

LocationTest
LocationTest[data]
检验 data 的均值或中位数是否为零.
LocationTest[{data1,data2}]
检验 data1 与 data2 的均值或中位数是否相等.
LocationTest[dspec,μ0]
检验相对于 μ0 的一种位置度量.
LocationTest[dspec,μ0,"property"]
返回 "property" 的值.
更多信息和选项




- LocationTest 对 data 进行假设检验,其中零假设
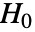 假定真实的总体位置参数为
假定真实的总体位置参数为 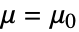 的某个值,而备择假设
的某个值,而备择假设 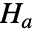 为
为 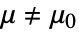 .
. - 给定 data1 和 data2,LocationTest 检验零假设
 与备择假设
与备择假设 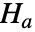 ,其中每个检验
,其中每个检验  和
和  被相应定义.
被相应定义. - 缺省返回一个概率值或称
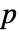 值.
值. - 小的
 值表明
值表明  不可能为真.
不可能为真. - dspec 中的数据可以为一元型{x1,x2,…} 或多元型{{x1,y1,…},{x2,y2,…},…}.
- 自变量 μ0 可以为实数,或长度等于数据维数的实数向量.
- LocationTest[dspec] 将选择适用于 dspec 的效能最强的检验方法.
- LocationTest[dspec,Automatic] 等价于
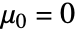 .
. - LocationTest[dspec,μ0,All] 将选择适用于 dspec 的所用检验.
- LocationTest[dspec,μ0,"test"] 报告基于 "test" 的
 值 .
值 . - 基于均值的检验假定 dspec 中的数据为正态分布. 有些检验假定数据关于一个公共中位数对称. 无对称性或正态性假定的检验被归为鲁棒一类.
- 配对样本检验假定等长相关数据.
- 可以使用下列检验:
-
"PairedT" 正态性 方差未知的配对样本检验 "PairedZ" 正态性 方差已知的配对样本检验 "Sign" 鲁棒性 单一或配对样本的中位数检验 "SignedRank" 对称性 单一或配对样本的中位数检验 "T" 正态性 一个或两个样本的均值检验 "MannWhitney" 对称性 两个独立样本的中位数检验 "Z" 正态性 方差已知的均值检验 - "T" 检验对一元数据进行学生
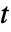 检验,对多元数据进行 Hotelling's
检验,对多元数据进行 Hotelling's 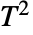 检验.
检验. - 对于一元数据,"Z" 检验在样本方差为已知方差的假定下,进行
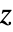 检验;对于多元数据,在样本协方差为已知协方差的假定下,进行 Hotelling's
检验;对于多元数据,在样本协方差为已知协方差的假定下,进行 Hotelling's 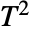 检验.
检验. - "PairedT" 与 "PairedZ" 检验关于两个数据集合的成对差值进行 "T" 检验和"Z" 检验. 单一数据集被当作差值的列表.
- LocationTest[dspec,μ0,"HypothesisTestData"] 返回一个 HypothesisTestData 对象 htd,该对象可通过使用形式htd["property"]提取额外的检验结果与性质.
- LocationTest[dspec,μ0,"property"] 可以直接给出"property" 的值.
- 与检验结果报告相关的性质包括:
-
"AllTests" 所有适用检验的列表 "AutomaticTest" 使用 Automatic 时所选择的检验 "DegreesOfFreedom" 检验中所用的自由度 "PValue" 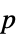 值列表
值列表"PValueTable" 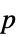 值的格式化表格
值的格式化表格"ShortTestConclusion" 检验结论的简单说明 "TestConclusion" 检验结论的说明 "TestData" 检验统计量与 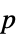 值的数对列表
值的数对列表"TestDataTable" 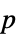 值与检验统计量的格式化表格
值与检验统计量的格式化表格"TestStatistic" 检验统计量的列表 "TestStatisticTable" 检验统计量的格式化表格 - 可以使用下列选项:
-
AlternativeHypothesis "Unequal" 备择假设的不等式 MaxIterations Automatic 多元中位数检验的最大迭代数 Method Automatic 计算 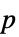 值所用的方法
值所用的方法SignificanceLevel 0.05 诊断与报告的截止值 VerifyTestAssumptions Automatic 应该验证的假定 - 对于位置检验,所选择的截止值
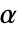 使得
使得 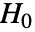 仅在
仅在  时被拒绝. 用于 "TestConclusion" 和 "ShortTestConclusion" 性质的
时被拒绝. 用于 "TestConclusion" 和 "ShortTestConclusion" 性质的 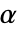 值由 SignificanceLevel 选项控制. 值
值由 SignificanceLevel 选项控制. 值  同时用于包括正态性、等方差性与对称性检验在内的假定的诊断检验. 默认情况下,
同时用于包括正态性、等方差性与对称性检验在内的假定的诊断检验. 默认情况下,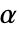 设置为 0.05.
设置为 0.05. - 在 LocationTest 中,VerifyTestAssumptions 的命名设置包括:
-
"EqualVariance" 验证 data1 与 data2 的方差相等 "Normality" 验证所有数据为正态分布 "Symmetry" 验证所有数据对称
范例
打开所有单元 关闭所有单元基本范例 (3)
范围 (17)
检验 (13)
使用 Automatic 等价于检验均值为零:
另一种检验方法是相对于 {0.1,0,-0.05,0} 进行检验:
使用 Automatic 将进行的是一般情况下最有效的检验:
性质 "AutomaticTest" 可用于确定所选择的检验方法:
对于重复提取的性质,创建一个 HypothesisTestData 对象:
从 HypothesisTestData 中提取某些性质:
选项 (20)
AlternativeHypothesis (3)
Method (6)
SignificanceLevel (3)
应用 (4)
属性和关系 (9)
将检验的大小设置为 0.05,错误否定 ![]() 的可能性大概为 5%:
的可能性大概为 5%:
检验的功效有六种不同的水平. 一般说来,Sign 检验的功效最低:
成对检验假定一个数据集的观测结果与另一个数据集的观测结果匹配:
成对 ![]() 检验等价于应用于两个数据集的点和点之间的差异的
检验等价于应用于两个数据集的点和点之间的差异的 ![]() 检验:
检验:
当输入为 TimeSeries 时,LocationTest 只能用于数值:
当输入为 TemporalData,LocationTest 可用于所有的值:
可能存在的问题 (3)
文本
Wolfram Research (2010),LocationTest,Wolfram 语言函数,https://reference.wolfram.com/language/ref/LocationTest.html.
CMS
Wolfram 语言. 2010. "LocationTest." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/LocationTest.html.
APA
Wolfram 语言. (2010). LocationTest. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/LocationTest.html 年