Automatic 在文件开头跳过的行数 - 默认情况下,Import 试图将数据解释为 "UTF8" 编码文本. 如果文件中任何储存序列不能用 "UTF8" 表示,Import 将使用 "ISOLatin1" 代替.
- 用 CharacterEncoding -> Automatic, Import 尝试推断文件中的字符编码.
- "HeaderLines" 和 "SkipLines" 的可能设置为:
-
Automatic 尝试确定需要跳过或用作标题的行数 n 跳过的 n 行或作为 Dataset 开头使用 {rows,cols} 跳过的行和列或作为开头使用 - "Schema" 选项的可能设置包括:
-
schema 完整的 TabularSchema 规范 propval 架构属性和值(参阅 TabularSchema 的参考页面) <"prop1"val1,…> 架构属性和值的关联 - Import 将表格输入转换为由 "DateStringFormat" 指定格式的 DateObject.
- 默认情况下,并不导入双引号字符分隔的文本字段.
- Import 还支持 "Backend" 选项. 可能的设置为 "Arrow" 和 "Table". 虽然 "Arrow" 后端通常速度更快,但 "Table" 后端支持参差不齐的数组以及包含不同类型元素的列,并且兼容旧版本的 Wolfram 语言.
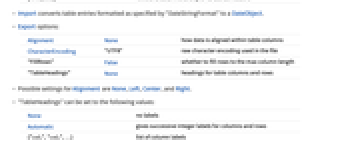
| Alignment | None | 数据与表格列的对齐方式 | |
| CharacterEncoding | "UTF8" | 文件中使用的原始字符编码 | |
| "EmptyField" | "" | 怎样表示空字段 | |
| "ExpressionFormattingFunction" | Automatic | 存储在 Tabular 对象中的表达式如何被转换为字符串 | |
| "FillRows" | False | 是否填满行最大化列长 | |
| "IncludeQuotingCharacter" | Automatic | 是否在导出值周围添加引号 | |
| "QuotingCharacter" | "\"" | 用于分隔非数字字段的字符 | |
| "TableHeadings" | Automatic | 表格列和行的标头 |
| None | 不要在任何值周围添加引号 | |
| Automatic | 仅在需要时在值周围添加引号 | |
| All | 在所有有效值周围添加引号 |
| None | 跳过列标签 | |
| Automatic | 导出列标签 | |
| {"col1","col2",…} | 列标签列表 | |
| {rhead,chead} | 指定行和列的单独标签 |
| Automatic | 默认转换为字符串 | |
| form | Format 支持的任意形式,如 InputForm | |
| f | 将表达式转换为字符串的任意函数 |
范例
打开所有单元 关闭所有单元范围 (8)
导入 (4)
将 CSV 文件作为 Tabular 对象导入,并自动检测标题行:
导出 (4)
导出一个 Tabular 对象:
使用 "TableHeadings" 选项从 Tabular 对象中去除开头:
导出一个 TimeSeries:
导出一个 EventSeries:
导出一个 QuantityArray:
导入参数 (27)
"Data" (6)
"Dataset" (2)
"Grid" (1)
将 CSV 数据作为 Grid 导入:
"RawData" (3)
"Schema" (1)
获取 TabularSchema 对象:
"Tabular" (7)
将 CSV 文件导入为 Tabular 对象:
导入选项 (15)
CharacterEncoding (1)
字符串编码可通过 $CharacterEncodings 设定为人任意值:
"DateStringFormat" (1)
使用指定数据格式将数据转换为 DateObject:
MissingValuePattern (1)
"Numeric" (1)
用 "Numeric"->True 解释数字:
"Schema" (1)
Import 根据存储在 CSV 文件中的数据自动推断列标签和类型:
"SkipLines" (1)
导出选项 (8)
CharacterEncoding (1)
字符串编码可通过 $CharacterEncodings 设定为任意值:
"ExpressionFormattingFunction" (1)
"IncludeQuotingCharacter" (1)
"QuotingCharacter" (1)
"TableHeadings" (1)
可能存在的问题 (14)
对于不规则数组(行具有不同数量的列的数组),某些行可能被视为无效:
使用 "Backend""Table" 来避免跳过这些行:
格式为 "nnnEnnn" 的条目被解释为科学计数法的数字:
从版本 14.3 开始,可通过使用 -Head- 格式将一些表达转换为字符串:
用 "ExpressionFormattingFunction"->InputForm 获取以前的结果:
从版本 14.2 开始,当整数值列中包含大于 Developer`$MaxMachineInteger 的数值时,系统会添加引用字符:
使用 "IncludeQuotingCharacter"->None 来获取之前的结果:
使用 MissingValuePatternNone 来覆盖此解释:
从版本 14.2 开始,小数部分为 0 的实数将导出为整数:
使用 "Backend"->"Table" 来获取之前的结果:
如果列中包含非统一数据类型,建议使用 "Backend""Table" 设置:
从版本 14.2 开始,大于 Developer`$MaxMachineInteger 的整数将被作为实数导入:
使用 "Backend"->"Table" 来获取之前的结果:
从版本 14.2 开始,Tabular 对象中的日期和时间列将使用 DateString 格式导出:
使用 "Backend"->"Table" 来获取之前的结果:
旧版 Wolfram 语言生成的某些 CSV 数据可能有文本字段分隔错误,而无法在版本 11.2 或更高版本中按预期导入:
使用 "QuotingCharacter""" 将给出之前预期的结果:
导入带有行和列标题的 Dataset 时,左上角的数据可能会丢失:
Dataset 的显示效果可能因数据维度不同而有所差异: