文字と文字列
オブジェクトが文字列かどうかが不明なときは,その頭部を参照する.文字列であれば,頭部はStringである.
文字列の頭部はStringである:
| s1<>s2<>… または StringJoin[{s1,s2,…}] | 複数の文字列をつなぎ合せる |
| StringLength[s] | 文字列を構成している文字の総数(長さ)を返す |
| StringReverse[s] | 文字の並び順を反対にする |
StringLengthを使って文字列の長さを調べる:
StringReverseを使い構成文字の並び順を逆にする:
| StringTake[s,n] | 文字列 s から最初の n 文字を抽出し新たな文字列を構成する |
| StringTake[s,{n}] | 文字列 s の先頭から数えて n 番目の文字を抽出し長さ1の文字列を構成する |
| StringTake[s,{n1,n2}] | 文字列 s から n1 ~ n2 番目の文字を抽出し新たな文字列を構成する |
| StringDrop[s,n] | 文字列 s から最初の n 文字を除去し残った文字を抽出し新たな文字列を構成する |
| StringDrop[s,{n1,n2}] | 文字列 s から n1 ~ n2 番目の文字を除去し残った文字を抽出し新たな文字列を構成する |
文字列の抽出関数StringTakeとStringDropはリストの抽出関数であるTakeとDropに対応している.TakeとDropと同じように,引数の指定の仕方はWolfram言語標準規定に準拠している.したがって,文字列末尾から数えた文字の位置は負の数で表す.また,文字列の先頭位置は1である.
| StringInsert[s,snew,n] | 文字列 s の n 番目の位置に新たな文字列 snew を挿入する |
| StringInsert[s,snew,{n1,n2,…}] | 文字列 s の n1 ~ n2 番目の各位置に新たな文字列 snew を挿入する |
Riffleを使い単語の間にスペースを挿入する:
| StringReplacePart[s,snew,{m,n}] | 文字列 s において m ~ n 番目の文字を新たな文字列 snew に置換する |
| StringReplacePart[s,snew,{{m1,n1},{m2,n2},…}] | 文字列 s の数個の部分文字列を snew で置換する |
| StringReplacePart[s,{snew1,snew2,…},{{m1,n1},{m2,n2},…}] | 文字列 s の部分文字列を対応する snewi で置換する |
| StringPosition[s,sub] | 文字列 s において部分列 sub が現れる開始位置と終了位置をリスト出力する |
| StringPosition[s,sub,k] | 文字列 s において現れる最初の k 個までの部分列 sub の開始位置と終了位置をリスト出力する |
| StringPosition[s,{sub1,sub2,…}] | 文字列 s において各部分列 subi の開始位置と終了位置をリスト出力する |
StringPositionを使い,1つの被検索文字列に別の検索文字列が含まれているか照合できる.検索文字列と同じ内容を持つ範囲(複数可)がリストとして返される.範囲とは開始点と終了点の位置のことである.このリスト出力による範囲指定の仕方はStringTakeとStringDropとStringReplacePartで使われる指定法と同じである.
| StringCount[s,sub] | s 中の sub の出現回数を数える |
| StringCount[s,{sub1,sub2,…}] | 任意の subi の出現回数を数える |
| StringFreeQ[s,sub] | s に sub が含まれていないかどうかを検証する |
| StringFreeQ[s,{sub1,sub2,…}] | s に subi が全く含まれていないかどうかを検証する |
| StringContainsQ[s,sub] | s に sub が含まれるかどうかを検証する |
| StringContainsQ[s,{sub1,sub2,…}] | s が subi のいずれかを含むかどうかを検証する |
| StringStartsQ[s,sub] | s が sub で始まるかどうかを検証する |
| StringStartsQ[s,{sub1,sub2,…}] | s が subi のいずれかで始まるかどうかを検証する |
| StringEndsQ[s,sub] | s が sub で終わるかどうかを検証する |
| StringEndsQ[s,{sub1,sub2,…}] | s が subi のいずれかで終わるかどうかを検証する |
| StringReplace[s,sb->sbnew] | 文字列 s において部分列 sb を文字列 sbnew で置換する |
| StringReplace[s,{sb1->sbnew1,sb2->sbnew2,…}] | |
sbi を対応する sbnewi で置換する | |
| StringReplace[s,rules,n] | 最高で n 回置換する |
| StringReplaceList[s,rules] | 可能な置換を行って得られた文字列のリストを与える |
| StringReplaceList[s,rules,n] | 最高で n 個の結果を与える |
StringReplaceは,文字列を左から右へスキャンし,できる限りすべての置換を行い,結果の文字列を返す.しかし,場合によっては1文字列につき置換を1つだけ行うことが可能な場合をすべて考慮することも有効である.StringReplaceListは,可能な限りの単一の置換の全結果をリストで与える.
| StringSplit[s] | s を空白文字で区切られた部分文字列に分割する |
| StringSplit[s,del] | del のところで分割する |
| StringSplit[s,{del1,del2,…}] | deli のところで分割する |
| StringSplit[s,del,n] | 最高で n 個の部分文字列に分割する |
| StringSplit[s,del->rhs] | 各区切り位置に rhs を挿入する |
| StringSplit[s,{del1->rhs1,del2->rhs2,…}] | rhsi を対応する deli の位置に挿入する |
| Sort[{s1,s2,s3,…}] | 文字列のリストを並べ替える |
Sortは,標準的順序(アルファベット順)に並べ替える:
| StringTrim[s] | s の始めと終りから空白を取り除く |
| StringTrim[s,patt] | 最初と最後から patt にマッチする部分文字列を取り除く |
| SequenceAlignment[s1,s2] | s1と s2の最適な配列を求める |
| Characters["string"] | 文字列を文字成分のリストに変換する |
| StringJoin[{"c1","c2",…}] | 文字成分のリストを文字列に変換する |
StringJoinを使って並べ替えた文字成分から単一文字列を再構成する:
| DigitQ[string] | 文字列の内容がすべて数字かどうか判定する |
| LetterQ[string] | 文字列の内容がすべてアルファベット文字かどうか判定する |
| UpperCaseQ[string] | 文字列の内容がすべてアルファベットの大文字かどうか判定する |
| LowerCaseQ[string] | 文字列の内容がすべてアルファベットの小文字かどうか判定する |
大文字だけではないので,答はFalseになる:
| ToUpperCase[string] | 文字列の成分をすべて大文字に変換する |
| ToLowerCase[string] | 文字列の成分をすべて小文字に変換する |
| CharacterRange["c1","c2"] | c1から c2の範囲にある文字を順番に生成しリストにする |
日常使う文字の範囲であればCharacterRangeを使うと意味のある並び順で文字が生成できる.CharacterRangeの並び順とは,Wolfram言語内部で各文字の持つ文字コードで小さい順に並べるということである.
StringReplaceのような文字列操作関数には,文字通りの文字列だけでなく,文字列の集合を表すパターンも扱えるという重要な機能がある.
