NetTrain
NetTrain[net,{input1output1,input2output2,…}]
通过给出 inputi 作为输入,使用自动选择的损失函数最小化 outputi 和网络的实际输出之间的差异训练指定的神经网络.
NetTrain[net,port1{data11,data12,…},port2{…},…]
通过在指定端口提供训练数据训练指定神经网络.
NetTrain[net,"dataset"]
训练来自于 Wolfram 数据存储库的已命名数据集.
NetTrain[net,f]
在训练过程中调用函数 f 以产生成批的训练数据.
NetTrain[net,data,prop]
给出与训练会话的具体属性 prop 关联的数据.
给出一个总结训练会话信息的 NetTrainResultsObject[…].
更多信息和选项




- NetTrain 用于教导神经网络识别模式,并通过根据输入数据和正确输出调整其参数来进行预测.
- 在训练期间,使用梯度下降等优化算法调整网络的参数(例如权重和偏差),以最小化预测输出与实际输出之间的差异,从而随着时间的推移提高网络的准确性.
- 网络的任意一个形状不固定的输入端口将从训练数据的形式推断而得,同时,如果训练数据含有 Image 对象等,将会添加 NetEncoder 对象.
- data 可采用的形式包括:
-
"dataset" 已命名数据集 {input1output1,…} 输入和输出之间的 Rule 列表 {input1,…}->{output1,…} 输入和对应输出之间的 Rule {port1…,…,…} 由指定端口的输入构成的关联的列表 port1{data11,data12,…},… 一个关联,给出指定端口的输入列表 Dataset[…] 数据集对象 f 创建训练用批数据的函数 - 个别训练数据输入可以是标量、向量、数值数组. 如果网络附加有合适的 NetEncoder 对象,输入可以包括 Image 对象、字符串等.
- 命名数据集一般用作神经网络应用的范例,如下所示:
-
"MNIST" 60,000 分类的手写数字 "FashionMNIST" 60,000 衣服分类图像 "CIFAR-10","CIFAR-100" 50,000 真实世界对象的分类图像 "MovieReview" 10,662 条含有情感极性的影评片段 - 如果 ResourceObject["dataset"] 不存在,在已命名数据集上训练相当于在 ResourceData["dataset","TrainingData"] 或 ExampleData[{"MachineLearning","dataset"},"TrainingData"] 上训练. 如果已命名数据集被用于 ValidationSet 选项,则相当于 ResourceData["dataset","TestData"] 或 ExampleData[{"MachineLearning","dataset"},"TestData"].
- 当用规范 {input1output1,…} 给出训练数据时,网络不应含有任何损失层,应该正好只有一个输入和输出端口.
- 指定训练数据的其他格式包括 {input1,input2,…}->{output1,…} 和 {port1…,port2…,…,port1…,…,…}.
- 当损失层是由 NetTrain 自动附加到输出端口上时,它们的 "Target" 端口将取自训练数据,使用与原来输出端口同样的名称.
- 支持下列选项:
-
BatchSize Automatic 一次处理多少个实例 LearningRate Automatic 调整权重最小化损失的速率 LearningRateMultipliers Automatic 设定网络内的相对学习速率 LossFunction Automatic 访问输出的损失函数 MaxTrainingRounds Automatic 遍历训练数据多少次 Method Automatic 所用的训练方法 PerformanceGoal Automatic 具有特定优势的偏好设置 TargetDevice "CPU" 执行训练的目标设备 TimeGoal Automatic 训练的秒数 TrainingProgressMeasurements Automatic 训练期间监控、跟踪和绘图的测量 TrainingProgressCheckpointing None 怎样定期保存已部分训练过的网络 RandomSeeding 1234 如何内部播种伪随机生成器 TrainingProgressFunction None 训练过程中周期性调用的函数 TrainingProgressReporting Automatic 训练过程中怎样汇报进度 TrainingStoppingCriterion None 如何自动停止训练 TrainingUpdateSchedule Automatic 何时更新特定部分的网络 ValidationSet None 训练中用于计算模型的数据集 WorkingPrecision Automatic 浮点计算的精度 - 如果没有使用 LossFunction 明显给出损失,损失函数会基于网络中的最终层或各层自动选择.
