函数中的数值运算
函数中的数值运算
| 算术 | 求数值根 |
| Wolfram 语言中的数值数学 | 微分方程数值解的介绍 |
| 数值数学的不定性 | 微分方程的数值解 |
| 数值和、连乘与积分 | 数值最优化 |
| 数值积分 | 控制结果的精度 |
| 和与连乘的数值计算 | 监控和选择算法 |
| 方程的数值解 | 对输入敏感的函数 |
| 多项式方程的数值解 |
2.3 + 5.632.4 / 8.9 ^ 22 3 42 * 3 * 4(3 + 4) ^ 2 - 2 (3 + 1)2.4 ^ 452.3 10 ^ 702.3*^701 / 3 + 2 / 71 / 3 + 2 / 7 //NN[1 / 3 + 2 / 7, 40]Integrate[Sin[Sin[x]], {x, 0, 1}]N[%]当 Wolfram 语言不能求出显式结果时,返回一个符号形式. 可以取这个符号形式,使用 N 求数值近似值.
给出 N 的第二个自变量,可以指定使用的数值精度:
N[Integrate[Sin[Sin[x]], {x, 0, 1}], 40]如果想要在 Wolfram 语言中数值地计算积分,使用函数 Integrate 并且对结果应用 N 不是最有效的方法. 更好的方法是使用函数 NIntegrate,可以立即给出数值答案,不必先得到精确的符号结果. 应该认识到即使 Integrate 最后不再设法给出精确结果,可能已经花费了许多时间.
NIntegrate 直接计算数值积分,而不用得到符号形式:
NIntegrate[Sin[Sin[x]], {x, 0, 1}]| Integrate | NIntegrate | 定积分 |
| Sum | NSum | 求和 |
| Product | NProduct | 连乘 |
| Solve | NSolve | 代数方程的解 |
| DSolve | NDSolve | 微分方程的解 |
| Maximize | NMaximize | 最大化 |
然而,当 Wolfram 系统求数值积分时,在一些初始符号预处理时候,其具有的被积函数的信息仅仅是被积函数的一系列数值值. 要得到积分的确切结果,Wolfram 系统必须对被积函数的光滑性和其他性质做出某种假定. 如果被积函数是严重病态的,这些假定可能失效,因此,Wolfram 系统可能对积分给出错误结果.
例如,当对在特定位置具有非常细的尖峰的函数进行数值积分时,这个问题可能出现. Wolfram 系统在许多点处对函数采样,然后假定函数在这些点间光滑变化. 因此,如果没有接近尖峰的采样点,那么尖峰将检测不到,对该数值积分的贡献就不能正确地包括进去.
Plot[Exp[-x ^ 2], {x, -10, 10}, PlotRange -> All]NIntegrate[Exp[-x ^ 2], {x, -10, 10}]NIntegrate[Exp[-x ^ 2], {x, -10000, 10000}]NIntegrate 力图尽可能好地利用能得到的关于数值积分的信息. 例如,当 NIntegrate 注意到在某一区域中估计误差较大时,会在该区域取更多的采样点. 用这种方法,NIntegrate 尽量使运算适应特定的被积函数.
NIntegrate 使用的这种适应程序与函数 Plot 力图画出函数的光滑曲线所做的事情相类似. 在两种情况下,Wolfram 系统都是在特定区域中尽量取更多的采样点,直到在该区域找出函数的光滑近似为止.
在求函数极小值的数值近似时,出现类似的问题. Wolfram 系统只采有限个样本值,然后在这些值之间对函数进行光滑插值. 如果函数在某区域有一个急剧的下降, Wolfram 系统可能错过这个下降,而给出错误的最小值.
