

SignedRankTest
SignedRankTest[data]
data の中央値が0かどうかの検定を行う.
SignedRankTest[{data1,data2}]
data1-data2の中央値が0かどうかの検定を行う.
SignedRankTest[dspec,μ0]
μ0について位置測定の検定を行う.
SignedRankTest[dspec,μ0,"property"]
"property"の値を返す.
詳細とオプション



- SignedRankTestは,帰無仮説
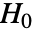 と対立仮説
と対立仮説 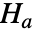 で検定を行う.
で検定を行う. -
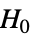
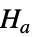
data 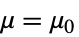
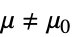
{data1,data2} 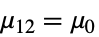
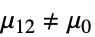
- ただし,μ は data の母集団中央値,μ12は2つのデータ集合のペアになった差分
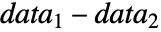 の中央値である.
の中央値である. - デフォルトで,確率値つまり
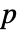 値が返される.
値が返される. - 小さい
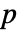 値は
値は 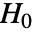 が真である可能性が低いことを示唆している.
が真である可能性が低いことを示唆している. - dspec 中のデータは一変量{x1,x2,…}でも多変量{{x1,y1,…},{x2,y2,…},…}でもよい.
- 2つのサンプルを与える場合,両者は同じ長さでなければならない.
- 引数 μ0は実数あるいはデータの次元と同じ長さの実ベクトルでよい.
- SignedRankTestは一変量の場合はデータが中央値について対称であり,多変量の場合はデータが中央値について楕円対称であると仮定する.ゆえに,SignedRankTestは平均検定でもある.
- SignedRankTest[dspec,μ0,"HypothesisTestData"]はHypothesisTestDataオブジェクト htd を返す.これは htd["property"]として追加的な検定結果と特性の抽出に使うことができる.
- SignedRankTest[dspec,μ0,"property"]を使って直接"property"の値を与えることができる.
- 検定結果のレポートに関連する特性
-
"DegreesOfFreedom" 検定で使用される自由度 "PValue" 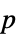 値のリスト
値のリスト "PValueTable" 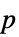 値のフォーマットされた表
値のフォーマットされた表"ShortTestConclusion" 検定結果の簡単な説明 "TestConclusion" 検定結果の説明 "TestData" 検定統計と 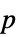 値のペアのリスト
値のペアのリスト"TestDataTable" 検定統計と 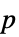 値のフォーマットされた表
値のフォーマットされた表"TestStatistic" 検定統計のリスト "TestStatisticTable" 検定統計のフォーマットされた表 - SignedRankTestはSignTestより強力な選択肢である.
- 一変量のサンプルについては,ペアになったサンプルの中央値についてSignedRankTestはウィルコクソン(Wilcoxon)の符号順位検定を行う.置換に基づいた
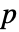 値にはタイの修正が行われる.デフォルトで,検定統計は連続性について修正され,漸近的な結果が返される.
値にはタイの修正が行われる.デフォルトで,検定統計は連続性について修正され,漸近的な結果が返される. - 多変量のサンプルについては,SignedRankTestは標準化された空間的符号順位を用いて,ペアのサンプルについてアフィン不変量検定を行う.検定統計はChiSquareDistribution[dim]に従うと仮定される.ただし,dim はデータの次元である.
- 使用可能なオプション
-
AlternativeHypothesis "Unequal" 対立仮説のための不等式 MaxIterations Automatic 多変量中央値検定のための最大反復回数 Method Automatic 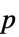 値を計算するメソッド
値を計算するメソッドSignificanceLevel 0.05 診断とレポートのための切捨て VerifyTestAssumptions Automatic どの仮定を検証するか - SignedRankTestでは,
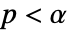 のときにのみ
のときにのみ 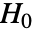 が棄却されるような切捨て
が棄却されるような切捨て 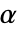 が選択される.特性"TestConclusion"および"ShortTestConclusion"で使われる
が選択される.特性"TestConclusion"および"ShortTestConclusion"で使われる 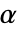 の値はSignificanceLevelオプションで制御される.
の値はSignificanceLevelオプションで制御される.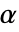 の値は対称性の検定を含む仮定の診断検定にも使われる.デフォルトで,
の値は対称性の検定を含む仮定の診断検定にも使われる.デフォルトで,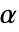 は0.05に設定されている.
は0.05に設定されている. - SignedRankTestにおけるVerifyTestAssumptionsの名前付き設定
-
"Symmetry" すべてのデータが対称であることを証明する
例題
すべて開く すべて閉じる例 (4)
多変量母集団の空間的中央値がなんらかの値かどうかの検定を行う:
繰り返し特性を抽出するためにHypothesisTestDataオブジェクトを作る:
スコープ (13)
検定 (10)
Automaticを使うことは,ゼロの中央値について検定することと同じである:
多変量母集団の中央値ベクトルがゼロベクトルであるかどうかを検定する:
2つの多変量母集団の中央値の差分ベクトルがゼロベクトルであるかどうかの検定を行う:
繰り返し特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
HypothesisTestDataオブジェクトから特性を抽出する:
オプション (12)
AlternativeHypothesis (3)
MaxIterations (2)
Method (4)


アプリケーション (1)
特性と関係 (8)
SignedRankTestは一般にSignTestよりも強力である:
一変量のウィルコクソン(Wilcoxon)の符号順位検定統計:
タイがないので,Orderingを使って順位を計算することができる:
多変量データについては,検定統計は ![]() においてChiSquareDistributionに従う:
においてChiSquareDistributionに従う:
多変量データについては,SignedRankTestは事実上単位球の一様性について検定を行う:
μ0からの偏差は,空間符号順位のクラスタとより大きい検定統計を返す:
符号順位検定は,入力がTimeSeriesのときにのみ値に使うことができる:
符号順位検定は,入力がTemporalDataのときには,すべての値に同時に使うことができる:
考えられる問題 (1)
テキスト
Wolfram Research (2010), SignedRankTest, Wolfram言語関数, https://reference.wolfram.com/language/ref/SignedRankTest.html.
CMS
Wolfram Language. 2010. "SignedRankTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/SignedRankTest.html.
APA
Wolfram Language. (2010). SignedRankTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/SignedRankTest.html