Predict
Predict[{in1out1,in2out2,…}]
生成一个 PredictorFunction,尝试根据范例 ini 预测 outi.
Predict[data,input]
尝试预测与所给训练范例中的 input 相关联的输出.
Predict[data,input,prop]
计算相对于预测值的指定属性 prop.
更多信息和选项




- Predict 用于模拟标量变量与数字、文本、声音和图像等多种类型数据范例之间的关系.
- 这种建模也称为回归分析,通常用于客户行为分析、医疗结果预测、信用风险评估等任务.
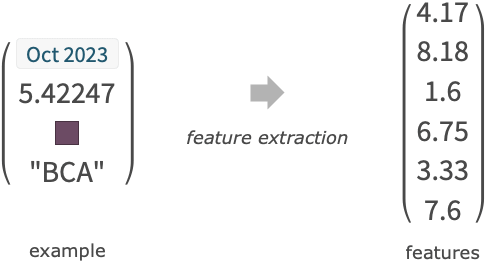
- 复杂的表达式会自动转换为数字或类等更简单的特征.
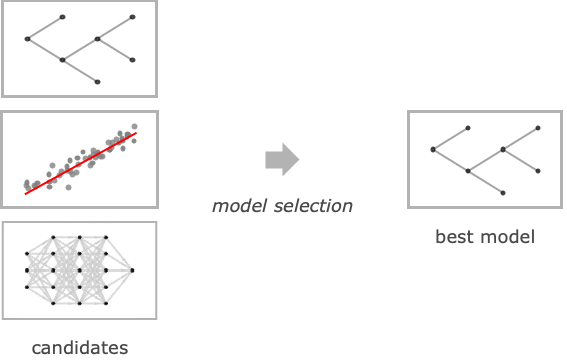
- 通过对训练数据进行交叉验证,选择最终的模型类型和超参数值.
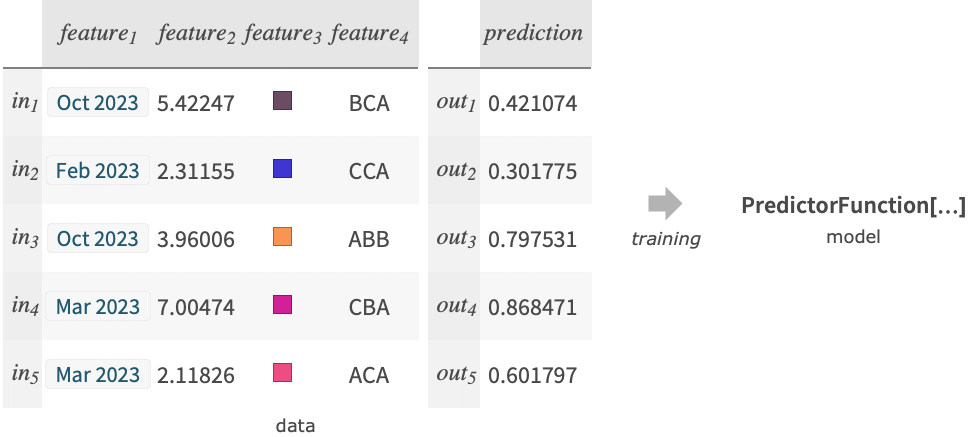
- 训练 data 的结构如下:
-
{in1out1,in2out2,…} 输入和输出之间的 Rule 列表 {in1,in2,…}{out1,out2,…} 输入和相应输出之间的 Rule {list1,list2,…}n 输出每个 List 的第 n 个元素 {assoc1,assoc2,…}"key" 将每个 Association 的 "key" 元素作为输出 Dataset[…]column Dataset 的指定 column 作为输出 - 此外,特殊形式的 data 还包括:
-
"name" 内置预测函数 FittedModel[…] 转换为 PredictorFunction[…] 的拟合模型 - 每个输入 ini 的范例可以是一个单独的数据元素、一个 {feature1, …} 或一个关联 <"feature1"value1,…>.
- 每个范例输出 outi 必须是一个数值.
- 预测属性 prop 与 PredictorFunction 中的相同. 包括:
-
"Decision" 根据分布和效用函数的最佳预测 "Distribution" 以输入为条件的值分布 "SHAPValues" 每个范例的 Shapley 可加性特征解释方法 "SHAPValues"n 使用 n 个样本进行 SHAP 解释 "Properties" 所有可用属性列表 - "SHAPValues" 通过比较移除然后合成不同特征集后的预测结果,来评估特征的贡献. 选项 MissingValueSynthesis 可用于指定缺失特征的合成方式. SHAP 解释以偏离训练输出平均值的方式给出.
