矩阵计算
本节教程将对 Wolfram 语言所提供的用于进行矩阵计算的函数进行评述. 关于这些函数的更多信息可以在 Golub 和 van Loan 或 Meyer 等作者撰写的标准数学教科书中找到. 本节教程所介绍的运算,除了范数的计算也可扩展至标量和向量外,其它的计算都是矩阵所特有的.
基本运算
本节回顾了一些基本概念和运算,它们将贯穿整节教程,用于讨论矩阵运算.
范数
一个数学对象的范数是关于该对象的长度、尺寸或程度的度量. 在 Wolfram 语言中,范数存在于标量、向量和矩阵中.
| Norm[num] | 一个数的范数 |
| Norm[vec] | 向量的2范数 |
| Norm[vec,p] | 向量的 p 范数 |
| Norm[mat] | 矩阵的2范数 |
| Norm[mat,p] | 矩阵的 p 范数 |
| Norm[mat,"Frobenius"] | 矩阵的 Frobenius 范数 |
向量范数
在向量空间上,范数允许度量距离. 这使得对诸如邻域、近似接近度以及拟合优度等常见概念的定义成为可能. 向量范数是一个满足下述关系的函数 ![]() .
.
通常该函数用符号![]() 表示. 下标用于区分不同的范数,其中 p 范数尤其重要. 对于
表示. 下标用于区分不同的范数,其中 p 范数尤其重要. 对于 ![]() ,p 范数的定义如下.
,p 范数的定义如下.
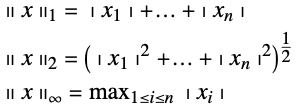
矩阵范数
矩阵范数用于给出矩阵空间上距离的度量. 如果要对矩阵之间的距离进行量化,例如一个矩阵接近于降秩矩阵,矩阵范数的存在是很有必要的.
矩阵范数也采用向量范数的双竖线表示符号. 最常见的矩阵范数之一是 Frobenius 范数(也称作 Euclidean 范数).
另一个常见范数是 p 范数. 它们以向量 p 范数的形式进行定义如下.
零空间
与每个矩阵相关的基本子空间之一是零空间. 在一个矩阵的零空间的向量通过矩阵映射到零.
| NullSpace[m] | 一列基本向量,其线性组合满足 |
矩阵的秩
| MatrixRank[mat] | 给出矩阵 mat 的秩 |
对于一个 m×n 矩阵 A,下述关系成立:Length[NullSpace[A]]+ MatrixRank[A]n,且Length[NullSpace[AT]]+ MatrixRank[AT]m. 由此得到,当且仅当矩阵的秩等于 n 时零空间为空,并且当且仅当A 的秩等于 m 时 A 的转置矩阵的零空间为空.
如果秩与列数相等,则被称为满列秩;如果秩与行数相等,则被称为满行秩. 列梯形形式可以帮助理解矩阵的秩的概念.
简化行阶梯形式
将一个矩阵化简成行阶梯形式可以通过一组行变换实现,从左上角的元素所在的首元位置开始,将首元所在行以下的各行减去首元行的倍数,使得同一列中首元下方的所有元素为零. 然后选取位于下一行和下一列的元素作为下一个首元. 如果这一首元为零,并且其下方同一列中有非零元素,则进行行交换,并重复上面的步骤,直到进行到最后一行或最后一列为止.
如果对于一个矩阵的任意零行(行的各元素全部为零),其后的各行都是零行;并且如果行 ![]() 的第一个非零元素位于列
的第一个非零元素位于列 ![]() ,则第1至
,则第1至 ![]() 列位于
列位于 ![]() 下方的元素都为零,则该矩阵为行阶梯形式. 阶梯形矩阵并不唯一,但它的形式是唯一的,即各个首元的位置相同. 这也提供了一种用非零行个数确定矩阵的秩的方法.
下方的元素都为零,则该矩阵为行阶梯形式. 阶梯形矩阵并不唯一,但它的形式是唯一的,即各个首元的位置相同. 这也提供了一种用非零行个数确定矩阵的秩的方法.
如果一个行阶梯形矩阵,每个首元是1,并且每个首元所在的列的其它元素都为零,则称该矩阵是简化阶梯形矩阵.得到这种形式的步骤与得到行阶梯形矩阵的步骤类似,同样经过几步使首元简化成1(通过除法),将与首元所在列中首元上方的元素化简为零(通过减去当前首元行的倍数). 矩阵的简化阶梯形式是唯一的.