| NSum[f,{i,imin,Infinity}] | |
| NProduct[f,{i,imin,Infinity}] | |
| NIntegrate[f,{x,xmin,xmax}] | |
| NIntegrate[f,{x,xmin,xmax},{y,ymin,ymax}] | |
重积分 | |
NSum[1 / i ^ 3, {i, 1, Infinity}]NIntegrate 能处理积分区间端点处的奇异性:
NIntegrate[1 / Sqrt[x (1 - x)], {x, 0, 1}]NIntegrate[Exp[-x ^ 2], {x, -Infinity, Infinity}]NIntegrate[Sin[x y], {x, 0, 1}, {y, 0, x}]NIntegrate[ Sin[x y], {x, 0, 1}, {y, 0, Sqrt[x ^ 3 + 3]}]| N[Integrate[expr,{x,xmin,xmax}]] | 尝试进行精确积分,然后求数值近似 |
| NIntegrate[expr,{x,xmin,xmax}] | 求积分的数值近似 |
| NIntegrate[expr,{x,xmin,xmax},{y,ymin,ymax},…] | |
多重数值积分 | |
| NIntegrate[expr,{x,xmin,x1,x2,…,xmax}] | |
沿直线段求数值积分,从点 | |
NIntegrate[Exp[-x ^ 3], {x, 0, Infinity}]NIntegrate[x ^ 2 + y ^ 2, {x, -1, 1}, {y, -1, 1}]NIntegrate[1 / Sqrt[x], {x, 0, 1}]Integrate[1 / Sqrt[x], {x, 0, 1}]NIntegrate[1 / x, {x, 0, 1}]
NIntegrate 自动查找积分域端点和分段函数(如 Piecewise 和 Abs)定义的子区域的奇点. 当其他奇点存在时,NIntegrate 有可能给不出正确的积分结果. 然而,按照其自适应程序,NIntegrate 将常常检查奇点的存在,并给出有关的警告.
NIntegrate 给出关于积分域中间的奇点的一个警告. 最终结果很接近正确答案:
NIntegrate[x ^ 2 Sin[1 / x], {x, -1, 2}]如果已知被积函数在某处有奇点,可以明确告诉 NIntegrate 来处理. NIntegrate[expr,{x,xmin,x1,x2,…,xmax}] 对 expr 从 xmin 到 xmax 积分,在中间点 xi 中查找奇点.
NIntegrate[x ^ 2 Sin[1 / x], {x, -1, 0, 2}]NIntegrate[1 / x, {x, -1, -I, 1, I, -1}]N[2 Pi I]
选项名
|
默认值
| |
| MinRecursion | 0 | 积分区域的递归细分的最小数 |
| MaxRecursion | Automatic | 积分区域的递归细分的最大数 |
| MaxPoints | Automatic | 被积函数采样的最大次数 |
NIntegrate 的特殊选项.
当 NIntegrate 力图计算数值积分时,在一系列点上对被积函数采样. 当发现在一个特定区域内被积函数变化很快时,则在该区域递归地取更多的采样点. 参数 MinRecursion 和 MaxRecursion 指定递归细分层的最小和最大数. 增加 MinRecursion 的值保证 NIntegrate 使用较大的采样点数. MaxPoints 和 MaxRecursion 限制了NIntegrate 使用的采样点数. 增加 MinRecursion 或者 MaxRecursion 会使 NIntegrate 计算更慢.
NIntegrate[Exp[-(x - 1) ^ 2], {x, -1000, 1000}]在选项设置 MinRecursion->3 下,NIntegrate 取足够多的采样点,使其注意到  附近的高峰. 然而在 MaxRecursion 的缺省设置下,NIntegrate 不能使用足够多的采样来得到精确结果:
附近的高峰. 然而在 MaxRecursion 的缺省设置下,NIntegrate 不能使用足够多的采样来得到精确结果:
NIntegrate[Exp[-(x - 1) ^ 2], {x, -50000, 1000}, MinRecursion -> 3]NIntegrate[Exp[-(x - 1) ^ 2], {x, -50000, 1000}, MinRecursion -> 3, MaxRecursion -> 20]解决此问题的另一方法是使用 NIntegrate 将积分区间分成若干段,其中一个小区间包含高峰:
NIntegrate[Exp[-(x - 1) ^ 2], {x, -1000, -10, 10, 1000}]NIntegrate[1 / Sqrt[x + Log[y + z] ^ 2], {x, 0, 1}, {y, 0, 1}, {z, 0, 1}, MaxPoints -> 1000]NSum[1 / (i ^ 3 + i!), {i, 1, Infinity}]Sum[1 / (i ^ 3 + i!), {i, 1, Infinity}]可以明确使用 N 得到数值结果:
N[%]NSum 的工作方式是明确地包含确定的项数,然后尽量估计剩余项的值. 这三种攻击的方法,第一种使用欧拉-麦克劳林方法,通过积分计算余项. 第二个方法称为 Wynn epsilon 方法,在和中取更多项的采样,然后将其拟合成多项式乘以衰减的指数函数. 第三个方法,对于交错级数是很有用的,其采用交错符号的方法;对大量的剩余项进行采样,并且使用两个多项式的比率,求和的近似值(Padé 近似).
选项名
|
默认值
| |
| Method | Automatic | |
| NSumTerms | 15 | 明确包含的项数 |
| VerifyConvergence | True | 级数的收敛性是否应该被验证 |
NSum 的选项.
