



NetTrain
NetTrain[net,{input1output1,input2output2,…}]
trains the specified neural net by giving the inputi as input and minimizing the discrepancy between the outputi and the actual output of the net, using an automatically chosen loss function.
NetTrain[net,port1{data11,data12,…},port2{…},…]
trains the specified net by supplying training data at the specified ports.
NetTrain[net,"dataset"]
trains on a named dataset from the Wolfram Data Repository.
NetTrain[net,f]
calls the function f during training to produce batches of training data.
NetTrain[net,data,"prop"]
gives data associated with a specific property prop of the training session.
gives a NetTrainResultsObject[…] that summarizes information about the training session.
Details and Options
- NetTrain is used to teach a neural net to recognize patterns and make predictions by adjusting its parameters based on input data and correct outputs.
- During training, the network's parameters, such as weights and biases, are adjusted using optimization algorithms like gradient descent to minimize the difference between the predicted outputs and the actual outputs, thus improving the network's accuracy over time.
- Any input ports of the net whose shapes are not fixed will be inferred from the form of training data, and NetEncoder objects will be attached if the training data contains Image objects etc.
- Possible forms of data include:
-
"dataset" a named dataset {input1output1,…} a list of Rule instances between input and output {input1,…}->{output1,…} a Rule between inputs and corresponding outputs {port1…,…,…} a list of associations with inputs for the specified ports port1{data11,data12,…},… a association of lists of input for the specified ports Dataset[…] a dataset object Tabular[…] a tabular object f a function that creates training batches - Individual training data inputs can be scalars, vectors, numeric tensors. If the net has appropriate NetEncoder objects attached, the inputs can include Image objects, strings, etc.
- Named datasets that are commonly used as examples for neural net applications include the following:
-
"MNIST" 60,000 classified handwritten digits "FashionMNIST" 60,000 classified images of items of clothing "CIFAR-10","CIFAR-100" 50,000 classified images of real-world objects "MovieReview" 10,662 movie review snippets with sentiment polarity - Training on a named dataset is equivalent to training on ResourceData["dataset","TrainingData"], or ExampleData[{"MachineLearning","dataset"},"TrainingData"] if ResourceObject["dataset"] does not exist. If a named dataset is used for the ValidationSet option, it is equivalent to ResourceData["dataset","TestData"] or ExampleData[{"MachineLearning","dataset"},"TestData"].
- When giving training data using the specification {input1output1,…}, the network should not already contain any loss layers and should have precisely one input and one output port.
- Additional forms for specifying training data include {input1,input2,…}->{output1,…} and {port1…,port2…,…,port1…,…,…}.
- When loss layers are automatically attached by NetTrain to output ports, their "Target" ports will be taken from the training data using the same name as the original output port.
- The following options are supported:
-
BatchSize Automatic how many examples to process in a batch LearningRate Automatic rate at which to adjust weights to minimize loss LearningRateMultipliers Automatic set relative learning rates within the net LossFunction Automatic the loss function for assessing outputs MaxTrainingRounds Automatic how many times to traverse the training data Method Automatic the training method to use PerformanceGoal Automatic favor settings with specific advantages TargetDevice "CPU" the target device on which to perform training TimeGoal Automatic number of seconds to train for TrainingProgressMeasurements Automatic measurements to monitor, track and plot during training TrainingProgressCheckpointing None how to periodically save partially trained nets RandomSeeding 1234 how to seed pseudorandom generators internally TrainingProgressFunction None function to call periodically during training TrainingProgressReporting Automatic how to report progress during training TrainingStoppingCriterion None how to automatically stop training TrainingUpdateSchedule Automatic when to update specific parts of the net ValidationSet None the set of data on which to evaluate the model during training WorkingPrecision Automatic precision of floating-point calculations - If the loss is not given explicitly using LossFunction, a loss function will be chosen automatically based on the final layer or layers in the net.
- With the default setting of BatchSize->Automatic, the batch size will be chosen automatically, based on the memory requirements of the network and the memory available on the target device. The maximum batch size that will be automatically chosen is 64.
- With the default setting of MaxTrainingRounds->Automatic, training will occur for approximately 20 seconds, but never for more than 10,000 rounds.
- With the setting of MaxTrainingRounds->n, training will occur for n rounds, where a round is defined to be a traversal of the entire training dataset.
- The following settings for ValidationSet can be given:
-
None use only the existing training set to estimate loss (default) data validation set in the same form as training data Scaled[frac] reserve a specified fraction of the training set for validation {spec,"Interval"int} specify the interval at which to calculate validation loss - For ValidationSet->{spec,"Interval"->int}, the interval can be an integer n, indicating that validation loss should be calculated every n training rounds, or a Quantity in units of seconds, minutes or hours.
- For a named dataset such as "MNIST", specifying ValidationSet->Automatic will use the corresponding "TestData" content element.
- If a validation set is specified, NetTrain will return the net that produced the lowest validation loss during training with respect to this set.
- In NetTrain[net,f], the function f is applied to <"BatchSize"n,"Round"r> to generate each batch of training data in the form {input1->output1,…} or <"port1"->data,…>.
- NetTrain[net,{f,"RoundLength"->n}] can be used to specify that f should be applied enough times during a training round to produce approximately n examples. The default is to apply f once per training round.
- NetTrain[net,…,ValidationSet->{g,"RoundLength"->n}] can be used to specify that the function g should be applied in an equivalent manner to NetTrain[net,{f,"RoundLength"->n}] in order to produce approximately n examples for the purposes of computing validation loss and accuracy.
- Possible settings for TargetDevice include:
-
"CPU" train on the CPU "GPU" train on a CUDA-compatible GPU - The "GPU" setting is resolved to "CUDA". Other settings are currently not supported.
- Possible settings for WorkingPrecision include:
-
"Real32" use single-precision real (32-bit) "Real64" use double-precision real (64-bit) "Mixed" use half-precision real for certain operations - WorkingPrecision->"Mixed" is only supported for TargetDevice->"GPU", where it can result in significant performance increases on certain devices.
- In NetTrain[net,data,prop], the property prop can be any of the following:
-
"TrainedNet" the optimal trained network found (default) "BatchesPerRound" the number of batches contained in a single round "BatchLossList" a list of the mean losses for each batch update "BatchMeasurementsLists" list of training measurements associations for each batch update "BatchPermutation" an array of the indices from the training data used to populate each batch "BatchSize" the effective value of BatchSize "BestValidationRound" the training round corresponding to the final trained net "CheckpointingFiles" list of checkpointing files generated during training "ExampleLosses" losses taken by each example during training "ExamplesProcessed" total number of examples processed during training "FinalLearningRate" the learning rate at the end of training "FinalNet" the most recent network generated in the training process, regardless of its performance on the validation set or other metrics "FinalPlots" association of plots for all losses and measurements "InitialLearningRate" the learning rate at the start of training "LossPlot" a plot of the evolution of the mean training loss "MeanBatchesPerSecond" the mean number of batches processed per second "MeanExamplesPerSecond" the mean number of input examples processed per second "NetTrainInputForm" an expression representing the originating call to NetTrain "OptimizationMethod" the name of the optimization method used "Properties" the full list of available properties "ReasonTrainingStopped" brief description of why training stopped "ResultsObject" a NetTrainResultsObject[…] containing a majority of the available properties in this table "RoundLoss" the mean loss for the most recent round "RoundLossList" a list of the mean losses for each round "RoundMeasurements" association of training measurements for the most recent round "RoundMeasurementsLists" list of training measurements associations for each round "RoundPositions" the batch numbers corresponding to each round measurement "TargetDevice" the device used for training "TotalBatches" the total number of batches encountered during training "TotalRounds" the total number of rounds of training performed "TotalTrainingTime" the total time spent training, in seconds "TrainingExamples" the number of examples in the training set "TrainingNet" the network as prepared for training "TrainingUpdateSchedule" the value of TrainingUpdateSchedule "ValidationExamples" the number of examples in the validation set "ValidationLoss" the mean loss obtained on the ValidationSet for the most recent validation measurement "ValidationLossList" list of the mean losses on the ValidationSet for each validation measurement "ValidationMeasurements" association of training measurements on the ValidationSet after the most recent validation measurement "ValidationMeasurementsLists" list of training measurements associations on the ValidationSet for each validation measurement "ValidationPositions" the batch numbers corresponding to each validation measurement "WeightsLearningRateMultipliers" an association of the learning rate multiplier used for each weight - An association of the form <"Property"->prop,"Form"->form,"Interval"->int> can be used to specify a custom property whose value will be collected repeatedly during training.
- For a custom property, valid settings for prop can be any of the properties available in TrainingProgressFunction, or a user-defined function that is given the association of all the properties. Valid settings for form include "List", "TransposedList" and "Plot". Valid settings for "Interval" can be "Batch", "Round" or a Quantity[…]. Supported units include "Batches", "Rounds", "Percent" and time units like "Seconds", "Minutes" and "Hours".
- NetTrain[net,data,{prop1,prop2,…}] returns a list of the results for the propi.
- NetTrain[net,data,All] returns a NetTrainResultsObject[…] that contains values for all properties that do not require significant additional computation or memory.
- With the default setting of ValidationSet->None, the "TrainedNet" property yields the net as it is at the end of training. When a validation set is provided, the default criterion for selecting the optimal net depends on the type of net:
-
classification net choose the net with the lowest error rate; ties are broken using the lowest loss non-classification net choose the net with the lowest loss - The criterion used to select the "TrainedNet" property can be customized using the TrainingStoppingCriterion option.
- The property "BestValidationRound" gives the exact round from which the final net was selected.
- Possible settings for Method include:
-
"ADAM" stochastic gradient descent using an adaptive learning rate that is invariant to diagonal rescaling of the gradients "RMSProp" stochastic gradient descent using an adaptive learning rate derived from exponentially smoothed average of gradient magnitude "SGD" ordinary stochastic gradient descent with momentum "SignSGD" stochastic gradient descent for which the magnitude of the gradient is discarded - Valid settings for PerformanceGoal include Automatic, "TrainingMemory", "TrainingSpeed" or a list of goals to combine.
- Valid settings for WorkingPrecision include the default value of "Real32", indicating single-precision floating point; "Real64", indicating double-precision floating point; and "Mixed", indicating a mixture of "Real32" and half-precision. Mixed-precision training is only supported for GPUs.
- Suboptions for specific methods can be specified using Method{"method",opt1val1,…}. The following suboptions are supported for all methods:
-
"LearningRateSchedule" Automatic how to scale the learning rate as training progresses "L2Regularization" None the global loss associated with the L2 norm of all learned arrays "GradientClipping" None the magnitude above which gradients should be clipped "WeightClipping" None the magnitude above which weights should be clipped - With "LearningRateSchedule"->f, the learning rate for a given batch will be calculated as initial*f[batch,total], where batch is the current batch number, total is the total number of batches that will be visited during training, and initial is the initial learning rate specified using the LearningRate option. The value returned by f should be a number between 0 and 1.
- The suboptions "L2Regularization", "GradientClipping" and "WeightClipping" can be given in the following forms:
-
r use the value r for all weights in the net {lspec1r1,lspec2r2,…} use the value ri for the specific part lspeci of the net - The rules lspeciri are given in the same form as for LearningRateMultipliers.
- For the method "SGD", the following additional suboptions are supported:
-
"Momentum" 0.93 how much to preserve the previous step when updating the derivative - For the method "ADAM", the following additional suboptions are supported:
-
"Beta1" 0.9 exponential decay rate for the first moment estimate "Beta2" 0.999 exponential decay rate for the second moment estimate "Epsilon" 0.00001` stability parameter - For the method "RMSProp", the following additional suboptions are supported:
-
"Beta" 0.95 exponential decay rate for the moving average of the gradient magnitude "Epsilon" 0.000001 stability parameter "Momentum" 0.9 momentum term - For the method "SignSGD", the following additional suboption is supported:
-
"Momentum" 0.93 how much to preserve the previous step when updating the derivative - If a net already contains initialized or previously trained weights, these will be not be reinitialized by NetTrain before training is performed.
Examples
open all close allBasic Examples (1)
Train a single-layer linear net on input output pairs:
trained = NetTrain[LinearLayer[], {1 -> 1.9, 2 -> 4.1, 3 -> 6.0, 4 -> 8.1}]Predict the value of a new input:
trained[2.1]Make several predictions at once:
trained[{1, 2, 3, 4}]The prediction is a linear function of the input:
Plot[trained[x], {x, 0, 5}]Scope (15)
Networks (3)
NetTrain[LinearLayer[], {0.1 -> 0.3, 0.5 -> 0.8, 0.7 -> 0.2, 0.9 -> 0.5}]Train a linear chain of layers:
NetTrain[NetChain[{1, 3, 3, 1}], {0.1 -> 0.3, 0.5 -> 0.8, 0.7 -> 0.2, 0.9 -> 0.5}]Train a directed graph of layers:
NetTrain[NetGraph[{1, 3, 3, 1}, {1 -> 2 -> 3 -> 4}], {0.1 -> 0.3, 0.5 -> 0.8, 0.7 -> 0.2, 0.9 -> 0.5}]Data Formats (8)
Specify training data as a list of rules, each representing an input and the corresponding target output:
NetTrain[LinearLayer[], {1 -> 1.9, 2 -> 4.1, 3 -> 6.0, 4 -> 8.1}]Specify training data as a rule whose left-hand side is a list of inputs, and whose right-hand side is a list of the corresponding target outputs:
NetTrain[LinearLayer[], {1, 2, 3, 4} -> {1.9, 4.1, 6., 8.1}]Specify training data as an association whose keys are port names:
NetTrain[LinearLayer[], <|"Input" -> {1, 2, 3, 4}, "Output" -> {1.9, 4.1, 6., 8.1}|>]Specify training data as a list of associations, each representing a single training example:
NetTrain[LinearLayer[], {<|"Input" -> 1, "Output" -> 1.9|>, <|"Input" -> 2, "Output" -> 4.1|>, <|"Input" -> 3, "Output" -> 6.|>, <|"Input" -> 4, "Output" -> 8.1|>}]Train a net using a named dataset:
NetTrain[NetModel["LeNet"], "MNIST"]Specify training data as a Dataset whose rows are individual examples:
dataset = Dataset[{<|"Input" -> 1, "Output" -> 1.9|>, <|"Input" -> 2, "Output" -> 4.1|>, <|"Input" -> 3, "Output" -> 6.|>, <|"Input" -> 4, "Output" -> 8.1|>}]NetTrain[LinearLayer[], dataset]Specify training data as a Tabular object whose rows are individual examples:
tab = Tabular[{<|"Input" -> 1, "Output" -> 1.9|>, <|"Input" -> 2, "Output" -> 4.1|>, <|"Input" -> 3, "Output" -> 6.|>, <|"Input" -> 4, "Output" -> 8.1|>}]NetTrain[LinearLayer[], tab]Generate training data during training. First create a network to train:
net = NetChain[{32, Tanh, 1}, "Input" -> 2, "Output" -> "Scalar"]Define a generator to produce a batch of examples in the form of a list of rules:
generator = Function[Table[
{a, b} = RandomReal[{-1, 1}, 2];{a, b} -> (a * b), #BatchSize]];generator[<|"BatchSize" -> 4|>]Train using the generator with a specific BatchSize:
trained = NetTrain[net, generator, BatchSize -> 16]Specify that the generator should be called 4 times per round, to produce 64 examples per round:
trained = NetTrain[net, {generator, "RoundLength" -> 64}, BatchSize -> 16]Properties (4)
Obtain a NetTrainResultsObject for a training session:
net = NetModel["LeNet"];
data = RandomSample[ResourceData["MNIST"], 1000];
results = NetTrain[net, data, All, MaxTrainingRounds -> 20]Query the results object for specific properties:
results["LossPlot"]results["RoundMeasurements", "ErrorRate"]results["TotalTrainingTime"]results["TrainedNet"]Get the original form of the call to NetTrain:
results["NetTrainInputForm"]Get a list of all available properties:
results["Properties"]Obtain plots of the evolution of the magnitude of the per-array gradients during the training of a convolutional net:
net = NetModel["LeNet"];
data = RandomSample[ResourceData["FashionMNIST"], 2048];
NetTrain[net, data, <|"Property" -> "GradientsRMS", "Form" -> "EvolutionPlot", "PlotOptions" -> {ScalingFunctions -> "Log"}, "Interval" -> "Batch"|>, MaxTrainingRounds -> 50, BatchSize -> 256]Train on the MNIST dataset and record the losses of individual examples through time:
net = NetModel["LeNet"];
data = ResourceData["MNIST"];losses = NetTrain[net, data, <|"Property" -> "ExampleLosses", "Form" -> "TransposedList"|>, MaxTrainingRounds -> 10, BatchSize -> 64];Plot the loss associated with a single example over time:
ListLogPlot[losses[[20]], Joined -> True, PlotRange -> All]Find the most difficult examples by calculating the mean loss for each example and taking the indices of the 20 largest such mean losses:
meanLosses = Map[Mean, losses];
Keys@Part[data, Ordering[meanLosses, -20]]Show the average evolution of losses and error rates for the digits "0", "3", "8" and "9":
labels = Values[data];
plotHistory[history_, subset_, title_] := ListLogPlot[
Table[Mean@Rest@Pick[history, labels, i], {i, subset}],
Joined -> True, PlotLegends -> subset, Frame -> True, ImageSize -> Medium, GridLines -> Automatic, FrameLabel -> {"round", title}, PlotLabels -> subset]plotHistory[losses, {0, 3, 8, 9}, "per-class loss"]Create customized versions of the final plots:
net = NetModel["LeNet"];
data = RandomSample[ResourceData["FashionMNIST"], 2048];
{batchLosses, roundLosses, validationLosses, roundPositions, validationPositions, lossPlot} = NetTrain[net, data, {"BatchLossList", "RoundLossList", "ValidationLossList", "RoundPositions", "ValidationPositions", "LossPlot"}, ValidationSet -> Scaled[0.2]];Examine the original loss plot:
lossPlotCreate a new loss plot using only the round and validation measurements:
ListLinePlot[{Transpose[{validationPositions, validationLosses}], Transpose[{roundPositions, roundLosses}]}, ScalingFunctions -> "Log", ImageSize -> Medium, PlotLegends -> {"validation", "round"}]Create a new loss plot without the logarithmic scaling:
ListLinePlot[{Transpose[{validationPositions, validationLosses}], Transpose[{Range[Length[batchLosses]], batchLosses}]}, ScalingFunctions -> None, ImageSize -> Medium, PlotLegends -> {"validation", "training"}]Options (27)
BatchSize (1)
Using a large batch size will typically increase the number of examples that can be evaluated per second:
trainingData = RandomReal[1, {10000, 4}] -> RandomReal[1, {10000, 4}];
net = NetChain[{LinearLayer[8], LinearLayer[4]}, "Input" -> 4];
NetTrain[net, trainingData, "MeanInputsPerSecond", BatchSize -> 512, MaxTrainingRounds -> 20]A smaller batch size results in fewer examples being evaluated per second:
NetTrain[net, trainingData, "MeanInputsPerSecond", BatchSize -> 32, MaxTrainingRounds -> 20]Depending on the task and network, larger batch sizes will allow higher learning rates to be used and can also allow for more efficient use of available hardware.
LearningRate (1)
LearningRateMultipliers (1)
Create and initialize a net with three layers, but train only the last layer:
net = NetInitialize@NetChain[{LinearLayer[3], Ramp, LinearLayer[{}]}, "Input" -> "Real", "Output" -> "Real"]trained = NetTrain[net, {1 -> 1.9, 2 -> 4.1, 3 -> 6.0, 4 -> 8.1}, LearningRateMultipliers -> {3 -> 1, _ -> None}]Evaluate the trained net on an input:
trained[1]The first layer of the initial net started with zero biases:
NetExtract[net, {1, "Biases"}]The biases of the first layer remain zero in the trained net:
NetExtract[trained, {1, "Biases"}]The biases of the third layer have been trained:
NetExtract[trained, {3, "Biases"}]LossFunction (4)
Train a simple net using MeanSquaredLossLayer, the default loss applied to an output when it is not produced by a SoftmaxLayer:
net = LinearLayer[];
data = {1 -> 1.9, 2 -> 4.1, 3 -> 6.0, 4 -> 8.1};
trained = NetTrain[net, data]Evaluate the trained net on a set of inputs:
trained[Range[4]]Specify a different loss layer to attach to the output of the network. First create a loss layer:
loss = MeanAbsoluteLossLayer[]The loss layer takes an input and a target and produces a loss:
loss[<|"Input" -> 5.0, "Target" -> 3.0|>]Use this loss layer during training:
trained = NetTrain[net, data, LossFunction -> loss]Evaluate the trained net on a set of inputs:
trained[Range[4]]Create a net that takes a vector of length 2 and produces one of the class labels Less or Greater:
net = NetChain[{LinearLayer[2], SoftmaxLayer[]}, "Output" -> NetDecoder[{"Class", {Less, Greater}}]]NetTrain will automatically use a CrossEntropyLossLayer object with the correct class encoder:
trained = NetTrain[net, {{1, 2} -> Less, {2, 3} -> Less, {4, 2} -> Greater, {3, 1} -> Greater}]Evaluate the trained net on a set of inputs:
trained[{{3, 5}, {5, 3}}]Create an explicit loss layer that expects the targets to be in the form of probabilities for each class:
loss = CrossEntropyLossLayer["Probabilities"]The training data should now consist of vectors of probabilities instead of symbolic classes:
trained = NetTrain[net, {{1, 2} -> {1., 0.}, {2, 3} -> {1., 0.}, {4, 2} -> {0., 1.}, {3, 1} -> {0., 1.}, {2, 2} -> {0.5, 0.5}, {3, 3} -> {0.5, 0.5}}, LossFunction -> loss]Evaluate the trained net on a set of inputs:
trained[{{3, 5}, {5, 3}}]Start with an "evaluation net" to be trained:
net = NetChain[{LinearLayer[8], Ramp, LinearLayer[4], Tanh, LinearLayer[{}]}, "Input" -> 2]Create a "loss net" that explicitly computes the loss of the evaluation net (here, the custom loss is equivalent to MeanSquaredLossLayer):
lossNet = NetGraph[<|"net" -> net, "loss" -> ThreadingLayer[(#1 - #2) ^ 2&]|>, {{"net", NetPort["Target"]} -> "loss" -> NetPort["Loss"]}]Train this net on some synthetic data, specifying that the output port named "Loss" should be interpreted as a loss:
data = Flatten@Table[{x, y} -> Exp[-(x ^ 2 + y ^ 2)], {x, -2, 2, .01}, {y, -2, 2, .01}];
trainedLossNet = NetTrain[lossNet, data, LossFunction -> "Loss"]Obtain the trained "evaluation" network using NetExtract:
trainedNet = NetExtract[trainedLossNet, "net"]Part syntax can also be used:
trainedNet = trainedLossNet[["net"]]Plot the net's output on the plane:
Plot3D[trainedNet[{x, y}], {x, -2, 2}, {y, -2, 2}, NormalsFunction -> None]Create a training net that computes both an output and multiple explicit losses:
tnet = NetGraph[{3, Tanh, {}, MeanAbsoluteLossLayer[], MeanSquaredLossLayer[]}, {1 -> 2 -> 3 -> 4, 3 -> 5, 3 -> NetPort["Output"]}, "Input" -> "Real"]This network requires an input and a target in order to produce the output and losses:
NetInitialize[tnet][<|"Input" -> 3, "Target" -> 9|>]Train using a specific output as loss, ignoring all other outputs:
trained = NetTrain[tnet, {1 -> 1, 2 -> 0, 3 -> -1, 4 -> 0, 5 -> 1}, LossFunction -> "Loss2"];Measure the loss on a single pair after training:
trained[<|"Input" -> 3, "Target" -> -1|>]Specify multiple losses to be trained jointly:
trained = NetTrain[tnet, {1 -> 1, 2 -> 0, 3 -> -1, 4 -> 0, 5 -> 1}, LossFunction -> {"Loss1", "Loss2"}];trained[<|"Input" -> 3, "Target" -> -1|>]Use NetTake to remove all but the desired output and input:
trained = NetTake[trained, {NetPort["Input"], NetPort["Output"]}]Evaluate this network on a set of inputs:
trained[Range[5]]MaxTrainingRounds (2)
Train a network such that it visits each example exactly once:
trainingData = RandomReal[1, {10000, 4}] -> RandomReal[1, {10000, 4}];
net = NetChain[{8, 4}, "Input" -> 4];
NetTrain[net, trainingData, MaxTrainingRounds -> 1]When both MaxTrainingRounds and TimeGoal are specified, the shorter of the two will be used (note that this example should be run twice to avoid the initial preprocessing overhead):
NetTrain[NetModel["LeNet"], ResourceData["MNIST"], All, MaxTrainingRounds -> 1000, TimeGoal -> 30]Method (2)
Use stochastic gradient descent with momentum to train a simple network:
data = {1 -> 2.2, 2 -> 3.8, 3 -> 6.4, 4 -> 9.1};
layer = LinearLayer[];
net = NetTrain[layer, data, Method -> "SGD"]Specify a learning rate schedule with an initial learning rate:
schedule[b_, bmax_] := 1.0 / (2 - b / bmax);
net = NetTrain[layer, data, LearningRate -> 0.3, Method -> {"SGD", "LearningRateSchedule" -> schedule}]Use regularization to prevent overfitting. Create synthetic training data based on a Gaussian curve:
data = Table[x -> Exp[-x ^ 2] + RandomVariate[NormalDistribution[0, .15]], {x, -3, 3, .2}];plot = ListPlot[List@@@data, PlotStyle -> Red]Train a net with a large number of parameters relative to the amount of training data:
net = NetChain[{150, Tanh, 150, Tanh, 1}, "Input" -> "Scalar", "Output" -> "Scalar"];
net1 = NetTrain[net, data, Method -> "ADAM"];The resulting net overfits the data, learning the noise in addition to the underlying function:
Show[Plot[net1[x], {x, -3, 3}], plot]Using the "L2Regularization" option will inject a loss proportional to the square of each weight parameter. This will tend to promote sparser weight matrices and hence mitigate overfitting:
net2 = NetTrain[net, data, Method -> {"ADAM", "L2Regularization" -> 0.01}]Show[Plot[net2[x], {x, -3, 3}], plot, PlotRange -> All]TargetDevice (1)
Train a net using the default system GPU, if a CUDA-enabled card is available:
trainingData = RandomReal[1, {10000, 4}] -> RandomReal[1, {10000, 4}];
net = NetChain[{8, 4}];
NetTrain[net, trainingData, TargetDevice -> "GPU"]If a compatible GPU is not available, a message is issued and $Failed is returned:
trainingData = RandomReal[1, {10000, 4}] -> RandomReal[1, {10000, 4}];
net = NetChain[{8, 4}];
NetTrain[net, trainingData, TargetDevice -> "GPU"]TimeGoal (1)
TrainingProgressCheckpointing (1)
Take periodic checkpoints of a convolutional network during training on the MNIST dataset:
dir = CreateDirectory[]lenet = NetChain[{
ConvolutionLayer[10, 4], Ramp, PoolingLayer[2, 2],
FlattenLayer[], 500, Ramp, 10, SoftmaxLayer[]},
"Input" -> NetEncoder[{"Image", {28, 28}, "Grayscale"}],
"Output" -> NetDecoder[{"Class", Range[0, 9]}]];trainingData = RandomSample[ResourceData["MNIST", "TrainingData"], 5000];result = NetTrain[lenet, trainingData, All, MaxTrainingRounds -> 10, TrainingProgressCheckpointing -> {"Directory", dir}]files = result["CheckpointingFiles"]Import[Last[files]]TrainingProgressFunction (1)
Use TrainingProgressFunction to append information about the state of training to a file. Create a log file:
logFile = CreateFile[]Define functions to append the batch number and loss to the log file:
appendToLog = PutAppend[<|"Batch" -> #AbsoluteBatch, "Loss" -> #RoundLoss|>, logFile]&;Define the training data and perform training:
trainingData = {#1, #2} -> {#1 + Sin[#1 * #2]}&@@@RandomReal[{-1, 1}, {50000, 2}];NetTrain[
NetChain[{1000, Tanh, 1}, "Input" -> 2],
trainingData, MaxTrainingRounds -> Quantity[10, "Seconds"],
TrainingProgressFunction -> appendToLog];logData = ReadList[logFile];
Take[logData, 3]Put the saved data into a Dataset:
dataset = Dataset[logData]Plot the loss over value over time:
ListLinePlot[dataset, PlotRange -> All, ScalingFunctions -> "Log"]TrainingProgressMeasurements (1)
Examine the final validation precision and recall for LeNet trained on FashionMNIST:
NetTrain[NetModel["LeNet"], ResourceData["FashionMNIST"], "ValidationMeasurements", ValidationSet -> Scaled[0.1], MaxTrainingRounds -> 2, TrainingProgressMeasurements -> {"Precision", "Recall"}]Animate the confusion matrix over the training period:
net = NetModel["LeNet"];
data = RandomSample[ResourceData["FashionMNIST"], 1000];
res = NetTrain[net, data, "RoundMeasurementsLists", MaxTrainingRounds -> 30, TrainingProgressMeasurements -> "ConfusionMatrixPlot"];ListAnimate[res["ConfusionMatrixPlot"]]TrainingProgressReporting (6)
Show training progress interactively during training:
NetTrain[NetModel["LeNet"], ResourceData["MNIST"], TrainingProgressReporting -> "Panel"];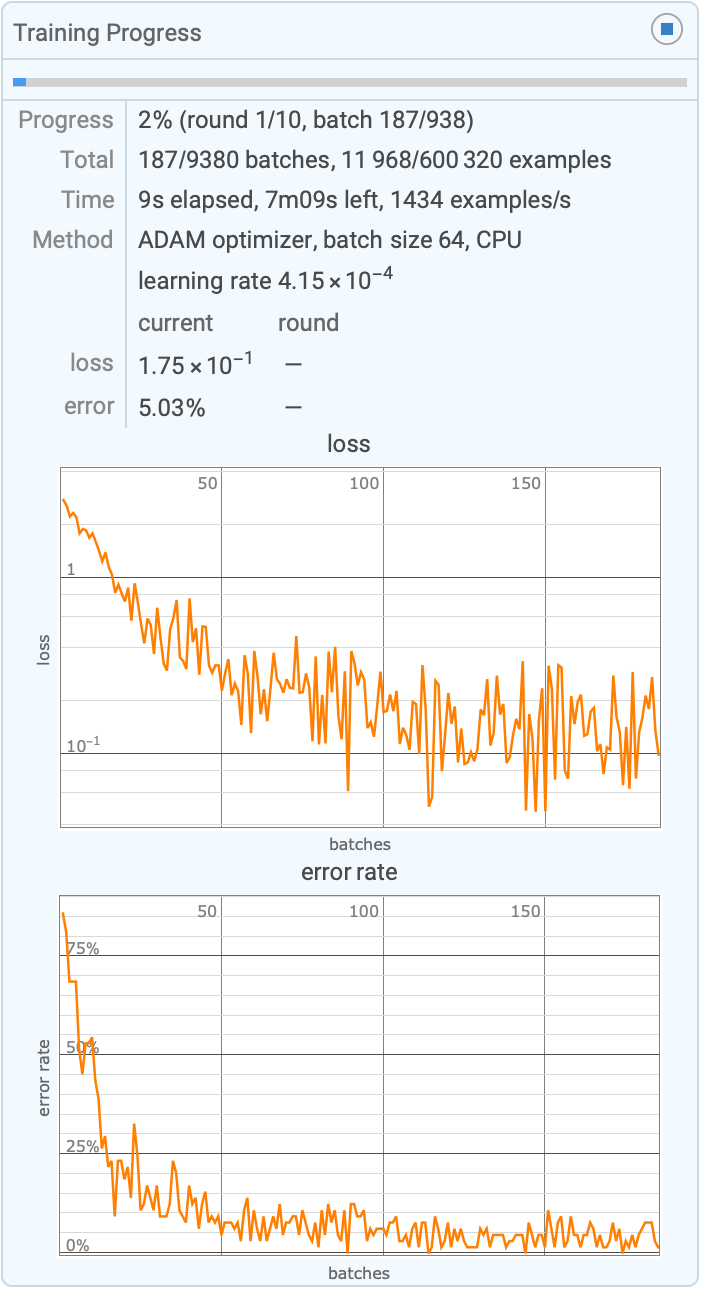
| |
Print training progress periodically during training:
NetTrain[NetModel["LeNet"], ResourceData["MNIST"], MaxTrainingRounds -> 2, TrainingProgressMeasurements -> None, TrainingProgressReporting -> "Print"];Show a simple progress indicator:
NetTrain[NetModel["LeNet"], ResourceData["MNIST"], MaxTrainingRounds -> 1, TrainingProgressReporting -> "ProgressIndicator"];[image]gradientNorms[assoc_] := BarChart[Log[Max[Abs[#]]]& /@ assoc, ChartLabels -> Automatic, BarOrigin -> Right];NetTrain[NetModel["LeNet"], ResourceData["MNIST"], MaxTrainingRounds -> 1, TrainingProgressReporting -> {Function[gradientNorms[#Gradients]], "Interval" -> Quantity[1, "Seconds"]}];[image]Write training progress information to a file:
NetTrain[NetModel["LeNet"], ResourceData["MNIST"], MaxTrainingRounds -> 2, TrainingProgressReporting -> File["tmp.csv"]];
FilePrint["tmp.csv"];
DeleteFile["tmp.csv"];NetTrain[NetModel["LeNet"], ResourceData["MNIST"], MaxTrainingRounds -> 1, TrainingProgressReporting -> None];TrainingStoppingCriterion (1)
Prevent overfitting by stopping training when the validation loss stops improving. Set up a simple net as well as some training and validation data:
net = NetChain[{8, Ramp, 1}, "Input" -> 1];
x = RandomReal[{-1, 1}, {1000, 1}];
trainingData = # -> Sin[#]& @ x;
validationData = # -> #& @ x ;Use TrainingStoppingCriterion to stop training when the validation loss stops improving:
NetTrain[net, trainingData, "LossPlot", ValidationSet -> validationData, TrainingStoppingCriterion -> "Loss"]Use TrainingStoppingCriterion to stop training if the validation loss does not improve by at least 0.001 for more than 5 rounds in a row:
NetTrain[net, trainingData, "LossPlot", ValidationSet -> validationData, TrainingStoppingCriterion -> <|"Criterion" -> "Loss", "Patience" -> 5, "AbsoluteChange" -> 0.001|>]Use a callback function to stop training. Set up the net and data:
net = NetChain[{8, Ramp, 4, SoftmaxLayer[]}];
x = RandomReal[{1.5, 3.5}, {1000}];
trainingData = Map[# -> Round[#]& , x];
validationData = Map[# -> Round[# + RandomReal[0.4]]& , x];Stop training when the validation loss is higher than 1.75:
NetTrain[net, trainingData, "LossPlot", ValidationSet -> validationData, TrainingStoppingCriterion -> Function[#ValidationLoss > 1.75]]TrainingUpdateSchedule (1)
Train a NetGANOperator by alternating updates of the discriminator and updates of the generator:
gan = NetGANOperator[{LinearLayer[{}], LinearLayer[{}]}, "Latent" -> "Real"]NetTrain[gan, <|"Sample" -> {-1, 0, 1}, "Latent" -> {-0.1, 0, 0.1}|>, TrainingUpdateSchedule -> {"Generator", "Discriminator"}]ValidationSet (1)
Provide a ValidationSet to NetTrain to prevent overfitting. Create synthetic training data based on a Gaussian curve:
data = Table[x -> Exp[-x ^ 2] + RandomVariate[NormalDistribution[0, .15]], {x, -3, 3, .2}];
Length[data]plot = ListPlot[List@@@data, PlotStyle -> Red]Train a net with a large number of parameters relative to the amount of training data:
net = NetChain[{150, Tanh, 150, Tanh, 1}, "Input" -> "Scalar", "Output" -> "Scalar"];
net1 = NetTrain[net, data, Method -> "ADAM"];The resulting net overfits the data, learning the noise in addition to the underlying function:
Show[Plot[net1[x], {x, -3, 3}], plot]Use the ValidationSet option to have NetTrain select the net that achieved the lowest validation loss during training. NetTrain will use 20% of the training data, selected at random, to create a validation set:
net2 = NetTrain[net, data, ValidationSet -> Scaled[0.2]];The result returned by NetTrain was the net that generalized best to points in the validation set, as measured by validation loss. This penalizes overfitting, as the noise present in the training data is uncorrelated with the noise present in the validation set:
Show[Plot[net2[x], {x, -3, 3}], plot]WorkingPrecision (2)
Train a net with 64-bit precision:
linear = NetTrain[LinearLayer[], {1 -> 2, 3 -> 4, 5 -> 6}, WorkingPrecision -> "Real64"]Evaluate the trained net with 64-bit precision:
linear[4, WorkingPrecision -> "Real64"]Train a net with mixed precision, taking advantage of hardware optimizations like NVIDIA Tensor Cores:
NetTrain[NetModel["VGG-16 Trained on ImageNet Competition Data"], "RandomData", WorkingPrecision -> "Mixed", TargetDevice -> "GPU"]Properties & Relations (2)
NetChain objects can be used as layers in a NetGraph:
chain = NetChain[{Ramp, LogisticSigmoid}];
NetGraph[{chain, LinearLayer[]}, {1 -> 2}]NetGraph objects with one input and one output can be used as layers inside NetChain objects:
net = NetGraph[{Ramp, LogisticSigmoid, CatenateLayer[]}, {1 -> 2, {1, 2} -> 3}];
NetChain[{ElementwiseLayer[Ramp], net}]Possible Issues (1)
By default, NetTrain uses RandomSeeding1234, which will use the same random seed to initialize the net when NetTrain is called repeatedly:
Normal@NetExtract[NetTrain[LinearLayer[{}, "Input" -> {}], {1 -> 1, 2 -> 2}, MaxTrainingRounds -> 10], "Weights"]Normal@NetExtract[NetTrain[LinearLayer[{}, "Input" -> {}], {1 -> 1, 2 -> 2}, MaxTrainingRounds -> 10], "Weights"]Use RandomSeedingAutomatic to ensure that repeated calls to NetTrain use different initializations:
Normal@NetExtract[NetTrain[LinearLayer[{}, "Input" -> {}], {1 -> 1, 2 -> 2}, MaxTrainingRounds -> 10, RandomSeeding -> Automatic], "Weights"]Normal@NetExtract[NetTrain[LinearLayer[{}, "Input" -> {}], {1 -> 1, 2 -> 2}, MaxTrainingRounds -> 10, RandomSeeding -> Automatic], "Weights"]Interactive Examples (1)
Monitor the solution while training a net to solve a least-squares problem. First generate training data:
data = Table[x -> Sin[10x] * Exp[-x ^ 2], {x, -3, 3, .02}];plotData[points_, color_] := ListLinePlot[points, PlotStyle -> color, FrameTicks -> False, PlotRangePadding -> 0.1, Frame -> True, PlotRange -> All]plot = plotData[data[[All, 2]], GrayLevel[0.7]]Create a network to fit the data:
net = NetChain[{10, Ramp, 10, Tanh, {}}, "Input" -> "Real"]Replace the default progress panel with a dynamically updated plot of the current behavior of the net:
plotSolution[net_, t_] := Show[plot, plotData[net@Range[-3, 3, .02], Red], Epilog -> Text[t, {10, 0.9}, {-1, 0}]]trained = NetTrain[net, data, MaxTrainingRounds -> Quantity[10, "Seconds"], TrainingProgressReporting -> {plotSolution[#Net, #AbsoluteBatch]&, "Interval" -> 0.1}];Plot the final net after 10 seconds of training:
plotSolution[trained, ""]Neat Examples (2)
Convert a test image into a training set, in which pixel positions (x,y) are mapped to color values (r,g,b):
img = [image];dims = Reverse@ImageDimensions[img];
rules = Flatten@MapIndexed[(2(#2 - 1.) / (dims - 1) - 1.) -> #1&, ImageData@img, {2}];RandomChoice[rules]Create a network to predict the color based on pixel position:
chain = NetChain[{100, Ramp, 250, Ramp, 10, LogisticSigmoid, 3}]trained = NetTrain[chain, rules, MaxTrainingRounds -> 100];Use the network to predict the entire original image:
{h, v} = Range[-1, 1, 2. / #]& /@ (dims);
coords = Tuples[{h, v}];
Image[Partition[trained@coords, Length[v]]]A high-dimensional ![]() embedding may provide a better prediction:
embedding may provide a better prediction:
embedding = xy Evaluate@Through[{Cos, Sin}[N[π] {1, 2, 4, 8} xy]]chain = NetChain[{FunctionLayer[embedding], 100, Ramp, 250, Ramp, 10, LogisticSigmoid, 3}]Train this alternative network:
trained = NetTrain[chain, rules, MaxTrainingRounds -> 100];Predict the entire image using this new net:
Image[Partition[trained@coords, Length[v]]]Use the association form of property argument to plot the intermediate curves fitted to a least-squares problem. First generate training data:
data = Table[x -> Sin[10x] * Exp[-x ^ 2], {x, -3, 3, .02}];plotData[points_, color_] := ListLinePlot[points, PlotStyle -> color, FrameTicks -> False, PlotRangePadding -> 0.1, Frame -> True, PlotRange -> All]plot = plotData[data[[All, 2]], GrayLevel[0.7]]Create a network to fit the data:
net = NetChain[{10, Ramp, 10, Tanh, {}}, "Input" -> "Real"];Train the net, specifying that the property to return is the net evaluated every 100 rounds:
solutions = NetTrain[net, data, <|"Property" -> Function[#Net[Range[-3, 3, .02]]], "Form" -> "List", "Interval" -> Quantity[100, "Rounds"]|>, MaxTrainingRounds -> Quantity[10, "Seconds"]];Animate the list to show the solution converging over time:
ListAnimate[Map[Show[plot, plotData[#, Red]]&]@solutions]Text
Wolfram Research (2016), NetTrain, Wolfram Language function, https://reference.wolfram.com/language/ref/NetTrain.html (updated 2025).
CMS
Wolfram Language. 2016. "NetTrain." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2025. https://reference.wolfram.com/language/ref/NetTrain.html.
APA
Wolfram Language. (2016). NetTrain. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/NetTrain.html