简化行阶梯形式以及行阶梯形式提供了一种用非零行个数确定矩阵的秩的方法. 在 Wolfram 语言中,矩阵的简化行阶梯形式可以通过函数 RowReduce 计算得到.
| RowReduce[mat] | 给出矩阵 mat 的简化行阶梯形式 |
矩阵的逆
其中 ![]() 为单位矩阵. 在 Wolfram 语言中,矩阵的逆可以通过函数 Inverse 得到.
为单位矩阵. 在 Wolfram 语言中,矩阵的逆可以通过函数 Inverse 得到.
| Inverse[mat] | 给出一个矩阵 mat 的逆 |
然而,直接求解该矩阵方程往往更简单. 这些技巧将在"求解线性方程组"一节中讨论.
伪逆矩阵
对于奇异矩阵或非方阵矩阵,找到一个使 ![]() 最小化的近似逆仍然是可能的. 当使用2范数时,这将得到被称作伪逆矩阵的最小二乘解.
最小化的近似逆仍然是可能的. 当使用2范数时,这将得到被称作伪逆矩阵的最小二乘解.
| PseudoInverse[mat] | 给出矩阵 mat 的伪逆矩阵 |
通过伪逆得到的解是最小二乘解. 更多细节请见"最小二乘解"的讨论.
行列式
它在 Wolfram 语言中可以通过函数 Det 计算得到.
子式
求解线性方程组
矩阵的重要用途之一是表示和求解线性方程组. 这一节讨论如何在 Wolfram 语言中求解线性方程组. 它充分利用为实现这一目的所提供的主要函数——LinearSolve.
求解一个线性方程组涉及到求解一个矩阵方程 ![]() . 由于
. 由于 ![]() 是一个
是一个 ![]() ×
×![]() 矩阵,它代表的是含有
矩阵,它代表的是含有 ![]() 个未知数的
个未知数的 ![]() 个线性方程的集合.
个线性方程的集合.
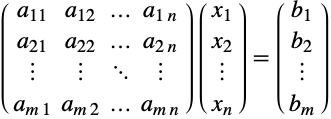
当 ![]() 时,方程组被称为正定.
时,方程组被称为正定. ![]() 意味着方程数大于未知数的个数,这时的方程组为超定方程组. 如果
意味着方程数大于未知数的个数,这时的方程组为超定方程组. 如果 ![]() ,则表示方程数小于未知数的个数,这时的方程组为欠定方程组.
,则表示方程数小于未知数的个数,这时的方程组为欠定方程组.
square | m=n;解可以存在或不存在 |
overdetermined | m>n;解可以存在或不存在 |
underdetermined | m<n;无解或有无穷解 |
nonsingular | 独立方程的个数等于变量的个数且行列式非零;存在唯一解 |
consistent | 至少存在一个解 |
inconsistent | 无解 |
需要注意的是,即使能够通过 ![]() 计算逆矩阵继而求解矩阵方程,这种方法并不值得推荐. 用户应该使用一种专门设计的函数来直接求解线性方程组,在 Wolfram 语言中,这由 LinearSolve 所提供.
计算逆矩阵继而求解矩阵方程,这种方法并不值得推荐. 用户应该使用一种专门设计的函数来直接求解线性方程组,在 Wolfram 语言中,这由 LinearSolve 所提供.
| LinearSolve[m,b] | 求解矩阵方程 m.x==b 得到的向量 x |
| LinearSolve[m] | 可重复应用在不同 b 的一个函数 |
通过 LinearSolve 求解线性方程组.
如果找不到解,则方程组不一致. 这时,找到最适合的解仍可能是有用的. 这通常用最小二乘技术完成,这将在"最小二乘解" 中探讨.
LinearSolve 的选项.
LinearSolve 有三种选项允许用户进行更多控制. 选项 Modulus 和 ZeroTest 用于符号技术,在"符号和精确矩阵"一节中讨论. 如果已知某些方法适用于某个具体问题,选项 Method 允许用户从这些方法中做出选择. 默认设置 Automatic 表示 LinearSolve 根据输入选择方法.
奇异矩阵
对于无法找到解的情形,找到一个最适合的解仍是有可能的. 关于最适合的解的一种重要类别涉及到最小二乘解,这将在"最小二乘解"中讨论.
齐次方程
如果矩阵是奇异的,这个方程有一个非零解. 可以通过计算行列式来测试一个矩阵是否奇异.
准确性的估计和计算
对线性方程组解的准确性进行量化的一个重要途径是计算条件数 ![]() . 对于一个适当的范数选取,它的定义如下.