如果用户不明确指明使用的方法,NSum 将在 EulerMaclaurin 或者 WynnEpsilon 方法中进行选择. 在任何情况下,关于求和函数的一些假定必须给出. 如果假定不正确,可能得到不精确的结果.
NSum[Exp[-n], {n, 0, 100}]Sum[Exp[-n], {n, 0, 100}]//N| NSolve[lhs==rhs,x] | 求多项式方程的数值解 |
| NSolve[{lhs1==rhs1,lhs2==rhs2,…},{x,y,…}] | |
求多项式方程组的数值解 | |
| FindRoot[lhs==rhs,{x,x0}] | 以 |
| FindRoot[{lhs1==rhs1,lhs2==rhs2,…},{{x,x0},{y,y0},…}] | |
求方程组的一个解 | |
NSolve 给出多项式方程的全部根的数值近似值:
NSolve[x ^ 5 + x + 1 == 0, x]也可以使用 NSolve 求方程组的数值解:
NSolve[{x + y == 2, x - 3 y + z == 3, x - y + z == 0}, {x, y, z}]如果方程中只包含线性函数或多项式,那么可以使用 NSolve 求出全部解的数值近似值. 但是,当方程中包含更复杂的函数时,一般求不出全部解. 甚至数值解也做不到. 在这种情况下,可以使用 FindRoot 求方程的一个数值解,此时,必须给出 FindRoot 进行搜索的初始值.
FindRoot[3 Cos[x] == Log[x], {x, 1}]FindRoot[3 Cos[x] == Log[x], {x, 10}]FindRoot[{x == Log[y], y == Log[x]}, {{x, I}, {y, 2}}]Solve[x ^ 5 + 7x + 1 == 0, x]使用 N 可得到数值解:
N[%]N[%%, 25]使用 NSolve 直接求多项式方程的数值解. 不必先求精确解:
NSolve[x ^ 7 + x + 1 == 0, x]| NSolve[poly==0,x] | 求多项式方程的数值近似解 |
| NSolve[poly==0,x,n] | 求 |
| NSolve[{eqn1,eqn2,…},{var1,var2,…}] | |
求多项式方程组的解 | |
NSolve 可以对任意多项式方程或多项式方程组给出数值解的完全集合.
NSolve 可以求联立多项式方程组的解:
NSolve[{x ^ 2 + y ^ 2 == 1, x ^ 3 + y ^ 3 == 2}, {x, y}]NSolve 给出求多项式方程的数值近似值的一般方法. 然而,如 "一元方程" 中讨论的那样,对更一般的方程,求数值解将会困难的多. 函数 FindRoot 给出求任意方程或方程组的一个数值解的方法.
| FindRoot[f,{x,x0}] | 以 x=x0 为起点,求 f 的一个数值解 |
| FindRoot[lhs==rhs,{x,x0}] | 以 x=x0 为起点,求方程 lhs==rhs 的一个解 |
| FindRoot[f1,f2,…,{{x,x0},{y,y0},…}] | |
求所有 fi 的一个联立数值解 | |
| FindRoot[{eqn1,eqn2,…},{{x,x0},{y,y0},…}] | |
求联立方程 eqni 的一个数值解 | |
Plot[{Cos[x], x}, {x, -1, 1}]FindRoot[Cos[x] == x, {x, 0}]在求方程的一个解中,FindRoot 从一个指定点开始依次尝试使得越来越接近一个解. 即使方程有多个解,FindRoot 总是返回其发现的第一个解,所求的是哪个解依赖于选择的起点. 只要起点充分靠近某个解,FindRoot 总是返回这个解.
FindRoot[Sin[x], {x, 3}]FindRoot[Sin[x], {x, 6}]如果要使用 FindRoot 求复数解,必须给出复数起始值:
FindRoot[Sin[x] == 2, {x, I}]FindRoot[Zeta[1 / 2 + I t], {t, 12}]FindRoot[{Sin[x] == Cos[y], x + y == 1}, {{x, 1}, {y, 1}}]FindRoot 所使用的变量可以具有形式为列表的值. 这使得用户可以求解以向量为自变量的函数的根.