- 内置预测函数的例子包括:
-
"NameAge" 给定名字,预测此人年龄 - 可提供以下选项:
-
AnomalyDetector None 预测器使用的异常检测器 AcceptanceThreshold Automatic 异常检测器的较罕见概率阈值 FeatureExtractor Identity 如何从学习中提取特征 FeatureNames Automatic 为输入数据指定的特征名称 FeatureTypes Automatic 输入数据的特征类型 IndeterminateThreshold 0 低于什么概率密度返回 Indeterminate Method Automatic 使用哪种回归算法 MissingValueSynthesis Automatic 如何合成缺失值 PerformanceGoal Automatic 试图优化的性能方面 RecalibrationFunction Automatic 如何对预测值进行后处理 RandomSeeding 1234 内部应如何为伪随机生成器播种 TargetDevice "CPU" 进行训练的目标设备 TimeGoal Automatic 用多长时间训练分类器 TrainingProgressReporting Automatic 如何报告培训期间的进展情况 UtilityFunction Automatic 效用是实际值和预测值的函数 ValidationSet Automatic 据以验证所生成模型的数据 - 使用 FeatureExtractor"Minimal" 表示内部预处理应尽可能简单.
- Method 的可能设置包括:
-

"DecisionTree" 用决策树预测 
"GradientBoostedTrees" 使用梯度提升训练的树群进行预测 
"LinearRegression" 根据特征的线性组合进行预测 
"NearestNeighbors" 根据最近邻接范例预测 
"NeuralNetwork" 利用人工神经网络进行预测 
"RandomForest" 根据 Breiman–Cutler 决策树集合进行预测 
"GaussianProcess" 使用函数的高斯过程先验进行预测 - PerformanceGoal 的可能设置包括:
-
"DirectTraining" 直接在完整数据集上进行训练,无需搜索模型 "Memory" 尽量减少预测器的存储需求 "Quality" 最大限度地提高预测器的准确性 "Speed" 最大限度地提高预测器的速度 "TrainingSpeed" 尽量减少生成预测器的时间 Automatic 自动平衡速度、准确性和内存 {goal1,goal2,…} 自动合并 goal1、goal2 等 - 可使用下列 TrainingProgressReporting 的设置:
-
"Panel" 显示动态更新的图形面板 "Print" 使用 Print 定期报告信息 "ProgressIndicator" 显示简单的 ProgressIndicator "SimplePanel" 动态更新面板,无需学习曲线 None 不报告任何信息 - Information 可用于获得的 PredictorFunction[…].
范例
打开所有单元关闭所有单元基本范例 (2)
范围 (23)
数据格式 (7)
数据类型 (12)
数量型 (1)
选项 (23)
AnomalyDetector (1)
FeatureExtractor (2)
使用 FeatureExtractor 生成预测器,用自定义函数预处理数据:
FeatureNames (2)
用特征已命名的训练集来训练预测器,并用 FeatureNames 来确定顺序:
FeatureTypes (2)
IndeterminateThreshold (1)
Method (4)
MissingValueSynthesis (1)
设置缺失值合成,以在给定已知值的情况下用其预测的最可能值替换每个缺失变量(这是默认行为):
对许多随机插补进行平均通常是最好的策略,并允许获得由插补引起的不确定性:
使用 "KernelDensityEstimation" 分布来预测具有缺失值的范例:
在训练时提供现有的 LearnedDistribution 以在训练和后续运算期间输入缺失值时使用它:
指定现有的 LearnedDistribution 以合成单个运算的缺失值:
PerformanceGoal (1)
TargetDevice (1)
使用神经网络训练系统默认 GPU 上的预测器,并查看 AbsoluteTiming:
TimeGoal (2)
TrainingProgressReporting (1)
UtilityFunction (2)
应用 (6)
基本线性回归 (1)
给定一些邻里的特征,训练预测器预测波士顿社区财产的中位数值:
产生一个 PredictorMeasurementsObject 来分析基于测试集合的预测器的性能:
天气分析 (1)
质量评估 (1)
可解释的机器学习 (1)
计算机视觉 (1)
客户行为分析 (1)
训练 "GradientBoostedTrees" 模型,根据其他特征预测总支出:
属性和关系 (1)
没有正则化的线性回归预测器和 LinearModelFit 可训练等价模型:
Fit 和 NonlinearModelFit 也可以是等价的:
可能存在的问题 (1)
文本
Wolfram Research (2014),Predict,Wolfram 语言函数,https://reference.wolfram.com/language/ref/Predict.html (更新于 2021 年).
CMS
Wolfram 语言. 2014. "Predict." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2021. https://reference.wolfram.com/language/ref/Predict.html.
APA
Wolfram 语言. (2014). Predict. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/Predict.html 年