. 对于一个适当的范数选取,它的定义如下.
对于矩阵方程 ![]() ,可以证明
,可以证明 ![]() 的相对误差是
的相对误差是 ![]() 乘以
乘以 ![]() 和
和 ![]() 的相对误差. 因此,条件数使解的准确性得到量化. 如果一个矩阵的条件数很大,该矩阵被称作“病态的”. 从病态矩阵中是不能期望得到一个好的解的. 对于某些过于病态的方程组,得到任何解都是不可能的.
的相对误差. 因此,条件数使解的准确性得到量化. 如果一个矩阵的条件数很大,该矩阵被称作“病态的”. 从病态矩阵中是不能期望得到一个好的解的. 对于某些过于病态的方程组,得到任何解都是不可能的.
在 Wolfram 语言中,条件数的近似值可以通过函数 LinearAlgebra`MatrixConditionNumber 计算得到.
| LinearAlgebra`MatrixConditionNumber[mat] | |
| 近似数值矩阵的无穷范数近似条件数 | |
| LinearAlgebra`MatrixConditionNumber[mat,Norm->p] | |
| 一个矩阵的 p‐范数近似条件数,其中 p 的值可以为 1、2 或 | |
符号和精确矩阵
LinearSolve 适用于可在 Wolfram 语言中表示的各种不同类型的矩阵. 有关于此的更多细节将在"矩阵类型"中介绍.
为了简化中间表达式,ZeroTest 选项可能派上用场.
有许多专用于符号和精确计算的方法:CofactorExpansion,DivisionFreeRowReduction 以及 OneStepRowReduction. 这些将在"符号方法"一节中讨论.
行变换
因式分解的保存
LinearSolve 的单参数形式与双参数形式的运行方式完全等价. 例如,它应用于输入矩阵的同一范围,返回符号式、精确或稀疏矩阵输入的预期结果. 它所接受的选项也相同.
方法
LinearSolve 提供了不同的技术来求解针对与具体问题的矩阵方程. 用户可以使用选项 Method 对这些技术做出选择. 在这种方式下,提供了一个统一的接口,通向 Wolfram 语言所提供的用于求解矩阵方程的全部功能.
选项 Method 的默认设置是 Automatic,这表示该方程组将对所用的方法进行自动选择. 对于 LinearSolve,如果输入矩阵是数值型稠密矩阵,则将采用一种使用 LAPACK 的方法的例行程序;如果输入矩阵是数值型稀疏矩阵,则采用直接多波前法求解程序. 如果矩阵是符号型的,则使用专门的符号例行程序.
LAPACK
LAPACK 是求解密集数值矩阵的默认方法. 当矩阵为方阵且非奇异时,对于实数矩阵,例行程序是 dgesv、dlange 以及 dgecon,对于复数矩阵,例行程序是 zgesv、zlange 以及 zgecon. 当矩阵非方阵或奇异时,对于实数矩阵将使用 dgelss,对于复数矩阵,将使用 zgelss. 关于 LAPACK 的更多信息请见参考文献.
如果输入矩阵使用的是任意精度数值,则将采纳扩展至任意精度计算的 LAPACK算法.
多波前法
当输入矩阵为稀疏矩阵时,多波前法是一种默认使用的直接求解程序;它的选定也可以通过指定一个方法选项来实现.
如果多波前法所涉及到的输入矩阵是稠密型的,它将被转化成稀疏矩阵.
多波前法的执行使用的是"UMFPACK"程序库.
Krylov
Krylov 法是一种迭代求解程序,适用于大型稀疏线性方程组,诸如出现在偏微分方程的数值求解的方程组等. Wolfram 语言执行两种 Krylov 方法:共轭梯度(适用于正定对称矩阵)和 BiCGSTAB(适用于非对称方程组). 使用适当的子选项对所用的方法以及一些其它参数进行设定是可能的.
选项名称 | 默认值 | |
| MaxIterations | Automatic | 迭代的最大数量 |
| Method | BiCGSTAB | 求解所用的方法 |
| Preconditioner | None | 预调节器 |
| ResidualNormFunction | Automatic | 要最小化的范数 |
| Tolerance | Automatic | 使迭代终止所用的公差(tolerance) |
BiCGSTAB 作为 Krylov 的默认方法,代价较高但适用性广. 共轭梯度方法适用于正定对称矩阵,总是收敛到一个解(尽管收敛可能会很慢). 如果矩阵不是对称矩阵正定,共轭梯度可能不能收敛到一个解.