FindRoot[{{1, 2}, {3, 4}}.x == {5, 6}, {x, {1, 1}}]FindRoot[{{{1, 2}, {3, 4}}.x == a x, x.x == 1}, {{x, {1, 1}}, {a, 1}}]| NDSolve[eqns,y,{x,xmin,xmax}] | 求微分方程中函数 y 的数值解,其中自变量 x 的变化范围从 xmin 到 xmax |
| NDSolve[eqns,{y1,y2,…},{x,xmin,xmax}] | |
求关于 yi 的微分方程组的数值解 | |
NDSolve[{y'[x] == y[x], y[0] == 1}, y, {x, 0, 2}]y[1.5] /. %Wolfram 语言把函数的数值近似值表示为 InterpolatingFunction 对象. 当给自变量 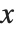 一个特定的值时,该对象返回
一个特定的值时,该对象返回 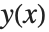 在该点处的近似值. InterpolatingFunction 存储着
在该点处的近似值. InterpolatingFunction 存储着 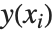 的一个值表,然后对该值进行插值,求出在特定
的一个值表,然后对该值进行插值,求出在特定 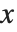 处
处 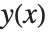 的近似值.
的近似值.
| y[x]/.solution | 对函数 y 使用规则列表来得到 y[x] 的值 |
| InterpolatingFunction[data][x] | 计算插值函数在点 x 处的值 |
| Plot[Evaluate[y[x]/.solution],{x,xmin,xmax}] | |
画微分方程的解曲线 | |
使用 NDSolve 给出的结果.
NDSolve[{y'[x] == z[x], z'[x] == -y[x], y[0] == 0, z[0] == 1}, {y, z}, {x, 0, Pi}]z[2] /. %Plot[Evaluate[z[x] /. %3], {x, 0, Pi}]| NDSolve[eqn,u,{x,xmin,xmax},{t,tmin,tmax},…] | |
求解偏微分方程 | |
"微分方程数值解的介绍" 中讨论的函数 NDSolve 可用以求微分方程的数值解. NDSolve 既可处理单个微分方程,又可处理联立微分方程组. 其可以处理范围很广的常微分方程以及某些偏微分方程. 在一个常微分方程系统中,可能有任意个未知函数 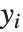 ,但这些函数都必须依赖于单个“独立变量”
,但这些函数都必须依赖于单个“独立变量” 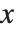 . 偏微分方程则包含两个或更多的独立变量. NDSolve 也可以处理混合了微分方程和代数方程的微分代数方程.
. 偏微分方程则包含两个或更多的独立变量. NDSolve 也可以处理混合了微分方程和代数方程的微分代数方程.
| NDSolve[{eqn1,eqn2,…},y,{x,xmin,xmax}] | |
求在 x 的区间 xmin 到 xmax 上,函数 y 的数值解 | |
| NDSolve[{eqn1,eqn2,…},{y1,y2,…},{x,xmin,xmax}] | |
求多个函数 yi 的数值解 | |
NDSolve 将函数 yi 的解表示为 InterpolatingFunction 对象. 这种 InterpolatingFunction 对象提供独立变量 x 从 xmin 到 xmax 上的 yi 的近似值.
要进行计算,必须对 NDSolve 给定 yi 和其导数的适当的初始或边界条件. 这种条件指定在某个点 x 处的函数值 yi[x] 或者导数值 yi'[x]. 一般可以在任何点 x 处给定条件,至少对常微分方程如此,NDSolve 将自动覆盖区域 xmin 到 xmax.
NDSolve[{y'[x] == y[x], y[0] == 1}, y, {x, 0, 2}]NDSolve[{y'[x] == y[x], y[3] == 1}, y, {x, 0, 2}]NDSolve[{y''[x] + x y[x] == 0, y[0] == 1, y[1] == -1}, y, {x, 0, 1}]使用 NDSolve 时,给定的初始或者边界条件必须能完全确定 yi 的解. 在使用 DSolve 求微分方程的符号解时,可以指定较少的初始条件. 这是因为 DSolve 自动地插入任意常数 C[i] 来表示相应于未明确指定的初始条件的自由度. 由于NDSolve 必须给出数值解,其不能表示这种附加的自由度. 因此,必须明确指出确定解所需的全部初始和边界条件.
NDSolve[{y'''[x] + 8 y''[x] + 17 y'[x] + 10 y[x] == 0, y[0] == 6, y'[0] == -20, y''[0] == 84}, y, {x, 0, 1}]Plot[Evaluate[y[x] /. %], {x, 0, 1}]NDSolve[{y'''[x] + Sin[x] == 0, y[0] == 4, y[1] == 7, y[2] == 0}, y, {x, 0, 2}]NDSolve[{y''[x] + y[x] == 12 x, 2 y[0] - y'[0] == -1, 2 y[1] + y'[1] == 9}, y, {x, 0, 1}]在大多数情况下,给出的初始条件必须包含相同的 x 值,例如 x0. 因此,可以不必明确给出 xmin 和 xmax 两个值. 当指定 x 的区域为 {x,x1} 时,Wolfram 语言将自动生成 x0 到 x1 的区域上的解.