- 如果采用默认设置 BatchSize->Automatic,批次大小将根据网络的内存要求和目标设备上可用的内存自动选择. 自动选择的最大批次大小为 64.
- 默认设置为 MaxTrainingRounds->Automatic, 大约每 20 秒进行一次训练,但是不会超过 10,000 次.
- 当设置为 MaxTrainingRounds->n,训练会发生 n 次,其中,一次定义为遍历整个训练数据集.
- 可以给出下列 ValidationSet 的设置:
-
None 只使用现有训练集来估计损失(缺省) data 验证集的形式和训练数据一样 Scaled[frac] 保留部分训练集用来进行验证 {spec,"Interval"int} 指定计算验证损失的间隔 - 对于 ValidationSet->{spec,"Interval"->int},间隔可以是整数 n,表示每 n 轮训练,或以秒、分钟、小时为单位的 Quantity 时间后计算一次验证损失.
- 对于命名数据集,例如 "MNIST",指定 ValidationSet->Automatic 会使用对应的 "TestData" 内容元素.
- 如果验证集已被指定,NetTrain 将返回训练期间相对于该集合给出最低验证损失的网络.
- 在 NetTrain[net,f] 中,函数 f 被应用于 <"BatchSize"n,"Round"r> 来产生形式为 {input1->output1,…} 或 <"port1"->data,…> 的训练数据.
- NetTrain[net,{f,"RoundLength"->n}] 可用于指定在训练时应用 f 多次产生大约 n 个范例. 默认情况下每次训练应用 f 一次.
- 为了计算验证损失和准确性,NetTrain[net,…,ValidationSet->{g,"RoundLength"->n}] 可用于指定函数 g 应该以与 NetTrain[net,{f,"RoundLength"->n}] 等价的方式应用产生大约 n 个范例.
- TargetDevice 可取的设置包括:
-
"CPU" 在 CPU 上训练 "GPU" 在 CUDA(兼容 GPU)上训练 - "GPU" 设置被解析为 "CUDA". 目前不支持其他设置.
- WorkingPrecision 的可能设置包括:
-
"Real32" 使用单精度实数 (32-bit) "Real64" 使用双精度实数 (64-bit) "Mixed" 某些运算使用半精度实数 - WorkingPrecision->"Mixed" 只支持 TargetDevice->"GPU",在某些设备上可以导致显著的性能增加.
- 在 NetTrain[net,data,loss,prop] 中,属性 prop 可以是下列形式之一:
-
"TrainedNet" 找到的最佳的训练好的网络(默认) "BatchesPerRound" 每轮包含多少批次 "BatchLossList" 每个批量更新的平均损失的列表 "BatchMeasurementsLists" 每个批量更新的训练度量关联的列表 "BatchPermutation" 用于填充每个批次的训练数据的索引数组 "BatchSize" BatchSize 的有效值 "BestValidationRound" 与最终训练好的网络对应的训练回合 "CheckpointingFiles" 训练期间产生的检查点文件列表 "ExampleLosses" 训练期间每个样例接受的损失 "ExamplesProcessed" 训练期间处理的样例总数 "FinalLearningRate" 训练结束时的学习率 "FinalNet" 在训练过程中生成的最新网络,无论其在验证集或其他指标上的表现如何 "FinalPlots" 所有损失和度量图的关联 "InitialLearningRate" 训练开始时的学习率 "LossPlot" 平均训练损失的演变图 "MeanBatchesPerSecond" 每秒处理的平均批数 "MeanExamplesPerSecond" 每秒处理的输入样例的平均数 "NetTrainInputForm" 表示对 NetTrain 的始发调用的表达式 "OptimizationMethod" 使用的优化方法的名称 "Properties" 可用属性列表 "ReasonTrainingStopped" 为什么训练停止的简短描述 "ResultsObject" NetTrainResultsObject[…] 包含表格中大部分可用属性 "RoundLoss" 最新回合的平均损失 "RoundLossList" 每轮的平均损失列表 "RoundMeasurements" 最新回合训练度量的关联 "RoundMeasurementsLists" 每轮的训练度量关联的列表 "RoundPositions" 对应于每轮度量的 batch number "TargetDevice" 用于训练的设备 "TotalBatches" 训练期间碰到的总批数 "TotalRounds" 训练的总轮数 "TotalTrainingTime" 花在训练上的总时间(以秒为单位) "TrainingExamples" 训练集中的样例数 "TrainingNet" 准备进行训练的网络 "TrainingUpdateSchedule" TrainingUpdateSchedule 的值 "ValidationExamples" 验证集中的样例数 "ValidationLoss" 对于最新的验证度量,在 ValidationSet 上获取的平均损失 "ValidationLossList" 每次验证度量在 ValidationSet 上的平均损失的列表 "ValidationMeasurements" 最新验证度量后 ValidationSet 上训练度量的关联 "ValidationMeasurementsLists" 每次验证度量在 ValidationSet 上的训练度量关联的列表 "ValidationPositions" 与每次验证度量对应的 batch number "WeightsLearningRateMultipliers" 用于每个权重的学习率乘子的关联 - 格式 <"Property"->prop,"Form"->form,"Interval"->int> 的关联可用于指定自定义属性,其值在训练时会被重复收集.
- 对于自定义属性,prop 的有效设置可以是 TrainingProgressFunction 上的任何可用属性,或给定所有属性关联的用户定义函数. 表单的有效设置包括 "List"、"TransposedList" 和 "Plot". "Interval" 的有效设置可以是 "Batch"、"Round" 或 Quantity[…]. 支持的单位包括 "Batches"、"Rounds"、"Percent" 和时间单位,比如,"Seconds"、"Minutes" 和 "Hours".
- NetTrain[net,data,loss,{prop1,prop2,…}] 返回 propi 的结果列表.
- NetTrain[net,data,All] 返回一个 NetTrainResultsObject[…] 包含不需要显著额外计算或内存的所有属性值.
- 使用 ValidationSet->None 的默认设置,"TrainedNet" 属性会在训练结束时生成网络. 当提供验证集时,选择最佳网络的默认标准取决于网络的类型:
-
classification net 选择带有最低错误率的网络;使用最低损失打破关系 non-classification net 选择带有最低损失的网络 - 用于选择 "TrainedNet" 属性的标准可以使用 TrainingStoppingCriterion 选项自定义.
- 属性 "BestValidationRound" 给出了选择最终网络的精确回合.
- Method 的可能设置包括:
-
"ADAM" 使用对梯度的对角重定标不变的自适应学习速率的随机梯度下降 "RMSProp" 使用从梯度幅度的指数平滑平均值导出的自适应学习速率的随机梯度下降 "SGD" 普通的带有动量的随机梯度下降 "SignSGD" 随机梯度下降,其中,梯度幅度被丢弃 - PerformanceGoal 的有效设置包括 Automatic、"TrainingMemory"、"TrainingSpeed" 或目标列表组合.
- WorkingPrecision 的有效设置包括 "Real32" 的默认值,表示单精度浮点;"Real64" 表示双精度浮点;"Mixed" 表示 "Real32" 和半精度的混合. 混合精度的训练只支持 GPU .