| s1~~s2~~… または StringExpression[s1,s2,…] | |
一連の文字列とパターンオブジェクト | |
| StringMatchQ["s",patt] | "s"が patt にマッチするかどうか検証する |
| StringFreeQ["s",patt] | "s"が patt にマッチする部分文字列がないかどうか検証する |
| StringContainsQ["s",patt] | "s" が patt にマッチする部分文字列を含むかどうかを検証する |
| StringStartsQ["s",patt] | "s" が patt にマッチする部分文字列で始まるかどうかを検証する |
| StringEndsQ["s",patt] | "s" が patt にマッチする部分文字列で終わるかどうかを検証する |
| StringCases["s",patt] | patt にマッチする"s"の部分文字列のリストを与える |
| StringCases["s",lhs->rhs] | lhs があるごとに rhs で置換する |
| StringPosition["s",patt] | patt にマッチする文字列の位置のリストを与える |
| StringCount["s",patt] | patt にマッチする部分文字列がいくつあるか数える |
| StringReplace["s",lhs->rhs] | lhs にマッチするすべての部分文字列を置換する |
| StringReplaceList["s",lhs->rhs] | lhs を置換するすべての方法のリストを与える |
| StringSplit["s",patt] | patt にマッチするすべての部分文字列のところでs を分割する |
| StringSplit["s",lhs->rhs] | lhs の位置で区切り,代りに rhs を挿入する |
| "string" | 文字通りの文字の列 |
| _ | 任意の単一文字 |
| __ | 1つ以上の文字を持った任意の文字列 |
| ___ | 零個あるいは1つ以上の文字を持つ任意の文字列 |
| x_
,
x__
,
x___ | x という名前を与えられた部分文字列 |
| x:pattern | x という名前を与えられた部分文字列 |
| pattern.. | 1回以上繰り返されたパターン |
| pattern... | 繰り返された,あるいは繰り返されなかったパターン |
| {patt1,patt2,…} または patt1patt2… | 少なくとも patti のひとつにマッチするパターン |
| patt/;cond | cond を評価するとTrueになるパターン |
| pattern?test | 各文字についての test がTrueを返すパターン |
| Whitespace | 一連の空白文字 |
| NumberString | 数の文字 |
| charobj | 文字のクラスを表すオブジェクト(以下参照) |
| RegularExpression["regexp"] | 正規表現にマッチする部分文字列 |
| {"c1","c2",…} | 任意の"ci" |
| Characters["c1c2…"] | 任意の"ci" |
| CharacterRange["c1","c2"] | "c1"から"c2"の範囲に含まれる任意の文字 |
| DigitCharacter | 0から9までの数字 |
| LetterCharacter | 文字 |
| WhitespaceCharacter | スペース,改行,タブあるいはその他の空白文字 |
| WordCharacter | 文字あるいは数字 |
| Except[p] | p にマッチするもの以外の任意の文字 |
ToExpressionがこれらを通常の記号と数字に変換する:
多くの場合,テキストデータはスペース,改行,タブを含んでいる.これらは「空白文字」とみなされるべきであるが,往々にして無視される.では,,そのような文字列はWhitespaceで表される.
通常文字列パターンは,指定の文字列の任意の位置の部分文字列に適用される.しかしときによっては,特定の位置の部分文字列のみにパターンを適用するように指定できると便利なこともある.そのような場合は,StartOfStringのような記号を文字列パターンに含めるとよい.
| StartOfString | 文字列全体の先頭 |
| EndOfString | 文字列全体の末尾 |
| StartOfLine | 行頭 |
| EndOfLine | 行末 |
| WordBoundary | 単語文字とそれ以外の境界 |
| Except[StartOfString] 等 | 特定の位置StartOfString等以外の任意の場所 |
文字列パターンでx__あるいはe..のようなオブジェクトを与えると,通常Wolfram言語は可能な文字列のうちでマッチする最長のものが要求されていると解釈する.しかし,場合によっては可能な文字列のうちでマッチする最短のものがほしい場合もある.そのような場合はShortest[p]を使って指定することができる.
Shortestは,その代りにマッチする最短のものを求めるように指定する:
Wolfram言語はデフォルトにより文字"X"と文字"x"異なるものとして扱う.しかし,文字列操作のIgnoreCase->Trueオプションを設定することで,Wolfram言語にこのような大文字と小文字を等しいものとして扱うように指示することができる.
| IgnoreCase->True | 大文字と小文字を等しいものとして扱う |
文字列操作によっては,部分文字列の重複を含めるかどうかを指定しなければならないことがある.デフォルトのStringCasesとStringCountでは重複は含まれないが,StringPositionは重複を含む.
StringPositionは,デフォルトで重複を含む:
一般的なWolfram言語のパターンは,文字列操作のための強力な方法を提供する.しかし,特殊な文字列操作言語に精通している場合には,「正規表現」記号を用いて文字列パターンを指定したいと思うことがあるだろう.そのような場合,Wolfram言語ではRegularExpressionオブジェクトを用いる.
| RegularExpression["regex"] | "regex" で指定する正規表現 |
Wolfram言語のRegularExpressionは,標準的な正規表現のコンストラクトすべてをサポートする.
| c | そのままの文字 c |
| . | 改行以外の任意の文字 |
| [c1c2…] | ci の任意の文字 |
| [c1-c2] | c1–c2の範囲の任意の文字 |
| [^c1c2…] | ci 以外の任意の文字 |
| p* | 繰り返されたあるいは繰り返されない p |
| p+ | 繰り返された p |
| p? | p があるかないか |
| p{m,n} | m 回からn 回繰り返された p |
| p*?