NDSolve[{y'[x] == y[x], y[0] == 1}, y, {x, 2}]可以用方程形式给定初始条件. 这些方程可能有多个解. 在这种情况下,NDSolve 相应地生成多个解.
NDSolve[{y'[x] ^ 2 - y[x] ^ 2 == 0, y[0] ^ 2 == 4}, y[x], {x, 1}]Plot[Evaluate[y[x] /. %], {x, 0, 1}]可以使用 NDSolve 求解耦合微分方程系统的解.
sol = NDSolve[{x'[t] == -y[t] - x[t] ^ 2, y'[t] == 2 x[t] - y[t], x[0] == y[0] == 1}, {x, y}, {t, 10}]Plot[Evaluate[y[t] /. sol], {t, 0, 10}, PlotRange -> All]ParametricPlot[Evaluate[{x[t], y[t]} /. sol], {t, 0, 10}, PlotRange -> All]eqns = Join[Table[y[i]'[x] == y[i - 1][x] - y[i][x], {i, 2, 4}], {y[1]'[x] == -y[1][x], y[5]'[x] == y[4][x], y[1][0] == 1}, Table[y[i][0] == 0, {i, 2, 5}]]NDSolve[eqns, Table[y[i], {i, 5}], {x, 10}]Plot[Evaluate[Table[y[i][x], {i, 5}] /. %], {x, 0, 10}]NDSolve[{y''[x] == -RandomReal[{0, 1}, {4, 4}].y[x], y[0] == y'[0] == Table[1, {4}]}, y, {x, 0, 8}]With[{s = y[x] /. First[%]}, Plot[{s[[1]], s[[2]], s[[3]], s[[4]]}, {x, 0, 8}, PlotRange -> All]]
选项名
|
默认值
| |
| MaxSteps | Automatic | 对 |
| StartingStepSize | Automatic | |
| MaxStepSize | Automatic | |
| NormFunction | Automatic | 用于误差估计的范数 |
NDSolve 选择.
NDSolve 有许多方法来求解方程,但是基本上所有的方法都是通过取独立变量 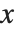 的一系列步进来工作,并且使用自适应程序来决定步长的大小. 一般,如果解在某个区域中变化得很快,那么 NDSolve 将减小步长以便更好地跟踪解.
的一系列步进来工作,并且使用自适应程序来决定步长的大小. 一般,如果解在某个区域中变化得很快,那么 NDSolve 将减小步长以便更好地跟踪解.
NDSolve[{y'[x] == If[x < 0, 1 / (x - 1), 1 / (x + 1)], y[-5] == 5}, y, {x, -5, 5}]Plot[Evaluate[y[x] /. %], {x, -5, 5}]sol = NDSolve[{y'[x] == -40 y[x], z'[x] == -z[x] / 10, y[0] == z[0] == 1}, {y, z}, {x, 0, 1}]NDSolve 成功地跟踪了这两个分量:
Plot[Evaluate[{y[x], z[x]} /. sol], {x, 0, 1}, PlotRange -> All]NDSolve 遵循这样的一般过程:减小步长的大小直到精确地跟踪解. 然而,当真解有奇点或积分间隔太大时时,会出现问题. 对于第一种情形,NDSolve 会限制最小步长,这对于给定积分间隔是有意义的. 对于第二种情形,选项 MaxSteps 指定 NDSolve 求解采取的最大步数. 对常微分方程,缺省设置是 MaxStepsAutomatic. 使用 Automatic 设置,NDSolve 会基于初始步长估计求解方程所需的步数.
当步长太小时,NDSolve 会停止:
NDSolve[{y'[x] == -1 / x ^ 2, y[-1] == -1}, y[x], {x, -1, 0}]Plot[Evaluate[y[x] /. %], {x, -1, 0}]MaxSteps 的缺省对于大多数具有光滑解的方程来说已足够了. 然而,当解有复杂的结构时,可能必须选择更大的MaxSteps 的值. 当设置为 MaxSteps->Infinity 时,使用的步数没有上限.
对罗伦兹方程要产生解的完整结构,需要给出 MaxSteps 的更大设置:
NDSolve[{x'[t] == -3 (x[t] - y[t]), y'[t] == -x[t] z[t] + 26.5 x[t] - y[t], z'[t] == x[t] y[t] - z[t], x[0] == z[0] == 0, y[0] == 1}, {x, y, z}, {t, 0, 200}, MaxSteps -> Infinity]ParametricPlot3D[Evaluate[{x[t], y[t], z[t]} /. %], {t, 0, 200}, PlotPoints -> 10000, ColorFunction -> (ColorData["Rainbow"][#4]&)]当 NDSolve 求解特定微分方程组时,总是尽量选择适合这些方程的步长. 在有些情况下,NDSolve 采取的第一步的步长可能太大,这样可能丢失解的重要特征. 要避免这个问题,可以明确地设置选项 StartingStepSize 来指定第一步的步长.
