PDF (.pdf)
背景
-
- MIME 类型:application/pdf
- Adobe Acrobat 格式.
- 交换和归档多页文档的标准格式.
- PDF 是 Portable Document Format(便携式文档格式)的缩写.
- 二进制文件格式.
- 以设备和分辨率独立的方式存储文本、字体、图像和二维矢量图形.
- 还可以存储内嵌光栅图像.
- 支持多种有损和无损压缩方法.
Import 与 Export

- Import["file.pdf"] 导入 PDF 文件,返回每页的光栅图像列表.
- Import["file.pdf",elem] 从一个 PDF 文件中导入指定的参数.
- Import["file.pdf",{elem,suba,subb,…}] 导入一个子参数.
- 导入格式可以用 Import["file","PDF"] 或 Import["file",{"PDF",elem,…}] 指定.
- Export["file.pdf",expr] 从一个任意表达式、单元或笔记本对象中创建一个 PDF 文件.
- 当导出至 PDF 文件时,Wolfram 语言不光栅化字体或二维矢量图形.
- Export["file.pdf",expr,elem] 通过把 expr 作为指定参数 elem 创建 PDF 文件.
- Export["file.pdf",{expr1,expr2,…},{{elem1,elem2,…}}] 把每一个 expri 指定为相应的 elemi.
- Export["file.pdf",expr,opt1->val1,…] 导出具有指定值的指定选项参数的 expr.
- Export["file.pdf",{elem1->expr1,elem2->expr2,…},"Rules"] 使用规则指定要导出的参数.
- Export["file.pdf",expr] 有效呈现 expr,如同由默认打印机打印一样. 如果 expr 不是笔记本,则它将有效地创建一个与执行计算的笔记本具有相同属性的笔记本,或者如果没有在笔记本中开始计算,则创建一个默认笔记本. PrintingStyleEnvironment 前端选项用于选择打印环境.
- Wolfram 语言尽可能会尝试保留内容的向量描述,但如果需要 PDF 不支持的现代渲染方式的内容将被栅格化. 这包括所有具有透明度、渐变颜色、纹理或阴影的所有三维图形和二维内容.
- 请到以下参考页面了解完整的基本信息:
-
Import, Export 从文件导入或导出到文件 CloudImport, CloudExport 从云对象导入或导出到云对象 ImportString, ExportString 从字符串导入或导出到字符串 ImportByteArray, ExportByteArray 从字节数组导入或导出到字节数组
Import 参数



- Import 的通用参数:
-
"Elements" 该文件可用的参数和选项列表 "Summary" 文件摘要 "Rules" 所有可用参数的规则列表 - 结构参数:
-
"ContentsGraph" 文档中的目录图 "ContentsStartPage" 给出目录名称和页码的规则列表 "PageCount" 页数 "Summary" 文件摘要 - 整个 PDF 文档的数据表示参数:
-
"Plaintext" 给出整个文档文本内容的字符串 "FormattedText" 整个文档的一系列格式化文本 - 以表示文档每一页的列表形式给出的数据表示参数:
-
"PageFormattedText" 格式化的文本列表,每个文本代表一个页面 "PageGraphics" Graphics 对象的列表,每个对象代表一个页面 "PageImages" Image 对象列表,每个对象代表一个页面 "PagePlaintext" 字符串列表,每个字符串代表页面的纯文本 "PagePositionedText" 包括文本坐标的 Text 对象列表 - Import 默认使用 "PageImages" 参数.
- 元数据参数:
-
"Author" 该文档的作者 "CreationDate" 文档的创建日期,以 DateObject 形式给出 "Creator" 创建内容的程序 "Keywords" 文档中的关键字 "ModificationDate" 文档的修改日期,以 DateObject 形式给出 "MetaInformation" 以字符串和日期对象形式给出的元数据 "Producer" 将数据转换为 PDF 的程序 "Subject" 文件的主题 "Title" 文件名 "Version" 文件的 PDF 规范版本 - 超链接、注释和表单字段元素:
-
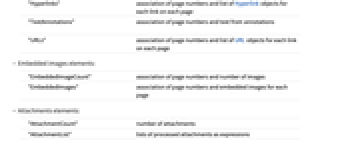
"FormFieldRules" 给出表单字段名称和值的页码和规则列表的关联 "HighlightedText" 每页上每个突出显示的文本部分的页码和字符串列表的关联 "Hyperlinks" 每个页面上每个链接的页码和 Hyperlink 对象列表的关联 "TextAnnotations" 批注中页码和文本的关联 "URLs" 每个页面上每个链接的页码和 URL 对象列表的关联 - 嵌入式图像元素:
-
"EmbeddedImageCount" 页码和图像数量的关联 "EmbeddedImages" 每页的页码和嵌入图像的关联 - 附件参数:
-
"AttachmentCount" 附件数 "AttachmentList" 附件列表,如果可能,作为 Wolfram 语言表达式导入 "AttachmentNames" 附件名称列表 "AttachmentDetails" 提供内容和附件元数据的关联列表 "RawAttachmentList" 以字节数组列表形式给出的附件 "AttachmentData" 将原始附件数据作为字节数组和元数据给出的关联列表 - 参数 "AttachmentDetails" 是为每个附件提供关联的列表. 每个关联通常具有以下键:
-
"Name" 分配给附件的名称 "Content" 导入内容 "CreationDate" 附件记录的创建日期 "ModificationDate" 附件记录的修改日期 "ByteCount" 附件中的字节数 - 参数 "AttachmentDetails" 是为每个附件提供关联的列表. 每个关联通常具有以下键:
-
"Name" 分配给附件的名称 "RawContent" 原始内容作为字节数组 "CreationDate" 附件记录的创建日期 "ModificationDate" 附件记录的修改日期 "ByteCount" 附件中的字节数 - 对于具有多个部分的元素,请使用{elem,page,index} 或 {elem,index} 形式的子元素导入部分数据,其中 page 和 index 可以是以下任意一种:
-
n 第 n 个项目 -n 从末尾开始计数 n;;m 从 n 到 m n;;m;;s 以步长 s 从 n 到 m {n1,n2,…} 特定项 ni - 用 {"FormFieldRules",page,names} 导入与字段 names 相对应的表单值.
选项

- Import 选项:
-
"Password" None 以字符串形式提供的文档密码 "TextOutlines" True 是否将字符导入作为概要 "Render" All 要在 ImageList 中呈现的文档部分 RasterSize Automatic 以像素为单位的栅格大小 ImageResolution $ImageResolution dpi 的图像分辨率以进行光栅化 "AttachmentRules" <> 控制如何导入附件的规则 - "Render" 的可用设定:
-
"Annotations" 例如突出显示或其他文本框等的注释 "FormFields" 填写的表单字段中的数据 All 呈现文档中的所有元素 None 不呈现文档中的其他元素 - Export 选项:
-
ImageSize Automatic 总体图像大小 ImageResolution 72 以 dpi 光栅化的图像分辨率 "AllowRasterization" Automatic 是否光栅化一个需要 PDF 高级版本的图形 - "AllowRasterization" 的可能设置为:
-
Automatic 光栅化一个需要 PDF 高级版本渲染的图形,其含有诸如透明度或梯度特征 True 始终光栅化图形 False 始终使用矢量图形,为了忠实渲染,必要时部署高级的 PDF 特征