,
p+?
,
p?? | マッチする最短の文字列 |
| (p1p2…) | p1p2…にマッチする文字列 |
| p1p2 | p1あるいは p2にマッチする文字列 |
| . | _ (厳密に Except["∖n"]) |
| [c1c2…] | Characters["c1c2…"] |
| [c1-c2] | CharacterRange["c1","c2"] |
| [^c1c2…] | Except[Characters["c1c2…"]] |
| p* | p... |
| p+ | p.. |
| p? | p"" |
| p*?
,
p+?
,
p?? | Shortest[p…],… |
| (p1p2…) | (p1~~p2~~…) |
| p1p2 | p1p2 |
一般的なWolfram言語の文字列パターンに見られるように,種々の文字の一般的なクラスを表す正規表現の表記法もある.Wolfram言語の正規表現文字列にこれらの記号を入れる際には,二重のバックスラッシュ(∖∖)を使わなければならないので注意のこと.
Wolfram言語は,標準的なPOSIX文字クラスのalnum,alpha,ascii,blank,cntrl,digit,graph,lower,print,punct,space,upper,word,xdigitをサポートする.
一般なWolfram言語のパターンでは,x_や x:patt のようなコンストラクトを使って,マッチするオブジェクトに任意の名前を与えることができる.正規表現では,数字を使ってこれと同じようなことをする方法がある.正規表現中の n 番目のカッコに入ったパターンオブジェクト(p)は,パターン本体内では\\n として,パターンの外では$n として参照することができる.
ノートブックを使っている場合は,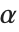 等のギリシャ文字も直接表示できる.しかし,テキスト型インターフェースを使っている場合は,通常表示できるのはキーボードにある文字や記号だけである場合が多い.厳密にどの特殊文字が表示できるかは$CharacterEncodingの値で分かる.
等のギリシャ文字も直接表示できる.しかし,テキスト型インターフェースを使っている場合は,通常表示できるのはキーボードにある文字や記号だけである場合が多い.厳密にどの特殊文字が表示できるかは$CharacterEncodingの値で分かる.
Wolframシステムのノートブックでは,StandardFormを使って特殊文字を直接表示することができる:
OutputForm(出力形)の表示では,正確に表示できない特殊文字は可能な限り普通の文字や記号を組み合せて作ったもので代替表示が行われる:
InputFormかFullFormが使われている場合,特殊文字に近似のものが使われることはない.Wolfram言語はInputFormの表現できない特殊文字に完全名を使う.一方FullFormはノートブックインターフェースでもロングネームを常に使う.
FullFormでは,すべての特殊文字がロングネームを使って書かれる:
デフォルトでは,Wolframシステムはノートブックやパッケージを保存するとき文字コード"PrintableASCII"を使う.つまり,特殊文字がファイルや外部プログラムから書き出されていても,純粋に通常の文字列として表現されるということである.この一貫した表現は,Wolfram言語の特殊文字をそれぞれのコンピュータシステムの詳細に依存しないで使えるようにするという点で不可欠である.
タブや改行コードを挿入することでWolfram言語の出力表示をある程度まで制御することは可能である.しかし,あまりよい方法とは言えない.よりよい方法は,「書式付きテキスト表示」,「数値の出力書式」,「表と行列」で説明されているWolfram言語の上級の書式プリミティブを使う方法である.後者を使えば,デバイス依存を持つタブの設定等に影響を受けずに一様な表示を常に行うことができる.
