DimensionReduction
DimensionReduction[{example1,example2,…}]
exampleiで定義される空間からより低い次元の近似多様体に投影するDimensionReducerFunction[…]を生成する.
DimensionReduction[vecs,n]
n 次元近似多様体のためのDimensionReducerFunction[…]を生成する.
DimensionReduction[vecs,n,props]
次元削減の指定された特性を生成する.
詳細とオプション




- DimensionReductionは,数値,テキスト,サウンド,画像,それらの組合せを含む,さまざまなデータタイプに使うことができる.
- DimensionReduction[examples]は,次元削減を行うためにデータに適用可能なDimensionReducerFunction[…]を与える.
- 各 exampleiは,単一のデータ要素,データ要素のリスト,データ要素の連想,あるいはDatasetオブジェクトでよい.
- DimensionReduction[examples]は,対象の近似多様体に適した次元を自動的に選択する.
- DimensionReduction[examples]はDimensionReduction[examples,Automatic]に等しい.
- DimensionReduction[…,props]の props は単一の特性または特性のリストでよい.以下は使用可能なリストである.
-
"ReducerFunction" DimensionReducerFunction[…](デフォルト) "ReducedVectors" ベクトル exampleiの削減 "ReconstructedData" 削減と反転の後の examples の再構築 "ImputedData" データ補完された値で置換された,examples 内の欠落値 - 使用可能なオプション
-
FeatureExtractor Identity 学ぶべき対象から特徴をどのように抽出するか FeatureNames Automatic exampleiの要素に割り当てる名前 FeatureTypes Automatic exampleiの要素について仮定する特徴タイプ Method Automatic どの削減アルゴリズムを使用するか PerformanceGoal Automatic パフォーマンスのどの面について最適化するか RandomSeeding 1234 どのような擬似乱数生成器のシードを内部的に使うべきか TargetDevice "CPU" そこで訓練を行うターゲットデバイス - PerformanceGoalの可能な設定
-
"Memory" 削減器関数のストレージ要求を最少にする "Quality" 削減の質を最大にする "Speed" 削減速度を最大にする "TrainingSpeed" 削減器の生成に使う時間を最少にする - PerformanceGoal{goal1,goal2,…}は,goal1,goal2等を自動的に組み合せる.
- Methodの可能な設定
-
Automatic 自動選択されたメソッド "Autoencoder" 訓練可能な自動エンコーダを使う "Hadamard" アダマール(Hadamard)行列を使ってデータを投影 "Isomap" 等長写像 "LatentSemanticAnalysis" 潜在的意味分析メソッド "Linear" 最適な線形メソッドを自動的に選択する "LLE" 局所的線形埋込み "MultidimensionalScaling" 多次元スケーリング測度 "PrincipalComponentsAnalysis" 主成分分析法 "TSNE" 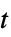 -分布に従う確率近傍埋込みアルゴリズム
-分布に従う確率近傍埋込みアルゴリズム"UMAP" 一様多様体の近似と投影 (Uniform Manifold Approximation and Projection) - RandomSeedingの可能な設定
-
Automatic 関数が呼び出されるたびに自動的にシードを変える Inherited 外部シードの乱数を使う seed 明示的な整数または文字列をシードとして使う - DimensionReduction[…,FeatureExtractor"Minimal"]は,内部的な前処理はできる限り簡単にすべきであることを示している.
- DimensionReduction[DimensionReducerFunction[…],FeatureExtractorfe]を使って既存の特徴抽出器の先頭にFeatureExtractorFunction[…] fe を加えることができる.
例題
すべて開くすべて閉じる例 (3)
スコープ (7)
再構築されたベクトルは,近似平面に投影されたもとのベクトルに相当する:
再構築されたベクトルは,もとのベクトルから直接得ることもできる:
次元削減器をDateObjectのリストについて訓練する:
新たなDateObjectの次元を削減する:
オプション (7)
FeatureTypes (1)
最初の特徴は数値と解釈される.FeatureTypesを使って最初の特徴の名目的解釈を強制する:
Method (3)
TargetDevice (1)
システムのデフォルトGPU上の完全に連結された"AutoEncoder"を使って削減器関数を訓練し,そのAbsoluteTimingを見る:
アプリケーション (5)
データ集合の可視化 (1)
ExampleDataから,フィッシャーの「アヤメ」のデータ集合をロードする:
頭部姿勢推定 (1)
画像の補完 (1)
ExampleDataからMNISTデータ集合をロードし,その画像を保存する:
画像を数値データに変換し,データ集合を訓練集合と検定集合に分割する:
ベクトルのいくつかの値をMissing[]で置換し,これを可視化する:
推薦者の系 (1)
ユーザによる映画の評価をSparseArray形で得る:
このデータ集合は,100人のユーザと10の映画からなる.評価範囲は1から5までで,Missing[]は未評価を意味する:
画像検索 (1)
削減された空間でNearestFunctionを生成する:
NearestFunctionを使ってデータ集合に最も近い画像を表示する関数を構築する:
テキスト
Wolfram Research (2015), DimensionReduction, Wolfram言語関数, https://reference.wolfram.com/language/ref/DimensionReduction.html (2020年に更新).
CMS
Wolfram Language. 2015. "DimensionReduction." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2020. https://reference.wolfram.com/language/ref/DimensionReduction.html.
APA
Wolfram Language. (2015). DimensionReduction. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/DimensionReduction.html