DistributionFitTest
DistributionFitTest[data]
检验 data 是否为正态分布.
DistributionFitTest[data,dist]
检验 data 是否服从分布 dist.
DistributionFitTest[data,dist,"property"]
返回 "property" 的值.
更多信息和选项




- DistributionFitTest 进行拟合优度假设检验,其中零假设
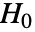 假定 data 是从一个服从分布 dist 的总体中抽取的,而备择假设
假定 data 是从一个服从分布 dist 的总体中抽取的,而备择假设 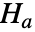 认为并非如此.
认为并非如此. - 默认情况下,返回一个概率值或者
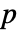 值.
值. - 一个较小的
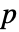 值表明 data 不可能来自 dist.
值表明 data 不可能来自 dist. - dist 可以是任何带有数值型或者符号型参数的符号式分布,也可以是一个数据集.
- data 可以是单变量 {x1,x2,…} 或者多变量 {{x1,y1,…},{x2,y2,…},…}.
- DistributionFitTest[data,dist,Automatic] 将选择对于一般备择假设而言,适用于 data 和 dist 的最有效的检验.
- DistributionFitTest[data,dist,All] 将选择适用于 data 和 dist 的所有检验.
- DistributionFitTest[data,dist,"test"] 根据 "test" 的结果报告
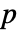 值.
值. - 许多检验使用的是所检验分布 dist 的累积分布函数
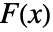 ,数据的经验累积分布函数
,数据的经验累积分布函数 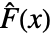 ,以及两者的差值
,以及两者的差值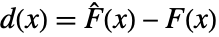 和
和 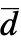 =Expectation[d(x),…]. 累积分布函数
=Expectation[d(x),…]. 累积分布函数 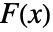 和
和 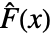 在零假设
在零假设 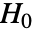 下应该是相同的.
下应该是相同的. - 下列检验可以用于单变量以及多变量分布:
-
"AndersonDarling" 分布,数据 基于 Expectation[ 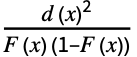 ]
]"CramerVonMises" 分布,数据 基于 Expectation[d(x)2] "JarqueBeraALM" 正态性 基于偏度和峰度 "KolmogorovSmirnov" 分布,数据 基于 ![sup_x TemplateBox[{{d, (, x, )}}, Abs]](Files/DistributionFitTest.zh/14.png "sup_x TemplateBox[{{d, (, x, )}}, Abs]")
"Kuiper" 分布,数据 基于 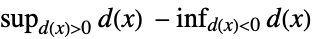
"PearsonChiSquare" 分布,数据 基于期望直方图和观测到的直方图 "ShapiroWilk" 正态性 基于分位数 "WatsonUSquare" 分布,数据 基于 Expectation[ 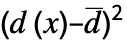 ]
] - 下列检验可用于多变量分布:
-
"BaringhausHenze" 正态性 基于经验特征函数 "DistanceToBoundary" 均匀性 基于到均匀边界的距离 "MardiaCombined" 正态性 组合的 Mardia 偏度和峰度 "MardiaKurtosis" 正态性 基于多变量峰度 "MardiaSkewness" 正态性 基于多变量偏度 "SzekelyEnergy" 数据 基于牛顿势能 - DistributionFitTest[data,dist,"property"] 可以直接给出 "property" 的值.
- 与检验结果报告相关的属性包括:
-
"AllTests" 所有适用的检验列表 "AutomaticTest" 使用 Automatic 时所选择的检验 "DegreesOfFreedom" 检验中所用的自由度 "PValue" 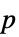 值的列表
值的列表"PValueTable" 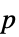 值的格式化表格
值的格式化表格"ShortTestConclusion" 检验结果的简短描述 "TestConclusion" 检验结论的描述 "TestData" 检验统计量和 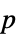 值的成对列表
值的成对列表"TestDataTable" 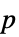 值和检验统计量的格式化表格
值和检验统计量的格式化表格"TestStatistic" 检验统计量的列表 "TestStatisticTable" 检验统计量的格式化表格 "HypothesisTestData" 返回一个 HypothesisTestData 对象 - DistributionFitTest[data,dist,"HypothesisTestData"] 返回一个 HypothesisTestData 对象 htd,该对象可用于提取其它检验结果,并利用形式 htd["property"] 获得各属性.