当前只内置了 ILU 预调节器. 但用户仍可以通过定义一个应用于输入矩阵的函数来自定义预调节器. 下面是一个关于求解对角矩阵的例子.
一般来说,一个问题不会如此构造,使之能够受益于这样一个简单的预调节器. 但是,这个例子的用意在于它显示了如何创建和使用自定义的预调节器.
如果 Krylov 方法的输入矩阵是密集的,仍能得到这个结果,原因在于该方法基于的是矩阵/向量乘法.
Krylov 方法可用于求解对于直接求解程序来说过大的方程组. 然而,这不是通用的一般求解程序,主要适合于求解有某种形式的对角优势的问题.
Cholesky

对于密集矩阵,Cholesky 方法使用的是 LAPACK 函数,具体来说,对于实数矩阵使用的是 dpotrf 和 dpotrs 等,对于复数矩阵使用的是 zpotrf 和 zpotrs. 对于稀疏矩阵,Cholesky 方法使用"TAUCS"程序库.
符号方法
最小二乘解
在这些情形下,找到一个使 ![]() 最小的最合适的解是可能的. p 的一个非常通常选择是2;这样生成的是一个最小二乘解. 这是常用的,原因在于函数
最小的最合适的解是可能的. p 的一个非常通常选择是2;这样生成的是一个最小二乘解. 这是常用的,原因在于函数 ![]() 关于
关于 ![]() 可微,并且在正交变换下2范数得以保存.
可微,并且在正交变换下2范数得以保存.
如果 ![]() 的秩为
的秩为 ![]() (即具有满列秩),可以表明(Golub 和 van Loan)最小二乘问题有一个能够求解方程组的唯一解.
(即具有满列秩),可以表明(Golub 和 van Loan)最小二乘问题有一个能够求解方程组的唯一解.
这些被称作正规方程. 尽管可以直接求解这些正规方程得到最小二乘解,这种做法并不推荐使用,因为如果矩阵 ![]() 是病态的,则乘积
是病态的,则乘积 ![]() 将更病态. 对于满秩矩阵,得到最小二乘解的方法将在"范例:满秩最小二乘解"中探索.
将更病态. 对于满秩矩阵,得到最小二乘解的方法将在"范例:满秩最小二乘解"中探索.
值得注意的是,使其它范数如1和 ![]() 等最小化的最适当解同样可能. 适合于特定类型矩阵或使其它范数最小化的超定方程组的求解有许多方式,它们将在"1和无穷范数的最小化"一节中给出.
等最小化的最适当解同样可能. 适合于特定类型矩阵或使其它范数最小化的超定方程组的求解有许多方式,它们将在"1和无穷范数的最小化"一节中给出.
找到超定方程组的最小二乘解的一般方式是使用奇异值分解来形成矩阵的伪逆矩阵. 在 Wolfram 语言中,这通过 PseudoInverse 计算得到. 该技术对于秩亏的输入矩阵同样有效. 下面是该技术的要点.
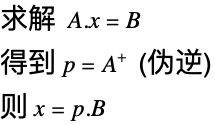
数据拟和
科学测量常常导致有序数据对集合 ![]() . 为了预测那些未经测量的点所对应的值,拟和一条通过数据点的曲线是很常见的. 如果曲线是一条直线,则致力于找到未知的系数
. 为了预测那些未经测量的点所对应的值,拟和一条通过数据点的曲线是很常见的. 如果曲线是一条直线,则致力于找到未知的系数 ![]() 和
和 ![]() ,使得
,使得
对于所有的数据对成立. 这可以写成如下所示的矩阵形式,并能立刻被识别为等价于求解一个超定线性方程组.
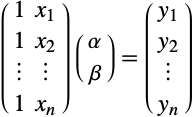
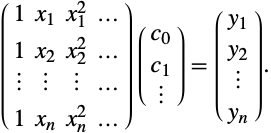
这种情况时,左端的矩阵是一个 Vandermonde 矩阵. 事实上,可以使用任何未知系数为线性的函数.
函数 FindFit 非常通用,它也能非线性参数的数据进行函数拟和.
特征系统的计算
特征值问题的解是矩阵计算的主要领域之一. 它在物理学、化学和工程上有许多应用. 对于一个 ![]() ×
×![]() 矩阵
矩阵 ![]() ,特征值是它的特征多项式
,特征值是它的特征多项式 ![]() 的
的 ![]() 个根. 根的集合,
个根. 根的集合,![]() 被称作矩阵的谱. 对于每个特征值
被称作矩阵的谱. 对于每个特征值 ![]() ,满足
,满足
的向量 ![]() 被称作特征向量. 特征向量的矩阵
被称作特征向量. 特征向量的矩阵 ![]() ,如果存在且非奇异,则可用作相似变换形成一个对角矩阵,其中特征值作为对角元素. 特征值的许多重要应用涉及到这种方式下矩阵的对角化.