そこで,フロントエンドの配置構文であるColumnを使って列揃えで表示する.この例では,列の右側に揃えるよう指定する:
| ToCharacterCode["string"] | 文字列の各文字に対応する文字コードを返す |
| FromCharacterCode[n] | 文字コードから文字を生成する |
| FromCharacterCode[{n1,n2,…}] | 文字コードから複数文字(文字列)を生成する |
FromCharacterCodeからもとの文字列を再構成する:
| CharacterRange["c1","c2"] | 連続する文字コードの文字を順番に生成し列挙する |
Wolfram言語では,数学で使う標準的な特殊文字や記号とヨーロッパの標準的な言語の文字セットにも登録済みの名前が用意されている.しかし,日本語,中国語,韓国語のような言語のためには,何千もの文字が追加されており,明示的な名前は割り当てられていない.このため,漢字等の参照には文字コードを使う必要がある.
FullFormでは,これらの文字は標準文字コードで参照される.標準文字コードは16進法で記述されることに注意:
文字コードが256より小さい1バイトのものであれば\.nn の文字指定の書式が使える.それ以上の値を持つ2バイトの文字コードは書式\:nnnn か\nnnnnn を使わなければならない.いずれの書式を使うにしても,指定桁数のすべてを入力する必要があり,文字コードの値が小さすぎて上位の桁が空になってしまうときは0を補っておく.
Wolfram言語の使う文字コードの割当ては,3つのともに互換な標準文字コードの規格に準拠している.その規格とはASCIIとISO Latin‐1,そして,Unicode規格である.ASCII規格は英語キーボードの文字と記号の文字コード範囲を定義し,また,ISO Latin‐1規格はヨーロッパの言語で使う特殊文字の範囲を定義する.Unicode規格は前者の規格をさらに一般化し,欧州以外の漢字等の文字セットも定義している.
0–127 (∖.00–∖.7f) | ASCII領域 |
1–31 (∖.01–∖.1f) | ASCII制御文字 |
32–126 (∖.20–∖.7e) | ASCII印字可能文字 |
97–122 (∖.61–∖.7a) | 英語アルファベット小文字 |
129–255 (∖.81–∖.ff) | ISO Latin‐1領域 |
192–255 (∖.c0–∖.ff) | ヨーロッパ言語の文字セット |
0–59391 (∖:0000–∖:e7ff) | Unicodeパブリック領域 |
913–1009 (∖:0391–∖:03f1)
| ギリシャ文字セット |
12288–35839 (∖:3000–∖:8bff)
| 中国語,日本語,韓国語の文字セット |
8450–8504 (∖:2102–∖:2138)
| 数学記述で使う特殊文字 |
8592–8677 (∖:2190–∖:21e5)
| 矢印記号 |
8704–8945 (∖:2200–∖:22f1)
| 数学記述で使う演算記号 |
61440–63487 (∖:f000–∖:f7ff)
| Wolfram言語専用のUnicodeプライベート領域 |
Wolfram言語で特殊文字や記号を入力するには,英語名で参照する方法と,文字コードで参照する方法が使える.例えば,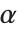 を入力するには,∖[Alpha]か∖:03b1をタイプする.Wolfram言語から文字列等をファイルに落とすときも,特に指定がなければ,これら2つの書式のどちらかが使われる.
を入力するには,∖[Alpha]か∖:03b1をタイプする.Wolfram言語から文字列等をファイルに落とすときも,特に指定がなければ,これら2つの書式のどちらかが使われる.
特殊文字と記号によっては,Wolfram言語内部で使う専用文字コード規格ではなく,従来規格の文字コードで指定した方が手っ取り早いときもあるだろう.つまり,英語名や専用16進数文字コードを使うのではなく,オペレーティングシステムの環境およびフォント別に定義してある外部文字コード規格を使うということである.
| $CharacterEncoding=None | すべての特殊文字に対して印刷可能なASCII名を使う |
| $CharacterEncoding="name" | name により指定された外部文字コード規格を使う |
| $SystemCharacterEncoding | 使っているコンピュータシステムのデフォルトの外部文字コード |
ノートブック用フロントエンドを使っている場合,使っているフォントにより自動的に適切な文字規格が選択されるのでユーザが設定変更する必要はない.テキスト用フロントエンドを使っている場合やファイル処理またはパイプ処理をしている場合,自動設定は行われないので必要ならば$CharacterEncodingを使い設定を手動で変更する.
