

DistributionFitTest
DistributionFitTest[data]
tests whether data is normally distributed.
DistributionFitTest[data,dist]
tests whether data is distributed according to dist.
DistributionFitTest[data,dist,"property"]
returns the value of "property".
Details and Options
- DistributionFitTest performs a goodness-of-fit hypothesis test with null hypothesis
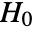 that data was drawn from a population with distribution dist and alternative hypothesis
that data was drawn from a population with distribution dist and alternative hypothesis 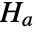 that it was not.
that it was not. - By default, a probability value or
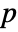 -value is returned.
-value is returned. - A small
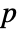 -value suggests that it is unlikely that the data came from dist.
-value suggests that it is unlikely that the data came from dist. - The dist can be any symbolic distribution with numeric and symbolic parameters or a dataset.
- The data can be univariate {x1,x2,…} or multivariate {{x1,y1,…},{x2,y2,…},…}.
- DistributionFitTest[data,dist,Automatic] will choose the most powerful test that applies to data and dist for a general alternative hypothesis.
- DistributionFitTest[data,dist,All] will choose all tests that apply to data and dist.
- DistributionFitTest[data,dist,"test"] reports the
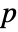 -value according to "test".
-value according to "test". - Many of the tests use the CDF
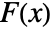 of the test distribution dist and the empirical CDF
of the test distribution dist and the empirical CDF 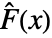 of the data as well as their difference
of the data as well as their difference 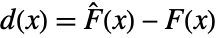 and
and 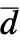 =Expectation[d(x),…]. The CDFs
=Expectation[d(x),…]. The CDFs 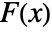 and
and 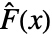 should be the same under the null hypothesis
should be the same under the null hypothesis 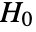 .
. - The following tests can be used for univariate or multivariate distributions:
-
"AndersonDarling" distribution, data based on Expectation[ 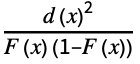 ]
]"CramerVonMises" distribution, data based on Expectation[d(x)2] "JarqueBeraALM" normality based on skewness and kurtosis "KolmogorovSmirnov" distribution, data based on ![sup_x TemplateBox[{{d, (, x, )}}, Abs]](Files/DistributionFitTest.en/14.png "sup_x TemplateBox[{{d, (, x, )}}, Abs]")
"Kuiper" distribution, data based on 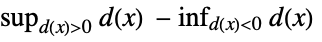
"PearsonChiSquare" distribution, data based on expected and observed histogram "ShapiroWilk" normality based on quantiles "WatsonUSquare" distribution, data based on Expectation[ 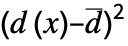 ]
] - The following tests can be used for multivariate distributions:
-
"BaringhausHenze" normality based on empirical characteristic function "DistanceToBoundary" uniformity based on distance to uniform boundaries "MardiaCombined" normality combined Mardia skewness and kurtosis "MardiaKurtosis" normality based on multivariate kurtosis "MardiaSkewness" normality based on multivariate skewness "SzekelyEnergy" data based on Newton's potential energy - DistributionFitTest[data,dist,"property"] can be used to directly give the value of "property".
- Properties related to the reporting of test results include:
-
"AllTests" list of all applicable tests "AutomaticTest" test chosen if Automatic is used "DegreesOfFreedom" the degrees of freedom used in a test "PValue" list of 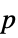 -values
-values"PValueTable" formatted table of 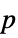 -values
-values"ShortTestConclusion" a short description of the conclusion of a test "TestConclusion" a description of the conclusion of a test "TestData" list of pairs of test statistics and 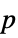 -values
-values"TestDataTable" formatted table of 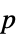 -values and test statistics
-values and test statistics"TestStatistic" list of test statistics "TestStatisticTable" formatted table of test statistics "HypothesisTestData" returns a HypothesisTestData object - DistributionFitTest[data,dist,"HypothesisTestData"] returns a HypothesisTestData object htd that can be used to extract additional test results and properties using the form htd["property"].