,如果存在且非奇异,则可用作相似变换形成一个对角矩阵,其中特征值作为对角元素. 特征值的许多重要应用涉及到这种方式下矩阵的对角化.
| Eigenvalues[m] | m 的一列特征值 |
| Eigenvectors[m] | m 的一列特征向量 |
| Eigensystem[m] | 一个形如{特征值,特征向量}的列表 |
| CharacteristicPolynomial[m,x] | m 的特征多项式 |
特征值的某些应用不要求计算所有的特征值. Wolfram 语言提供了一种仅获得一部分特征值的机制.
| Eigenvalues[m,k] | m 的最大的 k 个特征值 |
| Eigenvectors[m,k] | m 的对应的特征向量 |
| Eigenvalues[m,-k] | m 的最小的 k 个特征值 |
| Eigenvectors[m,-k] | m 的对应的特征向量 |
选项名称 | 默认值 | |
| Cubics | False | 是否返回 3×3 矩阵的根式 |
| Method | Automatic | 求解所用的方法 |
| Quartics | False | 是否返回 4×4 矩阵的根式 |
| ZeroTest | (#0&) | 用于零值测试符号法的函数 |
用于 Eigensystem 的选项.
Eigensystem 有四个允许用户获得更多控制的选项. 选项 Cubics, Quartics 和 ZeroTest 用于符号技术,在"符号和精确矩阵"一节中讨论. 选项 Method 允许知识丰富的用户来选择专门适合他们的问题的方法;Automatic 的默认设置意味着 Eigensystem 选出了一个普遍使用的方法.
特征系统的性质
这一节将介绍特征系统计算的一些性质. 应该记住,由于一个 ![]() ×
×![]() 矩阵的特征值可以与一个
矩阵的特征值可以与一个 ![]() 次多项式的根紧密相关,特征值总为
次多项式的根紧密相关,特征值总为 ![]() 个.
个.
矩阵对角化
符号和精确矩阵
正如在 Wolfram 语言中所贯有的,如果计算的是一个符号或精确矩阵, Wolfram 语言将利用符号计算代数技术并返回一个符号或精确结果.
广义特征值
对于 ![]() ×
×![]() 矩阵
矩阵 ![]() ,其广义特征值为特征多项式
,其广义特征值为特征多项式 ![]() 的
的 ![]() 个根. 对于每一个广义特征值
个根. 对于每一个广义特征值 ![]() ,满足
,满足
| Eigenvalues[{a,b}] | a 和 b 的广义特征值 |
| Eigenvectors[{a,b}] | a 和 b 的广义特征向量 |
| Eigensystem[{a,b}] | a 和 b 的的广义特征系统 |
方法
根据具体问题的不同,特征值计算将使用各种不同的技术. 用户可用通过选项 Method 对这些技术作出选择. 有一个通向 Wolfram 语言所有功能的统一的接口.
选项 Method 的默认设置是 Automatic. 按照 Wolfram 语言 的惯例,这表示系统将会对所用方法自动做出选择. 在计算特征值时,如果输入的是一个机器数值的 ![]() ×
×![]() 矩阵,并且所求特征值的个数小于
矩阵,并且所求特征值的个数小于 ![]() 的 20%,则使用一种 Arnoldi 方法. 否则,如果输入矩阵是数值型的,则使用一种使用 LAPACK 例行程序的方法. 如果矩阵为符号型,则使用专门的符号例行程序.
的 20%,则使用一种 Arnoldi 方法. 否则,如果输入矩阵是数值型的,则使用一种使用 LAPACK 例行程序的方法. 如果矩阵为符号型,则使用专门的符号例行程序.
LAPACK
LAPACK 是计算特征值和特征向量全体集合的默认方法. 对于非对称矩阵,dgeev 用于实数矩阵,zgeev 用于复数矩阵. 对于对称矩阵,dsyevr 用于实数矩阵,zheevr 用于复数矩阵. 对于广义特征值,例行程序 dggev 用于实数矩阵,zggev 用于复数矩阵. 关于 LAPACK 的更多信息请见参考文献部分.
如果输入矩阵使用的是任意精度数值,则选用扩展至任意精度计算的 LAPACK 算法.
