ニューラルネット入門
ニューラルネット入門
このチュートリアルでは,1桁の手書き数字の画像を入力として取り,その数字を予測するネットを訓練する方法を示すことによって,Wolfram言語のニューラルネットフレームワークの概要を紹介する.訓練に使うデータ集合はMNISTデータ集合であり,Wolfram Neural Net Repositoryで利用可能な 最初のたたみ込みネットの一つであるLeNetの変形を訓練する.
LeNetのようなネットワークを一から訓練することは非常に簡単である.NetTrainを使うことで,適切な損失関数を選んだり,エンコーダやデコーダを加えたり,バッチサイズを選んだりすることが自動的に処理される.これを次で見てみる.
Wolfram言語におけるディープラーニングの基本を提示するために,コンポーネント層からLeNetを構築し,損失関数を選び,訓練ネットワークを定義し,エンコーダとデコーダを加え,最後にネットワークを訓練して評価する,という「難しい方法」を行ってみる.この特定のタスクの裏側にある一般原則を理解することで,Wolfram言語を使って簡単に,しかも効率的に高度な学習タスクに取り組むことができるようになる.
NetExtractを使って,ネットの最後の層を抽出する:
SoftmaxLayerは総和が1となる確率を出力するためのものである.
ConvolutionLayerやLinearLayer等,一部の層だけが学習可能なパラメータを持つ.そのような層は常に表示フォームに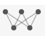 アイコンを含んでいる.これに対して,アイコン
アイコンを含んでいる.これに対して,アイコン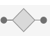 を持つ層は学習可能なパラメータを含んでいない.
を持つ層は学習可能なパラメータを含んでいない.
NetInitializeを使うと,学習可能なパラメータにランダムな値を与えることができる.
ここまでは1つの入力だけを取る層を見てきた.層の中には2つ以上の入力を取るものもある.例えば,MeanSquaredLossLayerは「入力」と「ターゲット」という2つの配列を比較し,Mean[(input-target)^2]を表す1つの数を出力する.
MeanSquaredLossLayerを作成する:
層にはニューラルネットフレームワークに特有の機能を導入するものもあれば,既存のWolfram言語のシンボルの機能に酷似したものもある.例えば,FlattenLayerはFlattenに,DotLayerはDotによく似ている.
層のその他の特性(高度なトピック)
- 層は,入力と出力が「常に配列かスカラー」である関数である.音声や画像等に使用するためには,入力にNetEncoderが付いていなければならない.
- 層はTargetDeviceオプションを指定するさまざまなバックエンド(CPU, CUDA, CoreML, …)を使って実行することができる.
- TargetDeviceオプションを指定すると,層はCPU上でもNVIDIA GPU上でも訓練できる.
- デフォルトでは,層はWolfram言語の関数で通常使われる数値精度より低い数値精度(単精度浮動小数点数)を使って評価される.異なる動作を指定するためには.WorkingPrecisionオプションを使うことができる.
ニューラルネットの層は基本的に「微分可能」でなければならないので,配列に作用する.しかし,画像,音声,テキスト等別のデータでネットを訓練し使用したい場合もある.この場合,NetEncoderを使うとこのデータを値の配列に変換することができる.
MNISTデータ集合の数字の画像を変換するために,"Image"エンコーダを使う.実際どのように使われるかを示す簡単な例を見てみよう.
画像NetEncoderを画像に適用する:
画像NetEncoderを大きいカラー画像に適用する:
上で行ったように,エンコーダはネットとは独立で使用することができるが,層に加えて使う方が一般的である.これは,層を作成するときにでも後ででも行うことができる.次はエンコーダを付けた層を作成する例である.
MNISTの"Image"エンコーダを作成する:
ニューラルネットの出力は予測であることが多い.回帰問題では,この予測は通常推定値,つまりネットがタスクに対して最もあり得ると推定する値を表す1つの数値である.このような出力は通常復号化される必要はない.
