FindClusters
FindClusters[{e1,e2,…}]
eiを同種の要素ごとにクラスタにまとめる.
FindClusters[{e1v1,e2v2,…}]
各クラスタの eiに対応する viを返す.
FindClusters[data,n]
data を n 個のクラスタにまとめる.
詳細とオプション



- FindClusters はリストを類似要素の部分リスト(クラスタ)に分割する.クラスタの数と組成は,使用される入力データ,メソッド,評価基準に影響される.要素は,テキストと画像や日付と時間を含むさまざまなデータ型に属する可能性がある.
- クラスタリングは,顧客タイプ,動物の分類,ドキュメントのトピック等の要素のクラスを教師なしで求めるためによく使われる.教師ありの分類についてはClassifyを参照のこと.
- 入力例 eiのラベルは以下の形式で与えられる.
-
{e1,e2,…} ei それ自体を使う {e1v1,e2v2,…} 要素 eiとラベル viの間の規則のリスト {e1,e2,…}{v1,v2,…} すべての要素とすべてのラベルの間の規則 label1e1,label2e2,… Associationキーとしてのラベル - クラスタの数は以下の形で指定できる.
-
Automatic クラスタ数を自動的に求める n 厳密に n 個のクラスタを求める UpTo[n] 最高で n 個のクラスタを求める - 使用可能なオプション
-
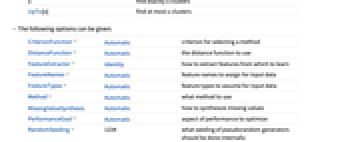
CriterionFunction Automatic メソッド選択の基準 DistanceFunction Automatic 使用する距離関数 FeatureExtractor Identity そこから学ぶ特徴をどのように抽出するか FeatureNames Automatic 入力データに割り当てる特徴名 FeatureTypes Automatic 入力データに仮定する特徴タイプ Method Automatic 使用するメソッド MissingValueSynthesis Automatic 欠測値の合成方法 PerformanceGoal Automatic パフォーマンスのどの面について最適化するか RandomSeeding 1234 どのような擬似乱数生成器のシードを内部的に使うべきか Weights Automatic 各例に与える重み - デフォルトで,FindClustersは,DistanceFunctionが指定されていなければ,自動的にデータを前処理する.
- DistanceFunctionの設定は,任意の距離関数,非類似度関数,または2つの値間の距離を定義する関数 f でよい.
- PerformanceGoalの可能な設定
-
Automatic 速度,確度,メモリ間の自動トレードオフ "Quality" 分類器の確度を最大にする "Speed" 分類器の速度を最大にする - Methodの可能な設定
-
Automatic メソッドを自動選択する "Agglomerate" 単一の結合クラスタ化アルゴリズム "DBSCAN" ノイズがあるアプリケーションの密度に基づいた空間クラスタ化 "GaussianMixture" ガウス混合アルゴリズムのバリエーション "JarvisPatrick" Jarvis–Patrickクラスタ化アルゴリズム "KMeans" k 平均クラスタ化アルゴリズム "KMedoids" メドイドの周りでのクラスタ化 "MeanShift" 平均シフトクラスタ化アルゴリズム "NeighborhoodContraction" データ点を高密度領域にシフトさせる "SpanningTree" 最小全域木に基づいたクラスタ化アルゴリズム "Spectral" スペクトルクラスタ化アルゴリズム - "KMeans"法と"KMedoids"法はクラスタ数が指定されているときにしか使用できない.
- "DBSCAN","GaussianMixture","JarvisPatrick","MeanShift","NeighborhoodContraction"の各メソッドは,クラスタ数がAutomaticのときにしか使用できない.
- 次のプロットは一般的なメソッドをトイデータ集合に適用した結果を示している.
- CriterionFunctionの可能な設定
-
"StandardDeviation" 二乗平均平方根標準偏差 "RSquared" R平方 "Dunn" Dunn指標 "CalinskiHarabasz" Calinski–Harabasz指標 "DaviesBouldin" Davies–Bouldin指標 "Silhouette" シルエットスコア Automatic 内部指標 - RandomSeedingの可能な設定
-
Automatic 関数が呼び出されるたびに自動的にシードを変える Inherited 外部シードの乱数を使う seed 明示的な整数または文字列をシードとして使う
例題
すべて開くすべて閉じるスコープ (6)
オプション (15)
CriterionFunction (1)
DistanceFunction (4)
CanberraDistanceを連続データの距離尺度として用いる:
デフォルトのSquaredEuclideanDistanceで求まったクラスタ:
DiceDissimilarityをブール値データの距離尺度として用いる:
MatchingDissimilarityをブールデータの距離測度として使う:
HammingDistanceを文字列データの距離尺度として用いる:
FeatureExtractor (1)
カスタムのFeatureExtractorを作って特徴を抽出する:
FeatureNames (1)
FeatureNamesを使って特徴に名前を付け,以降の指定でその名前を参照する:
FeatureTypes (1)
FeatureTypesを使って特徴の解釈を強制する:
Method (4)
PerformanceGoal (1)
RandomSeeding (1)
特性と関係 (2)
FindClustersはクラスタのリストを返すのに対し,ClusteringComponentsはクラスタ指標の配列を与える:
FindClustersはデータをグループ化するのに対し,Nearestは与えられた値に最も近い要素を返す:
テキスト
Wolfram Research (2007), FindClusters, Wolfram言語関数, https://reference.wolfram.com/language/ref/FindClusters.html (2020年に更新).
CMS
Wolfram Language. 2007. "FindClusters." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2020. https://reference.wolfram.com/language/ref/FindClusters.html.
APA
Wolfram Language. (2007). FindClusters. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/FindClusters.html