Arnoldi
Arnoldi 方法是一种迭代法,用于计算有限个特征值. 执行 Arnoldi 方法使用的是 "ARPACK" 程序库. 能够通过这种技术来求解的最一般的问题是选择计算下式的几个特征值:
因为它是一种迭代技术,仅能得到几个特征值,它常用于稀疏矩阵. 该技术的功能之一是能够应用一个偏移 ![]() ,并对给定的特征向量
,并对给定的特征向量 ![]() 和特征值
和特征值 ![]() (
(![]() )求解.
)求解.
选项名称 | 默认值 | |
| BasisSize | Automatic | Arnoldi 基的大小 |
| Criteria | Magnitude | 求解所用的方法 |
| MaxIterations | Automatic | 迭代最大次数 |
| Shift | None | 一个 Arnoldi 偏移 |
| StartingVector | Automatic | 所用的初始向量 |
| Tolerance | Automatic | 使迭代终止所用的公差 |

对于许多出现在实际计算中的大型稀疏方程组,Arnoldi 算法能够很快地收敛.
符号方法
矩阵分解
这一节将讨论用于矩阵的一些标准技术. 这些技术常用作求解矩阵问题的构件. 分解属于因式分解、正交变换和相似变换的范畴.
LU 分解
矩阵的 LU 分解在求解矩阵方程时常用作高斯消去过程的一部分. 在 Wolfram 语言中,没有必要使用 LU 分解来求解矩阵方程,原因在于,正如在"求解线性方程组"一节中所讨论的,函数 LinearSolve 可以为您完成这个任务. 注意的是,如果您想要保存矩阵的分解以便用于求解具有相同左端的问题,可以像"因式分解的保存"一节中所示范的那样,使用 LinearSolve 的单参数形式.
非奇异方阵 ![]() 的部分主元消元法中的 LU 分解要计算独特的矩阵
的部分主元消元法中的 LU 分解要计算独特的矩阵 ![]() 、
、![]() 以及
以及 ![]() ,使得
,使得
其中 ![]() 是对角线元素均为1的下三角形式,
是对角线元素均为1的下三角形式,![]() 是上三角形式,
是上三角形式,![]() 是置换矩阵. 一旦得到,可以通过找到下述等价方程组的解将其用于求解矩阵方程.
是置换矩阵. 一旦得到,可以通过找到下述等价方程组的解将其用于求解矩阵方程.
尽管在 Wolfram 语言中求解矩阵方程不需要使用 LU 分解,Wolfram 语言还是提供了函数 LUDecomposition 来计算 LU 分解.
| LUDecomposition[m] | 部分主元消元的 LU 分解 |
LUDecomposition 返回一个三元素的列表. 第一个元素是上下三角矩阵的结合,第二个元素是一个向量,用于指定主元消元所用的行(一个等价于置换矩阵的置换向量),第三个元素是条件数的估计值.
LU 分解的特征之一是下矩阵和上矩阵被存在同一个矩阵中. 单独的 ![]() 和
和 ![]() 因子可以通过如下方法获得. 注意观察它们如何使用一种向量化的运算来完成稀疏矩阵的逐个元素的相乘. 这是的该过程更加有效;这些技术在"编程的效率"一节中进一步讨论.
因子可以通过如下方法获得. 注意观察它们如何使用一种向量化的运算来完成稀疏矩阵的逐个元素的相乘. 这是的该过程更加有效;这些技术在"编程的效率"一节中进一步讨论.
Cholesky 分解
对称正定矩阵 ![]() 的 Cholesky 分解是一种因式分解,将其分解成一个唯一的上三角矩阵
的 Cholesky 分解是一种因式分解,将其分解成一个唯一的上三角矩阵 ![]() ,使得
,使得
这种分解有很多用途,其中之一是,由于这是一个三角分解,它可用于对称正定矩阵的方程组. (三角因式分解如何用于求解矩阵方程在"LU 分解"一节中有说明.)如果已知一个矩阵是这种形式, Cholesky 分解将优于 LU 分解,因为 Cholesky 因式分解的计算较快. 如果想要使用 Cholesky 分解求解矩阵方程,可以使用 Cholesky 方法直接从LinearSolve 中完成,这在前面一节中介绍过.
Cholesky 因式分解可以通过函数 CholeskyDecomposition 计算.
| CholeskyDecomposition[m] | Cholesky 分解 |
测试一个矩阵是否是正定的方式之一是看 Cholesky 分解是否存在.