しかし,分類問題の場合,ネットの出力は通常,要素が各クラスの確率を表すベクトルである.例えば,食べ物の画像を「ホットドッグ」,「ピザ」,「サラダ」と分類するネットは,この3つのクラスの確率を表す和が1となる,3つの成分を持つベクトルを出力する.
このようなクエリをもっと簡単にするために,"Class" NetDecoderを使ってベクトル成分とクラスの間のマッピングを保存し,ネットの出力を自動的に解釈するすることができる.出力をImage,ブール値等に変換するための他の種類のNetDecoderも可能であるが,このチュートリアルではそこまでの詳細には言及しない.
NetEncoderの場合と同様に,層の出力にNetDecoderを加えることができる.以下は先に提示したPoolingLayerのより合理化された例である.ここでは"Image" NetEncoderを使って層への入力を解釈し,"Image" NetDecoderを使って層の最終的な出力を画像に戻す.
最も簡単に層をまとめる方法は,次々と繋いでいくことである.これでは,最初の層の出力が次の層の入力として使われる.このように層を繋ぐにはNetChainコンテナを使うとよいが,もっと複雑な接続方法が必要な場合はNetGraphを使う.
NetChainを入力に適用する:
グラフ
LeNetを訓練するためには,個々の訓練の例をLeNetに与える「訓練ネットワーク」を構築する必要がある.MNISTデータ集合の訓練の例はどれも,入力画像とそれに対応するターゲットラベルの組み合わせからなる.
NetChainではネットは2つ以上の入力を取ることができないため,訓練ネットワークを構築するためにはNetGraphを使う必要がある.訓練ネットワークのタスクは,LeNetによって生成された予測を評価することであり,予測が正しい場合は小さい数字を生成し,正しくない場合は大きい数字を生成する.これは「損失」と呼ばれる.これは予測誤差のある種の代用物と見ることができる.
この訓練ネットワークが準備できたら,NetTrain関数を使って,時間の経過とともに損失が減少するように,ネットの学習可能パラメータを徐々に変更することができる.
異なる学習タスクでは,損失を計算するのに異なる方法が使われなければならない.MNISTの数字の分類等の分類タスクでは,よくある損失は「交差エントロピー」である.層CrossEntropyLossLayerは,予測と真のラベル(またはターゲット)が与えられると,この損失を計算することができる.
次は,予測を採点するのに使われるCrossEntropyLossLayerの簡単な例である.
ターゲットラベルを持つ長さ5の入力の予測ベクトルを計算するCrossEntropyLossLayerを作成する:
層と接続のリストを与えることによってNetGraphを構築する.グラフへの入力はNetPort["input"]destination を使って層と接続され,損失層への入力はsource->NetPort["loss","input"]で接続される:
これらの損失は,LeNetが,与えられた画像についてうまくターゲットを予測していることを示している.LeNetはランダムに初期化されたため,平均して偶然にすぎないと予測する.訓練中,LeNetの学習可能パラメータは徐々に平均損失を引き下げるよう調整されている.
どれはどのようにして可能になったのだろうか.ここで重要なのが「勾配」である.勾配は,誤差逆伝播法と呼ばれる処理を介して計算できる,学習可能なパラメータの調整である.この調整は,指定された一団の例での訓練ネットの平均損失をわずかに減少させるために導かれる.
この過程は,訓練課程を調整あるいは微調整する方法を多数提供するNetTrainによって処理される.しかし,NetPortGradientを使って,これらの勾配の一つを直接計算することによって,関連するメカニズムの本質を垣間見ることができる.
NetTrainを使って作成したネットワークを訓練してみる.
通常,NetTrainは訓練ネットワークを自動的に構築する.例えば,入力と出力がそれぞれ1つずつの簡単なネットワークの場合,ネットに ini を与え,適切な損失関数を使ってネットの出力を outi と比較することによって, {in->out,…}という形式の訓練データを作成する.