NDSolve[{x'[t] == y[t] ^ 2 + x[t] y[t], 2 x[t] ^ 2 + y[t] ^ 2 == 1, x[0] == 0, y[0] == 1}, {x, y}, {t, 0, 5}]Plot[Evaluate[{x[t], y[t]} /. %], {t, 0, 5}]| NDSolve[{eqn1,eqn2,…},u,{t,tmin,tmax},{x,xmin,xmax},…] | |
求偏微分方程的解 u | |
| NDSolve[{eqn1,eqn2,…},{u1,u2,…},{t,tmin,tmax},{x,xmin,xmax},…] | |
求偏微分方程组的解 ui | |
NDSolve[{D[u[t, x], t, t] == D[u[t, x], x, x], u[0, x] == Exp[-x ^ 2], Derivative[1, 0][u][0, x] == 0, u[t, -6] == u[t, 6]}, u, {t, 0, 6}, {x, -6, 6}]Plot3D[Evaluate[u[t, x] /. First[%]], {t, 0, 6}, {x, -6, 6}, PlotPoints -> 50]NDSolve[{D[u[t, x], t, t] == D[u[t, x], x, x] + (1 - u[t, x] ^ 2)(1 + 2u[t, x]), u[0, x] == Exp[-x ^ 2], Derivative[1, 0][u][0, x] == 0, u[t, -10] == u[t, 10]}, u, {t, 0, 10}, {x, -10, 10}]Plot3D[Evaluate[u[t, x] /. First[%]], {t, 0, 10}, {x, -10, 10}]DensityPlot[Evaluate[u[10 - t, x] /. First[%%]], {x, -10, 10}, {t, 0, 10}, PlotPoints -> 200, Mesh -> False]eqn = D[u[t, x, y], t, t] == D[u[t, x, y], x, x] + D[u[t, x, y], y, y] / 2 + (1 - u[t, x, y] ^ 2)(1 + 2u[t, x, y])NDSolve[{eqn, u[0, x, y] == Exp[-(x ^ 2 + y ^ 2)], u[t, -5, y] == u[t, 5, y], u[t, x, -5] == u[t, x, 5], Derivative[1, 0, 0][u][0, x, y] == 0}, u, {t, 0, 4}, {x, -5, 5}, {y, -5, 5}]Table[Plot3D[Evaluate[u[t, x, y] /. First[%]], {x, -5, 5}, {y, -5, 5}, PlotRange -> All, PlotPoints -> 100, Mesh -> False], {t, 1, 4}]| FindMinimum[f,{x,x0}] | 以 x=x0 为初始点,搜索函数 f 的局部极小值 |
| FindMinimum[f,x] | 搜索函数 f 的局部极小值 |
| FindMinimum[f,{{x,x0},{y,y0},…}] | |
搜索多变量函数的局部极小值 | |
| FindMinimum[{f,cons},{{x,x0},{y,y0},…}] | |
以 x=x0, y=y0, … 为初始点,搜索在约束条件 cons 下的局部极小值 | |
| FindMinimum[{f,cons},{x,y,…}] | 在约束条件 cons 下搜索局部极小值 |
| FindMaximum[f,x]
, etc.
| 搜索局部极大值 |
FindMinimum[Gamma[x], {x, 2}]Gamma[x] /. Last[%]与 FindRoot 一样,FindMinimum 和 FindMaximum 从一个点开始,循序渐近地寻找极小值或极大值. 但是由于他们一旦找到一个极值,就会返回结果,可能只给出函数的局部极小值或极大值,而不是全局的极小值或极大值.