- 与数据分布相关的属性有:
-
"FittedDistribution" 数据的拟合分布 "FittedDistributionParameters" 数据的分布参数 - 可以给出下列选项:
-
Method Automatic 计算 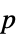 值所用的方法
值所用的方法SignificanceLevel 0.05 诊断与报告的临界值 - 对于拟合优度检验,选择一个临界值
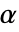 使得
使得 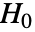 仅当
仅当 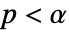 时被拒绝. 用于 "TestConclusion" 和 "ShortTestConclusion" 属性的
时被拒绝. 用于 "TestConclusion" 和 "ShortTestConclusion" 属性的 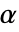 值由 SignificanceLevel 选项控制. 默认情况下,
值由 SignificanceLevel 选项控制. 默认情况下,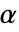 设为 0.05.
设为 0.05. - 在设置 Method->"MonteCarlo" 下,使用拟合分布在
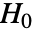 的条件下,生成与输入 si 长度相同的
的条件下,生成与输入 si 长度相同的 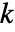 个数据集合. 然后,使用来自 DistributionFitTest[si,dist,{"TestStatistic",test}] 的 EmpiricalDistribution 估计
个数据集合. 然后,使用来自 DistributionFitTest[si,dist,{"TestStatistic",test}] 的 EmpiricalDistribution 估计 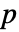 值.
值.
范例
打开所有单元关闭所有单元基本范例 (3)
创建一个 HypothesisTestData 对象,以进一步提取属性:
用 ProbabilityPlot 验证检验结果:
范围 (22)
检验 (16)
设定 Automatic 的第三个参数,以应用一般意义上较有效且适当的检验:
属性 "AutomaticTest" 可用于确定检验的类型:
这里没有足够的证据来拒绝这是 WeibullDistribution[1,2] 的良好拟合:
分别检验 MultinormalDistribution 和多元 UniformDistribution:
创建一个 HypothesisTestData 对象以重复提取属性:
从一个 HypothesisTestData 对象中提取一些属性:
数据属性 (2)
选项 (6)
应用 (12)
在 QuantilePlot 中作图比较实验和理论累积分布函数:
使用 Jarque–Bera ALM 检验与 Shapiro–Wilk 检验来评定正态性:
SmoothHistogram 与检验结果相符:
QuantilePlot 表明拟合效果相当好:
柯尔莫哥洛夫–斯米尔诺夫检验的结果与直方图一致,均表明拟合效果良好:
Kuiper 检验与 Watson ![]() 检验可以有效检验数据在圆上的均匀性:
检验可以有效检验数据在圆上的均匀性:
尝试用 LaplaceDistribution:
检验 LinearModelFit 的残差的正态性:
从 QuantilePlot 中可以看出在分布的左尾部有较大的偏差:
利用 SmoothHistogram 可视化检验统计量的分布:
获得 Anderson–Darling 检验的蒙特卡罗 ![]() 值:
值:
与 DistributionFitTest 返回的 ![]() 值比较:
值比较:
估计 Shapiro–Wilk 检验的效能,其中底层分布为 StudentTDistribution[2],检验的尺寸为 0.05,且样本大小为 35:
利用核密度估计对一个数据集进行平滑处理可以在保留数据的底层分布结构的同时,删除噪音. 下面的两个数据集是从同一个分布中创建的:
属性和关系 (16)
默认情况下,单变量数据与 NormalDistribution 比较:
默认情况下,多变量数据与 MultinormalDistribution 比较:
设置检验的大小为 0.05 将导致有5%的概率会错误否定 ![]() :
:
有效检验的 ![]() 值在
值在 ![]() 下为 UniformDistribution[{0,1}]:
下为 UniformDistribution[{0,1}]:
Jarque–Bera ALM 与 Shapiro–Wilk 检验对于小样本是最有效的:
检验方法不同,所检测的分布性质也不同. 基于某一个检验的结论并不总与其它检验所得到的结论一致:
绿色区域表示两种检验均得到正确结论. 当两种检验均产生第二类误差时,点落到红色区域. 灰色区域表示两种检验的结论不一致.
分布拟合检验仅当输入为 TimeSeries 时适用于值:
可能存在的问题 (5)
文本
Wolfram Research (2010),DistributionFitTest,Wolfram 语言函数,https://reference.wolfram.com/language/ref/DistributionFitTest.html (更新于 2015 年).
CMS
Wolfram 语言. 2010. "DistributionFitTest." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2015. https://reference.wolfram.com/language/ref/DistributionFitTest.html.
APA
Wolfram 语言. (2010). DistributionFitTest. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/DistributionFitTest.html 年