



FindClusters
FindClusters[{e1,e2,…}]
把 ei 分成相似元素组成的聚类.
FindClusters[{e1v1,e2v2,…}]
返回对应于各个聚类中的 ei 的 vi.
FindClusters[data,n]
将 data 分割为 n 个聚类.
更多信息和选项





- FindClusters 将列表划分为相似元素的子列表(聚类). 聚类的数量和组成受输入数据、方法和使用的评估标准的影响. 元素可以属于多种数据类型,包括数字、文本和图像,以及日期和时间.
- 聚类通常用于以无监督的方式查找元素类别,例如客户类型、动物分类法、文档主题等. 对于监督分类,请参阅 Classify.
- 输入示例的标签 ei 可以用以下格式给出:
-
{e1,e2,…} 自身使用下标 ei {e1v1,e2v2,…} 元素 ei 和标签 vi 之间的规则列表 {e1,e2,…}{v1,v2,…} 所有元素和所有标签之间的规则 label1e1,label2e2,… 作为 Association 密钥的标签 - 可以通过以下方式指定聚类的数量:
-
Automatic 自动查找聚类数量 n 精确查找 n 个聚类 UpTo[n] 查找至多 n 个聚类 - 可给定以下选项:
-
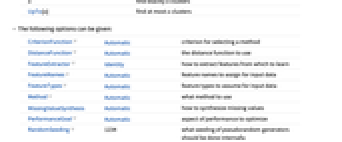
CriterionFunction Automatic 选择方法的标准 DistanceFunction Automatic 所用距离函数 FeatureExtractor Identity 怎样从要学习的内容中提取特征 FeatureNames Automatic 赋给输入数据的特征名称 FeatureTypes Automatic 输入数据的假定特征类型 Method Automatic 使用方式类型 MissingValueSynthesis Automatic 如何合成缺失值 PerformanceGoal Automatic 优化目标 RandomSeeding 1234 应该在内部对伪随机数生成器进行什么样的初始化 Weights Automatic 给定每个范例权重 - 默认情况下,FindClusters 将自动预处理数据,除非指定了 DistanceFunction.
- DistanceFunction 的设定可以是任意距离或相异度函数,或定义两个值之间距离的函数 f.
- PerformanceGoal 的可用设定包括:
-
Automatic 速度、准确度和内存的自动权衡 "Quality" 最大化分类器的准确性 "Speed" 最大化分类器速度 - Method 的可用设定包括:
-
Automatic 自动选择方法 "Agglomerate" 聚类算法单独连接 "DBSCAN" 基于密度的有噪声应用的空间聚类 "GaussianMixture" 变分高斯混合算法 "JarvisPatrick" Jarvis–Patrick 聚类算法 "KMeans" k 均值聚类算法 "KMedoids" 中心点周围的分割 "MeanShift" 均值平移聚类算法 "NeighborhoodContraction" 将数据点移向高密度区域 "SpanningTree" 树状聚类算法的最小填充 "Spectral" 谱聚类算法 - "KMeans" 和 "KMedoids" 方法仅可用在指定聚类数目时使用.
- "DBSCAN"、"GaussianMixture"、"JarvisPatrick"、"MeanShift" 和 "NeighborhoodContraction" 等方法只有在聚类数量为 Automatic 时才能使用.
- 下图显示了对玩具数据集应用常用方法得到的结果:
- CriterionFunction 的可用设定包括:
-
"StandardDeviation" 均方根值 (RMS) 标准差 "RSquared" R-平方 "Dunn" 邓恩指数 "CalinskiHarabasz" Calinski–Harabasz 指数 "DaviesBouldin" Davies–Bouldin 指数 "Silhouette" Silhouette 分数 Automatic 内部指数 - RandomSeeding 的可能设置包括:
-
Automatic 每次函数调用时自动重新播种 Inherited 使用外部播种的随机数字 seed 用明确给定的整数或字符串作为种子
范例
打开所有单元 关闭所有单元选项 (15)
CriterionFunction (1)
DistanceFunction (4)
用 CanberraDistance 作为连续数据的距离测量方法:
在默认的情况下,由 SquaredEuclideanDistance 获得聚类:
用 DiceDissimilarity 作为布尔数据的距离测量方法:
用 MatchingDissimilarity 作为布尔数据的距离测量方法:
用 HammingDistance 作为字符串数据的距离测量方法:
FeatureExtractor (1)
创建自定义 FeatureExtractor 来提取特征:
FeatureNames (1)
使用 FeatureNames 来命名特征,然后在进一步说明中引用其名称:
FeatureTypes (1)
使用 FeatureTypes 强制对特征的解释:
Method (4)
PerformanceGoal (1)
RandomSeeding (1)
属性和关系 (2)
文本
Wolfram Research (2007),FindClusters,Wolfram 语言函数,https://reference.wolfram.com/language/ref/FindClusters.html (更新于 2020 年).
CMS
Wolfram 语言. 2007. "FindClusters." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2020. https://reference.wolfram.com/language/ref/FindClusters.html.
APA
Wolfram 语言. (2007). FindClusters. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/FindClusters.html 年