Plot[x ^ 4 - 3x ^ 2 + x, {x, -3, 2}]FindMinimum[x ^ 4 - 3 x ^ 2 + x, {x, 1}]FindMinimum[x ^ 4 - 3 x ^ 2 + x, {x, -1}]FindMinimum[x ^ 4 - 3 x ^ 2 + x, x]FindMinimum[{x ^ 4 - 3 x ^ 2 + x, x < 0}, x]| NMinimize[f,x] | 尝试求 f 的全局极小值 |
| NMinimize[f,{x,y,…}] | 尝试求多变量函数的全局极小值 |
| NMaximize[f,x] | 尝试求 f 的全局极大值 |
| NMaximize[f,{x,y,…}] | 尝试求多变量函数的全局极大值 |
NMinimize[x ^ 4 - 3x ^ 2 + x, x]NMinimize 和 NMaximize 是 Minimize 和 Maximize 的数值模拟. 但是与 Minimize 和 Maximize 不同,他们经常不能保证可以找到绝对的全局极小值和极大值. 然而,当函数 f 很平滑,并且具有有限数目的局部极小值和极大值的时候,通常表现良好.
| NMinimize[{f,cons},{x,y,…}] | 尝试在约束条件 cons 下求 f 的全局极小值 |
| NMaximize[{f,cons},{x,y,…}] | 尝试在约束条件 cons 下求 f 的全局极大值 |
NMinimize[{x ^ 4 - 3x ^ 2 + x, x > 0}, x]NMinimize[{x + 2y, x ^ 2 + y ^ 2 <= 1}, {x, y}]对这个例子,Minimize 可以给出精确结果:
Minimize[{x + 2y, x ^ 2 + y ^ 2 <= 1}, {x, y}]Minimize[{Cos[x + 2y], x ^ 2 + y ^ 2 <= 1}, {x, y}]给出一个数值近似,实际上是使用了 NMinimize:
N[%]| LinearProgramming[c,m,b] | 求在约束条件 |
| LinearProgramming[c,m,b,l] | 使用约束条件 |
Minimize[{2x + 3y, x + 5y >= 10, x - y >= 2, x >= 1}, {x, y}]LinearProgramming[{2, 3}, {{1, 5}, {1, -1}, {1, 0}}, {10, 2, 1}]LinearProgramming[{2, 3}, {{1, 5}, {1, -1}, {1, 0}}, {{10, -1}, {2, 1}, {1, 1}}]在进行数值操作如 NDSolve 和 NMinimize 时,Wolfram 语言默认地使用机器精度数. 但是通过设置选项 WorkingPrecision->n 用户可以使用任意 n 位精度的数字.
NIntegrate[Sin[Sin[x]], {x, 0, 1}]NIntegrate[Sin[Sin[x]], {x, 0, 1}, WorkingPrecision -> 30]如果用户对 WorkingPrecision 给出设置,这就通常定义了计算所得结果的精度的上限. 但是在这个约束条件下,用户可以告诉 Wolfram 语言自己想要达到的精度和准确度为多少. 用户应该意识到对于许多不同种的数值操作,如果只对精度目标和准确度目标增加小数目的数位,通常会大幅度地增加计算时间. 然而,在许多情况下,确保获得高精度和准确度是很重要的.
| WorkingPrecision | 内部计算中保持的精度位数 |
| PrecisionGoal | 尝试获得的精度的位数 |
| AccuracyGoal | 尝试获得的准确度的位数 |
NIntegrate[Sin[Sin[x]], {x, 0, 1}, WorkingPrecision -> 30, PrecisionGoal -> 25]NIntegrate[Sin[Sin[x]], {x, 0, 1}, WorkingPrecision -> 30, PrecisionGoal -> 50, MaxRecursion -> 20]
给定 WorkingPrecision 的特殊设置,在 Wolfram 语言中数值操作的每个函数对 PrecisionGoal 和 AccuracyGoal 使用某种默认设置. 典型情况是 NDSolve,其中这些默认设置相当于对 WorkingPrecision 给定的设置的一半大小.
精度和准确度目标通常可以应用于返回的最终结果和关于其不同范数或误差估计. 在 Wolfram 语言中数值操作的函数通常不断尝试修订结果,直到达到指定的精度目标或准确度目标为止. 如果这两个目标之一设置为 Infinity,那么只考虑另一个目标.
在使用 N[expr,n] 进行普通数值计算时,Wolfram 语言自动调整内部计算以在结果中达到 n 位精度. 但是在对函数进行数值操作时,实际上经常需要更加明确地指明 WorkingPrecision 和 PrecisionGoal.
| StepMonitor | 当采取一个成功的步进时,所计算的表达式 |
| EvaluationMonitor | 当输入的函数被计算时,所计算的表达式 |
FindRoot[Cos[x] == x, {x, 1}, StepMonitor :> Print[x]]Reap[FindRoot[Cos[x] == x, {x, 1}, StepMonitor :> Sow[x]]]Block[{ct = 0}, {FindRoot[Cos[x] == x, {x, 1}, StepMonitor :> ct++], ct}]Reap[FindRoot[Cos[x] == x, {x, 5}, StepMonitor :> Sow[x]]]Reap[FindRoot[Cos[x] == x, {x, 5}, EvaluationMonitor :> Sow[x]]]ListPlot[Reap[NIntegrate[1 / Sqrt[x], {x, -1, 0, 1}, EvaluationMonitor :> Sow[x]]][[2, 1]]]Method 选项.