Cholesky 和 LU 因式分解
正交化
正交化从一个任意基生成一个正交基. 正交基指的是一个基 ![]() ,满足
,满足
在 Wolfram 语言中,一个向量集合可以通过函数 Orthogonalize 正交化.
| Orthogonalize[{v1,v2,…}] | 由给定的一列实数向量生成一个正交集 |
默认时计算的是 Gram–Schmidt 正交化,但也能计算许多其它的正交化.
QR 分解
一个矩形矩阵 ![]() 线性无关列的 QR 分解要计算矩阵
线性无关列的 QR 分解要计算矩阵 ![]() 和
和 ![]() ,使得
,使得
其中 ![]() 中各列形成
中各列形成 ![]() 中各列的一个正交基,
中各列的一个正交基,![]() 是一个上三角矩阵. 它可以通过函数 QRDecomposition 计算.
是一个上三角矩阵. 它可以通过函数 QRDecomposition 计算.
| QRDecomposition[m] | 一个矩阵的 QR 分解 |
求解方程组
对于非奇异方阵 ![]() ,QR 分解可用于求解矩阵方程
,QR 分解可用于求解矩阵方程 ![]() ,这一点与 LU 分解的情形相同. 然而,如果矩阵是矩形的, QR 分解同样可用于求解矩阵方程.
,这一点与 LU 分解的情形相同. 然而,如果矩阵是矩形的, QR 分解同样可用于求解矩阵方程.
QR 分解的一个特别应用是通过求解下述正规方程组,找寻超定方程组的最小二乘解
由于 ![]() 为三角矩阵,这个方程组的求解非常简单;在 "范例:最小二乘 QR"中给出了执行这个操作所用的简单程序代码.
为三角矩阵,这个方程组的求解非常简单;在 "范例:最小二乘 QR"中给出了执行这个操作所用的简单程序代码.
奇异值分解
矩形矩阵 ![]() 的奇异值分解涉及到正交矩阵
的奇异值分解涉及到正交矩阵 ![]() 和
和 ![]() 与一个对角矩阵
与一个对角矩阵 ![]() 的计算,使得下式成立
的计算,使得下式成立
矩阵 ![]() 的对角元素被称作
的对角元素被称作 ![]() 的奇异值. 在 Wolfram 语言中,函数 SingularValueList 计算奇异值,函数 SingularValueDecomposition 计算完全奇异值分解.
的奇异值. 在 Wolfram 语言中,函数 SingularValueList 计算奇异值,函数 SingularValueDecomposition 计算完全奇异值分解.
| SingularValueList[m] | m 的非零奇异值的一个列表 |
| SingularValueDecomposition[m] | m 的奇异值分解 |
奇异值分解有许多应用. 矩阵的奇异值提供 ![]() 所表示的线性变换的信息. 例如,
所表示的线性变换的信息. 例如,![]() 在一个单位球面上的行为生成一个椭圆体,其半轴由奇异值给定. 非零奇异值的个数等于矩阵的秩,因此奇异值可用于计算矩阵的秩. 奇异值可用于计算矩阵的2范数,与零奇异值对应的矩阵
在一个单位球面上的行为生成一个椭圆体,其半轴由奇异值给定. 非零奇异值的个数等于矩阵的秩,因此奇异值可用于计算矩阵的秩. 奇异值可用于计算矩阵的2范数,与零奇异值对应的矩阵 ![]() 的各列是矩阵的零空间.
的各列是矩阵的零空间.
奇异值的一些应用不要求计算所有的奇异值. Wolfram 语言提供了一种机制来获得部分奇异值.
| SingularValueList[m,k] | m 的最大的 k 个奇异值 |
| SingularValueDecomposition[m,k] | m 对应的奇异值分解 |
| SingularValueList[m,-k] | m 的最小的 k 个奇异值 |
| SingularValueDecomposition[m,-k] | m 对应的奇异值分解 |
广义奇异值
对于一个 ![]() ×
×![]() 矩阵
矩阵 ![]() 和一个
和一个 ![]() ×
×![]() 矩阵
矩阵 ![]() ,广义奇异值由因式分解对
,广义奇异值由因式分解对
给出,其中 ![]() 为
为 ![]() ×
×![]() ,
,![]() 为
为 ![]() ×
×![]() ,
,![]() 为
为 ![]() ×
×![]() ;
;![]() 和
和 ![]() 是正交矩阵,
是正交矩阵,![]() 是可逆矩阵.