- 可以用 Method{"method",opt1val1,…} 来指定特定方法的子选项. 所有方法都可使用的子选项有:
-
"LearningRateSchedule" Automatic 如何按照训练进程调整学习速率 "L2Regularization" None 与所有习得数组的 L2 范数关联的全局损失 "GradientClipping" None 梯度将被剪切的幅值下限 "WeightClipping" None 大于该值的幅值的权重应被截掉 - 当设置为 "LearningRateSchedule"->f 时,将用 initial*f[batch,total] 来计算给定批次的学习速率,其中 batch 是当前的批号,total 是训练期间将要处理的总批次数,initial 是用 LearningRate 选项指定的初始训练速率. 由 f 返回的值应是 0 和 1 之间的一个数字.
- 可以用下列形式给出子选项 "L2Regularization"、"GradientClipping" 和 "WeightClipping":
-
r 网络中的所有权重都使用数值 r {lspec1r1,lspec2r2,…} 对网络中的特定部分 lspeci 使用数值 ri - 按 LearningRateMultipliers 的同样形式给出规则 lspeciri.
- 对于方法 "SGD",额外支持下列子选项
-
"Momentum" 0.93 在更新导数时保留多少前一步的结果 - 对于方法 "ADAM",额外支持下列子选项:
-
"Beta1" 0.9 第一动量估计的指数衰减率 "Beta2" 0.999 第二动量估计的指数衰减率 "Epsilon" 0.00001` 稳定性参数 - 对于方法 "RMSProp",额外支持下列子选项:
-
"Beta" 0.95 梯度幅度移动平均值的指数衰减率 "Epsilon" 0.000001 稳定性参数 "Momentum" 0.9 动量项 - 对于方法 "SignSGD",支持以下其他子选项:
-
"Momentum" 0.93 当更新导数时,保留前一步的程度 - 如果网络已经含有初始化过的或之前已训练过的权重,训练开始之前 NetTrain 不会重新进行初始化.
范例
打开所有单元关闭所有单元基本范例 (6)
通过禁用 NetDecoder 获取输入为 True 的概率:
范围 (14)
数据格式 (7)
属性 (4)
获取一个用于训练会话的 NetTrainResultsObject:
获取调用 NetTrain 的原始格式:
通过计算每个范例的平均损失计算最困难的范例,并接受 20 个最大的索引,例如平均损失:
选项 (27)
BatchSize (1)
LearningRateMultipliers (1)
LossFunction (4)
用 MeanSquaredLossLayer 训练一个简单网络,在损失不是由 SoftmaxLayer 产生的时候应用缺省的损失:
创建一个网络,接受长度为 2 的向量,产生类别 Less 或 Greater 中的一个:
NetTrain 会自动使用带有合适类别编码器的 CrossEntropyLossLayer 对象:
从一个将要被训练的 "evaluation net" 开始:
创建一个 "loss net",显式计算评估网络(此处,自定义损失等价于 MeanSquaredLossLayer)的损失:
在合成数据上训练该网络,指定名为 "Loss" 的输出端口应被诠释为损失:
用 NetExtract 获取训练过的 "evaluation" 网络:
也可以使用 Part 语句:
保留想要的输出和输入,用 NetTake 移除其他输出:
MaxTrainingRounds (2)
Method (2)
TargetDevice (1)
TrainingProgressFunction (1)
用 TrainingProgressFunction 在文件中追加训练状态的信息. 创建日志文件:
把保存的数据存入 Dataset:
TrainingProgressReporting (6)
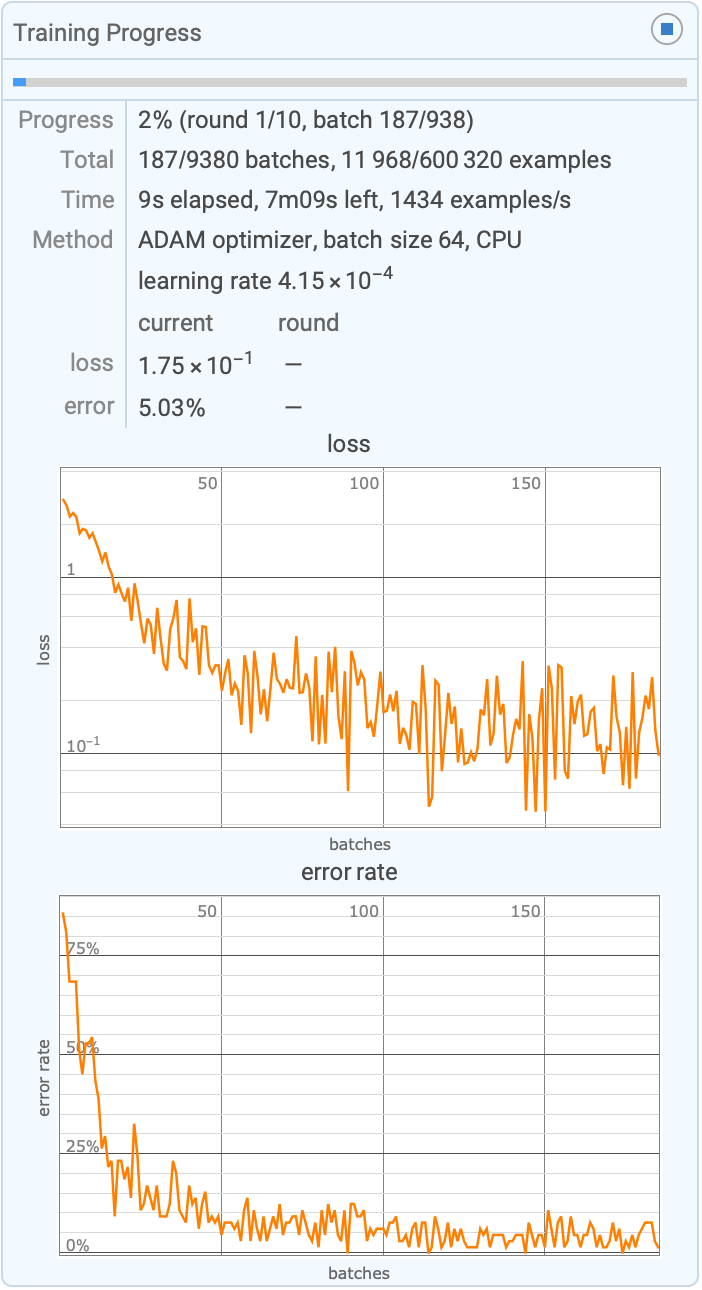
TrainingStoppingCriterion (1)
当验证损失停止改善时,通过停止训练阻止过度拟合. 设置简单的网络以及某些训练和验证数据:
当验证损失停止改善时,使用 TrainingStoppingCriterion 停止训练:
如果在超过 5 轮的训练中验证损失没有改善至少 0.001,使用 TrainingStoppingCriterion 停止训练:
TrainingUpdateSchedule (1)
通过交替更新判别器和生成器训练一个 NetGANOperator:
ValidationSet (1)
为 NetTrain 提供 ValidationSet 来防止过拟合. 基于高斯曲线创建混合训练数据:
用 ValidationSet 选项使 NetTrain 选择训练中实现最低验证损失的网络. NetTrain 将从训练数据中随机选择 20% 的数据作为验证集:
NetTrain 返回的结果为能最好地归纳验证集中的点的网络,用验证损失来度量. 这将惩罚过度拟合,因为出现在训练数据中的噪声与验证集中的噪声无关:
可能存在的问题 (1)
默认情况下,NetTrain 使用 RandomSeeding1234,当重复调用 NetTrain,它会使用同样的随机种子初始化网络:
使用 RandomSeedingAutomatic 确保 NetTrain 的重复调用时使用不同的初始化:
文本
Wolfram Research (2016),NetTrain,Wolfram 语言函数,https://reference.wolfram.com/language/ref/NetTrain.html (更新于 2022 年).
CMS
Wolfram 语言. 2016. "NetTrain." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2022. https://reference.wolfram.com/language/ref/NetTrain.html.
APA
Wolfram 语言. (2016). NetTrain. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/NetTrain.html 年