对于特定类型的数值计算,经常有一些已知的不同方法. 通常 Wolfram 语言支持在已有文献中被最广泛使用的成功算法,以及那些没有广泛被使用的算法. 对于任何特定问题,通常以相当大的努力自动挑选最好的方法. 但是如果用户对一个问题掌握了丰富的知识,或者用户正在研究符合自身利益的数值方法,用户可能会发现明确告诉 Wolfram 语言应该使用什么方法是有益的. 函数参考页面列出了 Wolfram 语言内置的一些方法;其他函数在 "数值及相关函数" 中或其他高等文档中进行讨论.
try[m_] := Block[{s = e = 0}, NDSolve[{y''[x] + Sin[y[x]] == 0, y'[0] == y[0] == 1}, y, {x, 0, 100}, StepMonitor :> s++, EvaluationMonitor :> e++, Method -> m];{s, e}]try[Automatic]try /@ {"Adams", "BDF", "ExplicitRungeKutta", "ImplicitRungeKutta", "Extrapolation"}Table[try[{"ExplicitRungeKutta", "DifferenceOrder" -> n}], {n, 4, 9}]由简单代数公式表示的函数在其输入有微小的改变时,输出也仅有微小改变. 但对建立在执行程序上的函数,常常表现出对输入几乎任意的敏感依赖. 这种现象发生的主要原因是程序“挖掘”输入的有效数字变得越来越少.
NestList[FractionalPart[2#]&, 0.1111, 10]NestList[FractionalPart[2#]&, 0.1112, 10]FractionalPart[2x] 根据数 x 的二进制数位进行计算,其做法特别简单:删去第一位,将剩余的位向左移. 经过几步以后得到的结果不可避免地对远离右边的数据位是敏感的,对最初的 x 值有很小的影响.
RealDigits[Take[%, 5], 2, 8, -1]以一个特定精度给出输入时,也就是仅指定了一定的位数. 一旦所有的位数被“”完,就不再能得到精确结果,因为这需要知道原始输入的更多位数. 只要使用任意精度数,Wolfram 语言将自动地保持跟踪这种精度的退化,这表明了在 0.×10e 上没有剩余有效数位的数,正如 "任意精度的数" 中所述.
NestList[FractionalPart[40#]&, N[1 / 9, 20], 20]Map[Precision, %]NestList[FractionalPart[40#]&, 1 / 9, 10]如果使用任何类型的近似数,那么在类似于上述的例子中,最后总是用完精度. 但是,只要使用任意精度数, Wolfram 语言将明确显示所出现的精度降低. 而使用机器精度数,Wolfram 语言将不保持精度的跟踪,这样用户将无法辨别什么时候结果变得没有意义.
NestList[FractionalPart[40#]&, N[1 / 9], 20]重复计算 FractionalPart[2x],将依次提取所给出的数的二进制数位. 如果这些数位明显是随机的——如 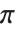 中的数位——那么结果将相应是随机的. 但是如果数位有简单类型——如有理数——那么得到的结果将相应是简单的.
中的数位——那么结果将相应是随机的. 但是如果数位有简单类型——如有理数——那么得到的结果将相应是简单的.
然而通过重复计算 FractionalPart[3/2x],即使对非常简单的输入也可能得到看起来是随机的序列. 这是一个非常一般的现象的例子,是作者 Stephen Wolfram 在1980年代的中期首先确立的,其与输入的敏感依赖性没有直接关系.
NestList[FractionalPart[3 / 2#]&, 1, 15]N[%]Take[N[NestList[FractionalPart[3 / 2#]&, 1, 1000]], -5]Take[NestList[FractionalPart[3 / 2#]&, 1., 1000], -5]NDSolve[{x''[t] + 0.15 x'[t] - x[t] + x[t] ^ 3 == 0.3 Cos[t], x[0] == -1, x'[0] == 1}, x, {t, 0, 50}]Plot[Evaluate[x[t] /. %], {t, 0, 50}]NDSolve[{x''[t] + 0.15 x'[t] - x[t] + x[t] ^ 3 == 0.3 Cos[t], x[0] == -1, x'[0] == 1.001}, x, {t, 0, 50}]Plot[Evaluate[x[t] /. %], {t, 0, 50}]