しかし,明示的に訓練ネットワークを構築したので,訓練データは<"port"->list,…>という形式で提供する必要がある.ここで訓練ネットの入力ポートに明示的にデータのリストを与える.まず in->out という規則の形式のデータを変換しなければならない.
さらに,訓練データには整数0から9のラベルが含まれ,訓練ネットの「ターゲット」入力には範囲1から10までの指標が想定されていると言う事実を説明する必要がある."Class" NetEncoderを使ってそれらを変換する(通常NetTrainが自動的に行う)ことができるが, 1を足すだけで同じものが得られる.
ここでNetTrainを使って訓練を実行する.このネットについて以下のようなことに注意する.
- 終了するまでに訓練集合全体を5回スキャンするよう,MaxTrainingRounds->5と指定した.
- 訓練セッションについてさまざまな情報を要約するNetTrainResultsObjectを得るために,第3引数としてAllを与えた.
- ValidationSetを与えたことで,訓練された分類子が,訓練されていない新しい例にどれほどうまく一般化されるかを測定することができる.これによって,「過適合」というよくある落とし穴に落ちることが避けられる.
- TargetDevice->"CPU"を指定した(デフォルト).しかし,NVIDIAグラフィックスカードを持っている場合は,これを"GPU"に変更することで,訓練の時間がかなり短縮できる.
最後のNetTrainResultsObjectによって大量の情報が得られる.そのうちの一部は表示形式で得られるが,プログラムによってより多くの情報を取得することができる.我々のネットワークは,CPU訓練を3分行っただけで,約99.4%の正確さが達成できたことが分かる.
NetTrainResultsObjectから損失進化プロットを得る:
NetTrainResultsObjectから訓練ネットを得て,それから予測ネットワークを抽出する:
- NetEncoderとNetDecoderを使って,配列と他の形式のデータの間の変換を行う方法
- CrossEntropyLossLayerを使って,予測ネットの損失を計算する訓練ネットを構築する方法
- 訓練データを使って,ネットを訓練するNetTrainを呼び出す方法
ネットを訓練し終えたので,それについてもっと多くの情報を引き出すことができる.例えば,別のデータ集合についての全体的な正確さを得ることができる.また,ネットがどの程度例を誤って分類するかを要約する「混同行列」等の便利な概略を得ることもできる.深層学習を使うネットの性能を他の一般的な機械学習テクニックの性能と比較することもできる.
データ集合に対するネットの分類動作のさまざまな特性を測定するClassifierMeasurementsObjectを構築してみよう.訓練に使用しなかったデータ集合を使うことが大切なので,MNISTデータセットに同梱の検証集合を使う.
ClassifierMeasurementsObjectができたので,あらゆる種類の特性を効率的にクエリすることができる.
NetMeasurementsを使って,ネットのさまざまな特性を測定することもできる.NetMeasurementsとClassifierMeasurementsには,同じ特性も多数あるが,それぞれにしかないものもある.NetMeasurementsは効率的に実装されており,TargetDevice"GPU"オプションを使ってNVIDIAグラフィックスカード上でも実行できるいう利点があるため,大規模のデータセットに非常に適している.
NetMeasurementsはニューラルネットワークについて,他の利点もある.ネットワーク内の任意の層の出力および重さを測定することができる.
さらにNetMeasurementsはキャッシュを使って,同じ特性の測定の繰返しや同様の特性の測定をスピードアップする.
NetMeasurementsはClassifierMeasurementsよりも使える場合が多い.必要とされる損失層がないネット,NetEncoderやNetDecoderが付随しないネット,複数の出力を持つネットにも使える.
ネットと別の方法を比較する最も簡単な方法はClassifyを使うことである.これは広範に渡る一般的な方法を自動的に適用し,最適なものを選ぶ.
Classifyを使って,効率のよい機械学習モデルを自動的に選ぶ:
このニューラルネットは,検証集合に対してClassifyによって選らばれたモデルよりも性能がよい.