是可逆矩阵.
| SingularValueList[{a,b}] | a 和 b 的广义奇异值 |
| SingularValueDecomposition[{a,b}] | a 和 b 的广义奇异值分解 |
选项
函数 SingularValueList 和 SingularValueDecomposition 都可以使用一个 Tolerance 选项.
该选项控制的是将奇异值当作零处理的公差范围. 默认时,小于最大奇异值 tol 倍的值将被去除. 对于机器数值矩阵,tol 等于 100×$MachineEpsilon. 对于任意精度矩阵,它等于 ![]() ,其中
,其中 ![]() 是该矩阵的精确度.
是该矩阵的精确度.
Schur 分解
方阵 ![]() 的 Schur 分解涉及到找寻一个酉矩阵,使之用于
的 Schur 分解涉及到找寻一个酉矩阵,使之用于 ![]() 的相似变换,从而形成一个上三角矩阵块
的相似变换,从而形成一个上三角矩阵块 ![]() ,其中对角线上是1×1 和 2×2 矩阵块(该 2×2 矩阵块对应于实数矩阵
,其中对角线上是1×1 和 2×2 矩阵块(该 2×2 矩阵块对应于实数矩阵 ![]() 的特征值的复数共轭对). 这种形式的上三角矩阵块可以被称作上准三角.
的特征值的复数共轭对). 这种形式的上三角矩阵块可以被称作上准三角.
Schur 分解始终存在,因此 ![]() 的相似变换也始终存在. 这一点与矩阵的对角化中所用的特征系统相似变换冲突,后者并不始终存在.
的相似变换也始终存在. 这一点与矩阵的对角化中所用的特征系统相似变换冲突,后者并不始终存在.
| SchurDecomposition[m] | 矩阵的 Schur 分解 |
广义 Schur 分解
| SchurDecomposition[{a,b}] | a 和 b 的广义 Schur 分解 |
对于实数输入,通过选项 RealBlockForm 可以获得一个复数结果和一个上三角结果.
选项
SchurDecomposition 有两个选项可取.
用于 SchurDecomposition 的选项.
选项 Pivoting 可允许旋转和缩放从而改善结果的质量. 如果设置是 True,即允许旋转和缩放,返回一个矩阵 ![]() 来代表对
来代表对 ![]() 所作的改变. 对于这个新矩阵,Schur 分解的定义可以从下式看出.
所作的改变. 对于这个新矩阵,Schur 分解的定义可以从下式看出.
Jordan 分解
方阵 ![]() 的 Jordan 分解需要找寻非奇异矩阵
的 Jordan 分解需要找寻非奇异矩阵 ![]() ,用于
,用于 ![]() 的相似变换以生成矩阵
的相似变换以生成矩阵 ![]() ,矩阵
,矩阵 ![]() 被称作 Jordan 形式,具有特别简单的三角结构.
被称作 Jordan 形式,具有特别简单的三角结构.
Jordan 分解总是存在,但难以通过浮点算术计算. 然而,精确算术计算能够避免这些问题.
| JordanDecomposition[m] | 矩阵的 Jordan 分解 |
矩阵函数
矩阵函数的计算是在许多领域(如控制理论)应用时所面临的一个一般问题. 方阵 ![]() 的函数
的函数 ![]() 不同于函数在矩阵每个元素上的应用. 显然,面向元素的应用与函数在一个比例上的应用相比,所保持的性质将不一致.
不同于函数在矩阵每个元素上的应用. 显然,面向元素的应用与函数在一个比例上的应用相比,所保持的性质将不一致.
定义矩阵函数的方式有很多种;一种有用的方式是考察一个级数展开. 对于指数函数,它的工作方式如下.
计算这个级数的一种途径涉及到 ![]() 的对角化,使得
的对角化,使得 ![]() 和
和 ![]() 成立. 因此,
成立. 因此,![]() 次幂可以按下式计算.
次幂可以按下式计算.
这个技术可以推广到 ![]() 的特征值的函数
的特征值的函数 ![]() . 注意尽管这是定义矩阵函数的一种方式,它并没有提供一种好的计算方式.
. 注意尽管这是定义矩阵函数的一种方式,它并没有提供一种好的计算方式.
Wolfram 语言没有一个用于计算一般矩阵函数的函数,但有一些特别函数.
| MatrixPower[m,n] | n 次矩阵幂 |
| MatrixExp[m] | 矩阵指数 |
| m1.m2 | 矩阵乘法 |
| Inverse[m] | 逆矩阵 |
通过求解微分方程计算矩阵的参数化函数的一种技术在"范例:带有 NDSolve 的矩阵函数"给出.