

VarianceEquivalenceTest
VarianceEquivalenceTest[{data1,data2,…}]
dataiの分散が等しいかどうかの検定を行う.
VarianceEquivalenceTest[{data1,…},"property"]
"property"の値を返す.
詳細とオプション



- VarianceEquivalenceTestは,真の母分散が同一である(
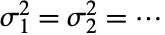 )という帰無仮説
)という帰無仮説 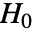 と少なくとも1つの分散が異なるという対立仮説
と少なくとも1つの分散が異なるという対立仮説 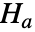 で dataiについて仮説検定を行う.
で dataiについて仮説検定を行う. - デフォルトで,確率値すなわち
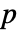 値が返される.
値が返される. 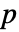 値が小さい場合は
値が小さい場合は 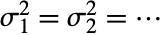 である可能性が低いことを示唆する.
である可能性が低いことを示唆する.- data は一変量{x1,x2,…}でなければならない.
- VarianceEquivalenceTest[{data1,…}]はデータに適用可能で最も強力な検定を選ぶ.
- VarianceEquivalenceTest[{data1,…},All]はデータに適用可能な検定をすべて選ぶ.
- VarianceEquivalenceTest[{data1,…},"test"]は"test"に従って
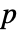 値をレポートする.
値をレポートする. - ほとんどの検定は正規分布に従う dataiを必要とする.検定が正規性の仮定についてそれほど敏感ではない場合,その検定は強力であると呼ばれる.検定の中には datai が中央値に対して対称であると仮定するものもある.
- 使用可能な検定
-
"Bartlett" 正規性 修正尤度比検定 "BrownForsythe" 頑健性 頑健なLevene検定 "Conover" 対称性 Conoverの二乗順位’検定 "FisherRatio" 正規性 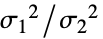 に基づく
に基づく"Levene" 頑健性,対称性 個々の分散とグループの分散を比較する - VarianceEquivalenceTest[{data1,…},"HypothesisTestData"]は htd["property"]の形で追加的な検定結果と特性の抽出に利用できるHypothesisTestDataオブジェクト htd を返す.
- VarianceEquivalenceTest[{data1,…},"property"]を使って直接"property"の値を与えることができる.
- 検定結果のレポートに関連する特性
-
"AllTests" 適用可能なすべての検定のリスト "AutomaticTest" Automaticが使われた場合に選ばれる検定 "DegreesOfFreedom" 検定で使われる自由度 "PValue" 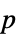 値のリスト
値のリスト"PValueTable" 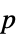 値のフォーマットされた表
値のフォーマットされた表"ShortTestConclusion" 検定結果の簡単な説明 "TestConclusion" 検定結果の説明 "TestData" 検定統計と 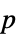 値のペアのリスト
値のペアのリスト"TestDataTable" 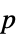 値と検定統計のフォーマットされた表
値と検定統計のフォーマットされた表"TestStatistic" 検定統計のリスト "TestStatisticTable" 検定統計のフォーマットされた表 - 使用可能なオプション
-
SignificanceLevel 0.05 診断とレポートのための切捨て VerifyTestAssumptions Automatic どの診断検定を実行するかを決める - 分散検定では,
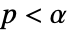 のときにのみ
のときにのみ 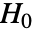 が棄却されるような切捨て
が棄却されるような切捨て 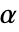 が選ばれる."TestConclusion"および"ShortTestConclusion"特性に使われる
が選ばれる."TestConclusion"および"ShortTestConclusion"特性に使われる 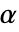 の値はSignificanceLevelオプションで制御される.値
の値はSignificanceLevelオプションで制御される.値 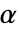 は正規性と対称性の検定を含む仮定の診断検定にも使われる.デフォルトで
は正規性と対称性の検定を含む仮定の診断検定にも使われる.デフォルトで 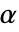 は0.05である.
は0.05である. - VarianceEquivalenceTestにおけるVerifyTestAssumptionsの名前付き設定
-
"Normality" すべてのデータが正規分布に従っていることを証明する "Symmetry" すべてのデータが対称であることを証明する
例題
すべて開く すべて閉じる例 (2)
さらに特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
スコープ (12)
検定 (8)
Automaticを使うと,一般に最も強力で適切な検定が適用される:
特性"AutomaticTest"は,どの検定が選ばれたのかを調べるのに使える:
SmoothHistogramを使って視覚的にデータ集合の分布を比べる:
特性"AllTests"を使ってどの検定が使われたのかを調べる:
繰り返し特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
HypothesisTestDataオブジェクトから特性をいくつか抽出する:
オプション (6)
SignificanceLevel (3)
アプリケーション (2)
最初のデータ集合群は全く異なる分散を持つ母集団から引き出された:
LocationEquivalenceTestを使っていくつかのデータ集合の平均を同時に比べることができるが,データ集合は共通の分散を持っていなければならない:
VarianceEquivalenceTestを使って分散が等しいかどうかを調べる:
LocationEquivalenceTestを使って平均を比べることができる:
特性と関係 (5)
Brown–Forsythe検定とルベーン(Levene)検定は等しいが,異なる標準化関数を使う:
ルベーン検定はMeanを使ってデータを標準化する:
Brown–Forsythe検定は通常Medianを使う:
裾部の重いデータについては,10%のTrimmedMeanが代りに使われる:
![]() 個のデータ集合と
個のデータ集合と ![]() 個の合計観察について,Brown–Forsythe検定とルベーン検定はどちらも
個の合計観察について,Brown–Forsythe検定とルベーン検定はどちらも ![]() においてFRatioDistribution[k-1,n-k]に従う:
においてFRatioDistribution[k-1,n-k]に従う:
![]() において検定統計はChiSquareDistribution[k-1]に従う:
において検定統計はChiSquareDistribution[k-1]に従う:
分散の等価性検定は,入力がTimeSeriesのときはタイムスタンプを無視する:
分散の等価性検定は,TemporalDataの経路構造を認識する:

テキスト
Wolfram Research (2010), VarianceEquivalenceTest, Wolfram言語関数, https://reference.wolfram.com/language/ref/VarianceEquivalenceTest.html.
CMS
Wolfram Language. 2010. "VarianceEquivalenceTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/VarianceEquivalenceTest.html.
APA
Wolfram Language. (2010). VarianceEquivalenceTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/VarianceEquivalenceTest.html