$CharacterEncodingの機能で適当な規格を指定しておけば,文字コードに依存するテキストエディタやオペレーティングシステムの直接生成する生のテキスト等が直接処理できるようになる.
Wolfram言語専用の文字コード規格で特殊文字と記号を記述してあれば,オペレーティングシステム環境に関係なくWolfram言語で読む限りは確実に文字と記号を再現できる.外部規格を使う場合はこの限りではない.
| "PrintableASCII" | 印字可能なASCII文字 |
| "ASCII" | 制御コードも含むASCII |
| "ISOLatin1" | 西ヨーロッパ言語の文字 |
| "ISOLatin2" | 中東部ヨーロッパ言語の文字 |
| "ISOLatin3" | 第1ヨーロッパ言語文字補助セット(カタロニア語,トルコ語等) |
| "ISOLatin4" | 第2ヨーロッパ言語文字補助セット(エストニア語,グリーンランド語等) |
| "ISOLatinCyrillic" | 英語・キリル文字セット |
| "AdobeStandard" | PostScriptフォント用Adobe文字コード規格 |
| "MacintoshRoman" | Macintoshローマンフォント用文字コード規格 |
| "WindowsANSI" | Windowsフォント用文字コード規格 |
| "Symbol" | 記号フォント用文字コード規格 |
| "ZapfDingbats" | Zapf dingbats文字コード規格 |
| "ShiftJIS" | シフトJIS日本語文字コード規格(8,16ビットコード混在) |
| "EUC" | 拡張Unix日本語文字コード規格(8,16ビットコード混在) |
| "UTF‐8" | Unicode規格(UTF‐8形式) |
どの外部文字コード規格が適切かといった指定はオペレーティングシステムの環境設定や使用言語に応じて Wolframシステム内部で設定済みである.Wolframシステムノートブックインターフェースとコンピュータ上のユーザインターフェース環境との間で文字をコピーするには,通常その環境にネイティブの文字コード規格が使われる.ネイティブのコード規格に含まれていないWolfram言語文字はWolfram言語専用規格の英語名もしくは16進数コードで記述される.
Wolfram言語カーネルは,テキストファイルを書いたり読んだりするときに,指定されたどのような文字コード規格も使うことができる.デフォルトでは,PutとPutAppendにより,Wolfram言語ファイルを1つのシステムから別のシステムへと確実に移植するためのASCII表現が生成される.
Wolfram言語のサポートする外部文字コード規格には1バイト(8ビット長)と2バイト(16ビット長)がある."ISOLatin1"等の規格は1バイト文字だけで構成されるが,"ShiftJIS"は2バイト文字が主体になっている.
Wolfram言語のサポートする外部文字コード規格において,そのほとんどはASCII規格を取り込んだ形で定義されている.したがって,それらの外部規格を使う限りは,文字列∖[と∖:を使った特殊文字の指定が有効である.
ASCII規格に準拠していない文字コード規格には,例えば,"Symbol"で指定される記号文字コード規格がある.この文字コード規格では,ASCIIアルファベットのaはギリシャ文字 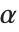 になり,bは
になり,bは  になる.
になる.
| ToCharacterCode["string"] | 文字列の各文字をWolfram言語標準規格の文字コードで列挙する |
| ToCharacterCode["string","encoding"] | 文字列の各文字を指定外部規格の文字コードで列挙する |
| FromCharacterCode[{n1,n2,…}] | リスト入力した文字コードに対応する Mathematica 標準規格の文字を生成する |
| FromCharacterCode[{n1,n2,…},"encoding"] | |
リスト入力した文字コードに対応する外部規格の文字を生成する | |
Windowsの文字コードはどうであろうか.Windowsのローマン規格には∖[Pi]はマップされていないことが分かる:
Wolfram言語内部で使う文字規格はUnicodeに準拠している.ただ,外部とのやり取りでは,通常,ASCIIコードだけが使われる.特殊文字や記号も,∖[Name]と∖:nnnn の書式に基づいたASCII記述が使われる.また,"UTF-8"文字コードをあらかじめ指定しておけば,ファイルをUnicode準拠のテキスト(2バイト文字)として読み込ませることは可能である.