- Properties related to the data distribution include:
-
"FittedDistribution" fitted distribution of data "FittedDistributionParameters" distribution parameters of data - The following options can be given:
-
Method Automatic the method to use for computing 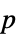 -values
-valuesSignificanceLevel 0.05 cutoff for diagnostics and reporting - For a test for goodness of fit, a cutoff
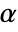 is chosen such that
is chosen such that 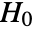 is rejected only if
is rejected only if 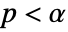 . The value of
. The value of 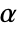 used for the "TestConclusion" and "ShortTestConclusion" properties is controlled by the SignificanceLevel option. By default,
used for the "TestConclusion" and "ShortTestConclusion" properties is controlled by the SignificanceLevel option. By default, 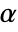 is set to 0.05.
is set to 0.05. - With the setting Method->"MonteCarlo",
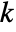 datasets of the same length as the input si are generated under
datasets of the same length as the input si are generated under 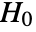 using the fitted distribution. The EmpiricalDistribution from DistributionFitTest[si,dist,{"TestStatistic",test}] is then used to estimate the
using the fitted distribution. The EmpiricalDistribution from DistributionFitTest[si,dist,{"TestStatistic",test}] is then used to estimate the 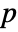 -value.
-value.
Examples
open all close allBasic Examples (3)
data = RandomVariate[NormalDistribution[], 2500];DistributionFitTest[data]Create a HypothesisTestData object for further property extraction:
ℋ = DistributionFitTest[data, Automatic, "HypothesisTestData"];ℋ["TestDataTable", All]Compare the histogram of the data to the PDF of the test distribution:
Show[Histogram[data, Automatic, "ProbabilityDensity"], Plot[PDF[ℋ["FittedDistribution"], x], {x, -5, 5}, PlotStyle -> Thick]]Test the fit of a set of data to a particular distribution:
data = RandomVariate[𝒹 = ParetoDistribution[1, 2], 100];Extract the Anderson–Darling test table:
DistributionFitTest[data, 𝒹, {"TestDataTable", "AndersonDarling"}]Verify the test results with ProbabilityPlot:
ProbabilityPlot[data, 𝒹]Test data for goodness of fit to a multivariate distribution:
data = RandomVariate[𝒟 = BinormalDistribution[.5], 100];ℋ = DistributionFitTest[data, 𝒟, "HypothesisTestData"];ℋ["TestDataTable", "KolmogorovSmirnov"]Plot the marginal PDFs of the test distribution against the data to confirm the test results:
Table[Show[SmoothHistogram[data[[All, i]], PlotStyle -> {Orange, Dashed}, PlotRange -> {0, .4}], Plot[PDF[MarginalDistribution[𝒟, i], x], {x, -4, 4}]], {i, 2}]Scope (22)
Testing (16)
data1 = RandomVariate[NormalDistribution[], 500];
data2 = RandomVariate[StudentTDistribution[5], 500];The ![]() -values for the normally distributed data are typically large:
-values for the normally distributed data are typically large:
DistributionFitTest[data1]The ![]() -values for data that is not normally distributed are typically small:
-values for data that is not normally distributed are typically small:
DistributionFitTest[data2]Set the third argument to Automatic to apply a generally powerful and appropriate test:
data = RandomVariate[NormalDistribution[], 10^4];DistributionFitTest[data]The property "AutomaticTest" can be used to determine which test was chosen:
DistributionFitTest[data, Automatic, "AutomaticTest"]Test whether data fits a particular distribution:
data = RandomVariate[WeibullDistribution[1, 2], 10^3];DistributionFitTest[data, WeibullDistribution[1, 2]]There is insufficient evidence to reject a good fit to a WeibullDistribution[1,2]:
Show[Histogram[data, Automatic, "ProbabilityDensity"], Plot[PDF[WeibullDistribution[1, 2], x], {x, 0, 12}, PlotStyle -> Thick]]Test for goodness of fit to a derived distribution:
𝒟 = MixtureDistribution[{1 / 2, 1 / 2}, {NormalDistribution[-1, 2], ExponentialDistribution[1]}];data1 = RandomVariate[𝒟, 10^4];
data2 = RandomVariate[NormalDistribution[], 10^4];Show[Histogram[data1, Automatic, "PDF"], Plot[PDF[𝒟, x], {x, -5, 5}, PlotRange -> All, Axes -> {True, False}, PlotStyle -> Thick]]The ![]() -value is large for the mixture data compared to data not drawn from the mixture:
-value is large for the mixture data compared to data not drawn from the mixture:
DistributionFitTest[data1, 𝒟]DistributionFitTest[data2, 𝒟]Test for goodness of fit for quantity data:
data = QuantityArray[RandomVariate[NormalDistribution[100, 6], 100], "Centimeters"]DistributionFitTest[data, NormalDistribution[μ, σ]]Check goodness-of-fit for a specific distribution:
DistributionFitTest[data, NormalDistribution[Quantity[1, "Meters"], Quantity[6, "Centimeters"]]]Test for goodness of fit to a formula-based distribution:
𝒟 = ProbabilityDistribution[Piecewise[{{x ^ 2 / 9, 0 < x ≤ 3}}], {x, -Infinity, Infinity}];data = BlockRandom[SeedRandom[2];RandomVariate[𝒟, 50]];Show[SmoothHistogram[data, PlotStyle -> Dotted], Plot[PDF[𝒟, x], {x, -5, 5}, PlotRange -> All, Axes -> {True, False}, PlotStyle -> {Orange, Thick}]]DistributionFitTest[data, 𝒟]Unspecified parameters will be estimated from the data:
data = RandomVariate[NormalDistribution[1, 2], 10^3];The ![]() -value is dependent on which parameters were estimated:
-value is dependent on which parameters were estimated:
Table[DistributionFitTest[data, NormalDistribution@@i], {i, {{1, 2}, {1, σ}, {μ, 2}, {μ, σ}}}]Test some data for multivariate normality:
data1 = RandomVariate[BinormalDistribution[.5], 10^3];
data2 = RandomVariate[MultivariateTDistribution[IdentityMatrix[2], 15], 10^3];The ![]() -values for normally distributed data are typically large compared to non-normal data:
-values for normally distributed data are typically large compared to non-normal data:
Table[DistributionFitTest[data], {data, {data1, data2}}]Test some data for goodness of fit to a particular multivariate distribution:
data = RandomVariate[UniformDistribution[{{0, 1}, {0, 1}}], 10^3];Test a MultinormalDistribution and multivariate UniformDistribution, respectively:
Table[DistributionFitTest[data, 𝒟], {𝒟, {Automatic, UniformDistribution[{{0, 1}, {0, 1}}]}}]Compare the distributions of two datasets:
data1 = RandomVariate[NormalDistribution[], 10^3];
data2 = RandomVariate[NormalDistribution[], 10^3];DistributionFitTest[data1, data2]The sample sizes need not be equal:
data3 = RandomVariate[NormalDistribution[], 10^2];DistributionFitTest[data1, data3]Compare the distributions of two multivariate datasets:
data1 = RandomVariate[BinormalDistribution[-.99], 10^2];
data2 = RandomVariate[BinormalDistribution[-.99], 10^2];
data3 = RandomVariate[BinormalDistribution[.99], 10^2];The ![]() -values for equally distributed data are large compared to unequally distributed data:
-values for equally distributed data are large compared to unequally distributed data:
DistributionFitTest[data1, data2]DistributionFitTest[data1, data3]Perform a particular goodness-of-fit test:
data = RandomVariate[NormalDistribution[], 10^4];DistributionFitTest[data, Automatic, "AndersonDarling"]Any number of tests can be performed simultaneously:
DistributionFitTest[data, Automatic, {"AndersonDarling", "KolmogorovSmirnov"}]Perform all tests, appropriate to the data and distribution, simultaneously:
data = RandomVariate[NormalDistribution[], 10^4];DistributionFitTest[data, Automatic, All]Use the property "AllTests" to identify which tests were used:
DistributionFitTest[data, Automatic, "AllTests"]Create a HypothesisTestData object for repeated property extraction:
data = RandomVariate[NormalDistribution[], 10^4];ℋ = DistributionFitTest[data, Automatic, "HypothesisTestData"];The properties available for extraction:
ℋ["Properties"]Extract some properties from a HypothesisTestData object:
data = RandomVariate[NormalDistribution[], 10^4];ℋ = DistributionFitTest[data, NormalDistribution[], "HypothesisTestData"];The ![]() -value and test statistic from a Cramér–von Mises test:
-value and test statistic from a Cramér–von Mises test:
ℋ["PValue", "CramerVonMises"]ℋ["TestStatistic", "CramerVonMises"]Extract any number of properties simultaneously:
data = RandomVariate[NormalDistribution[], 100];ℋ = DistributionFitTest[data, Automatic, "HypothesisTestData"];The results from the Anderson–Darling ![]() -value and test statistic:
-value and test statistic:
ℋ[{{"PValue", "AndersonDarling"}, {"TestStatistic", "AndersonDarling"}}]Data Properties (2)
Obtain the fitted distribution when parameters have been unspecified:
data = RandomVariate[NormalDistribution[], 10^4];ℋ = DistributionFitTest[data, NormalDistribution[μ, σ], "HypothesisTestData"];Extract the parameters from the fitted distribution:
ℋ["FittedDistributionParameters"]Plot the PDF of the fitted distribution against the data:
𝒟 = ℋ["FittedDistribution"]Show[Plot[PDF[𝒟, x], {x, -4, 4}], SmoothHistogram[data, PlotStyle -> {Dotted, Orange}]]Confirm the fit with a goodness-of-fit test:
ℋ["KolmogorovSmirnov"]The test distribution is returned when the parameters have been specified:
data = RandomVariate[NormalDistribution[], 10^4];𝒟 = DistributionFitTest[data, NormalDistribution[0, 1], "FittedDistribution"]Visually compare the data to the fitted distribution:
Show[Histogram[data, Automatic, "ProbabilityDensity"], Plot[PDF[𝒟, x], {x, -4, 4}, PlotStyle -> Thick]]Reporting (4)
Tabulate the results from a selection of tests:
data = RandomVariate[NormalDistribution[], 10^3];ℋ = DistributionFitTest[data, Automatic, "HypothesisTestData"];ℋ["TestDataTable"]A full table of all appropriate test results:
ℋ["TestDataTable", All]A table of selected test results:
ℋ["TestDataTable", {"AndersonDarling", "PearsonChiSquare"}]Retrieve the entries from a test table for customized reporting:
data = BlockRandom[SeedRandom[1];RandomVariate[NormalDistribution[], 10^3]];ℋ = DistributionFitTest[data, Automatic, "HypothesisTestData"];res = ℋ["TestData", All];The ![]() -values are above 0.05, so there is not enough evidence to reject normality at that level:
-values are above 0.05, so there is not enough evidence to reject normality at that level:
Show[BarChart[res[[All, 2]], ChartLabels -> Placed[ℋ["AllTests"], Center], BarOrigin -> Left], Graphics[Line[{{.05, 0}, {.05, 11.5}}]]]Tabulate ![]() -values for a test or group of tests:
-values for a test or group of tests:
data = RandomVariate[NormalDistribution[], 10^4];ℋ = DistributionFitTest[data, Automatic, "HypothesisTestData"];ℋ["PValueTable", "CramerVonMises"]ℋ["PValue", "CramerVonMises"]A table of ![]() -values from all appropriate tests:
-values from all appropriate tests:
ℋ["PValueTable", All]A table of ![]() -values from a subset of tests:
-values from a subset of tests:
ℋ["PValueTable", {"AndersonDarling", "CramerVonMises", "WatsonUSquare"}]Report the test statistic from a test or group of tests:
data = RandomVariate[CauchyDistribution[1, 2], 10^3];ℋ = DistributionFitTest[data, CauchyDistribution[1, 2], "HypothesisTestData"];ℋ["TestStatisticTable"]The test statistic from the table:
ℋ["TestStatistic"]A table of test statistics from all appropriate tests:
ℋ["TestStatisticTable", All]Options (6)
Method (4)
Use Monte Carlo-based methods, or choose the fastest method automatically:
data = RandomVariate[NormalDistribution[], 100];DistributionFitTest[data, NormalDistribution[], "CramerVonMises", Method -> "MonteCarlo"]DistributionFitTest[data, NormalDistribution[], "CramerVonMises", Method -> Automatic]Set the number of samples to use for Monte Carlo-based methods:
data = RandomVariate[NormalDistribution[], 100];pts = Table[{i, DistributionFitTest[data, NormalDistribution[], "CramerVonMises", Method -> {"MonteCarlo", "MonteCarloSamples" -> i}]}, {i, Range[5, 1000, 50]}];The Monte Carlo estimate converges to the true ![]() -value with increasing samples:
-value with increasing samples:
pval = DistributionFitTest[data, NormalDistribution[], "CramerVonMises"];Show[ListLinePlot[pts, PlotRange -> {0, 1}, FrameLabel -> {"Samples", "P-Value"}, Frame -> True, AxesOrigin -> {0, 0}], Graphics[{Dashed, Line[{{0, pval}, {1000, pval}}]}]]Set the random seed used in Monte Carlo-based methods:
data = RandomVariate[NormalDistribution[], 100];pts = Table[{i, DistributionFitTest[data, NormalDistribution[], "CramerVonMises", Method -> {"MonteCarlo", "RandomSeed" -> i}]}, {i, Range[1, 10]}];The seed affects the state of the generator and has some effect on the resulting ![]() -value:
-value:
pval = DistributionFitTest[data, NormalDistribution[], "CramerVonMises"];Show[ListLinePlot[pts, PlotRange -> {Min[pts[[All, 2]]], Max[pts[[All, 2]]]}, FrameLabel -> {"Seed", "P-Value"}, Frame -> True, AxesOrigin -> {0, 0}], Graphics[{Dashed, Line[{{0, pval}, {100, pval}}]}]]Monte Carlo simulations generate many test statistics under ![]() :
:
mcSamp = 250;seed = 9;n = 50;𝒟 = NormalDistribution[μ, σ];data = RandomVariate[NormalDistribution[1, 2], n];ℋ = DistributionFitTest[data, 𝒟, "HypothesisTestData", Method -> {"MonteCarlo", "MonteCarloSamples" -> mcSamp, "RandomSeed" -> seed}];simDat = BlockRandom[SeedRandom[seed];RandomVariate[ℋ["FittedDistribution"], {mcSamp, n}]];testDist = DistributionFitTest[#, 𝒟, "TestStatistic"]& /@ simDat;The estimated distribution of the test statistics under ![]() :
:
SmoothHistogram[testDist, Filling -> Axis]The empirical estimate of the ![]() -value agrees with the Monte Carlo estimate:
-value agrees with the Monte Carlo estimate:
Probability[t > ℋ["TestStatistic"], tEmpiricalDistribution[testDist]]ℋ["PValue"]SignificanceLevel (2)
By default, a significance level of 0.05 is used:
data = BlockRandom[SeedRandom[234];RandomVariate[NormalDistribution[0, 1], 100]];DistributionFitTest[data, Automatic, "TestConclusion"]//TraditionalFormSet the significance level to 0.001:
DistributionFitTest[data, Automatic, "TestConclusion", SignificanceLevel -> 0.001]//TraditionalFormThe significance level is also used for "ShortTestConclusion":
data = BlockRandom[SeedRandom[234];RandomVariate[NormalDistribution[0, 1], 100]];ℋ1 = DistributionFitTest[data, Automatic, "HypothesisTestData", SignificanceLevel -> .05];ℋ2 = DistributionFitTest[data, Automatic, "HypothesisTestData", SignificanceLevel -> .001];ℋ1["ShortTestConclusion"]ℋ2["ShortTestConclusion"]Applications (12)
Analyze whether a dataset is drawn from a normal distribution:
data = {87, 91, 97 , 80, 71, 86, 72, 93, 83, 73, 76};
𝒹 = NormalDistribution[82, 9];Perform a series of goodness-of-fit tests:
ℋ = DistributionFitTest[data, 𝒹, "HypothesisTestData"];ℋ["TestDataTable"]Visually compare the empirical and theoretical CDFs in a QuantilePlot:
QuantilePlot[data, 𝒹]Visually compare the empirical CDF to that of the test distribution:
Plot[{CDF[ℋ["FittedDistribution"], x], CDF[EmpiricalDistribution[data], x]}//Evaluate, {x, 50, 110}, Exclusions -> None, Filling -> {1 -> {2}}, Frame -> True]Determine whether snowfall accumulations in Buffalo are normally distributed:
snow = ExampleData[{"Statistics", "BuffaloSnow"}];ℋ = DistributionFitTest[snow, Automatic, "HypothesisTestData"];Use the Jarque–Bera ALM test and Shapiro–Wilk test to assess normality:
ℋ["TestDataTable", {"JarqueBeraALM", "ShapiroWilk"}]The SmoothHistogram agrees with the test results:
Show[SmoothHistogram[snow, PlotStyle -> {Dotted, Orange}], Plot[PDF[ℋ["FittedDistribution"], x], {x, 0, 150}]]The QuantilePlot suggests a reasonably good fit:
QuantilePlot[snow, ℋ["FittedDistribution"]]Use a goodness-of-fit test to verify the fit suggested by visualization such as a histogram:
𝒹 = BetaDistribution[2, 2];
BlockRandom[SeedRandom[1];data = RandomVariate[𝒹, 10000]];Show[Histogram[data, Automatic, "ProbabilityDensity"], Plot[PDF[𝒹, x], {x, 0, 1}, PlotStyle -> Thick]]The Kolmogorov–Smirnov test agrees with the good fit suggested in the histogram:
DistributionFitTest[data, 𝒹, "KolmogorovSmirnov"]Test whether the absolute magnitudes of the 100 brightest stars are normally distributed:
data = EntityClass["Star", "StarBrightest100"]["AbsoluteMagnitude"];ℋ = DistributionFitTest[data, NormalDistribution[a, b], "HypothesisTestData"];The value of the statistic and p-value for the automatic test:
ℋ["TestDataTable", Automatic]Show[SmoothHistogram[data, PlotStyle -> {Dotted, Orange}, PlotRange -> {0, .15}], Plot[PDF[ℋ["FittedDistribution"], x], {x, -15, 10}]]Test whether multivariate data is uniformly distributed over a box:
ExampleData[{"Statistics", "UgandaVolcanoes"}, "LongDescription"]data = ExampleData[{"Statistics", "UgandaVolcanoes"}];box1 = {{320, 2760}, {970, 4150}};
box2 = {{1100, 1800}, {1600, 3000}};Show[ListPlot[data, PlotRange -> {{200, 2800}, {500, 5000}}], Graphics[{EdgeForm[Orange], Opacity[0], Rectangle@@Transpose[box1]}], Graphics[{EdgeForm[Gray], Opacity[0], Rectangle@@Transpose[box2]}], AspectRatio -> 1, ImageSize -> Medium]Use the distance-to-boundary test:
DistributionFitTest[data, UniformDistribution[box1], {"TestDataTable", "DistanceToBoundary"}]DistributionFitTest[Pick[data, (Boole[1100 ≤ #1[[1]] ≤ 1800 && 1600 ≤ #1[[2]] ≤ 3000]&) /@ data, 1], UniformDistribution[box2], {"TestDataTable", "DistanceToBoundary"}]Use Szekely's energy test to compare two multivariate datasets:
ExampleData[{"Statistics", "SwissBankNotes"}, "ColumnDescriptions"]data = ExampleData[{"Statistics", "SwissBankNotes"}];counterfeit = Pick[data[[All, 1 ;; 6]], data[[All, -1]], 1];
genuine = Pick[data[[All, 1 ;; 6]], data[[All, -1]], 0];The distributions for measures of counterfeit and genuine notes are significantly different:
DistributionFitTest[counterfeit, genuine, {"TestDataTable", "SzekelyEnergy"}]Visually compare the marginal distributions to determine the origin of the discrepancy:
Table[SmoothHistogram[{counterfeit[[All, i]], genuine[[All, i]]}, PlotLabel -> Row[{"Measure:", i}]], {i, 6}]Test whether data is uniformly distributed on a unit circle:
Subscript[rad, 1] = {1.77, 3.63, 5.21, 5.54, 0.17, 6.26, 2.84, 2.1, 5.73, 5.13, 2.30, 4.13, 3.56, 0.6, 0.99};Subscript[rad, 2] = {0.96, 0.83, 1.18, 0.97, 1.92, 1.99, 0.94, 0.89, 0.98, 1.33, 0.86, 0.58, 0.73, 1.85, 2.3};Kuiper's test and the Watson ![]() test are useful for testing uniformity on a circle:
test are useful for testing uniformity on a circle:
Table[DistributionFitTest[i, UniformDistribution[{0, 2 Pi}], {"TestDataTable", {"Kuiper", "WatsonUSquare"}}], {i, {Subscript[rad, 1], Subscript[rad, 2]}}]The first dataset is randomly distributed, the second is clustered:
Table[Show[Graphics[{StandardGray, Circle[]}], ListPlot[{Cos[#], Sin[#]}& /@ i, PlotStyle -> PointSize[.05]]], {i, {Subscript[rad, 1], Subscript[rad, 2]}}]Determine if a model is appropriate for day-to-day point changes in the S&P 500 index:
sp500 = FinancialData["SP500", All];
data = Log[Ratios[sp500]]The histogram suggests a heavy-tailed, symmetric distribution:
Histogram[data, PlotRange -> {{-.05, .05}, All}]Try a LaplaceDistribution:
ℋ = DistributionFitTest[data, LaplaceDistribution[a, b], "HypothesisTestData"];ℋ["TestDataTable", All]For very large datasets, small deviations from the test distribution are readily detected:
Show[SmoothHistogram[data, PlotStyle -> Orange, PlotRange -> {0, 2}], Plot[PDF[ℋ["FittedDistribution"], x], {x, Min[data], Max[data]}]]Test the residuals from a LinearModelFit for normality:
data = ExampleData[{"Statistics", "OldFaithful"}];lm = LinearModelFit[data, x, x];ℋ = DistributionFitTest[res = lm["FitResiduals"], Automatic, "HypothesisTestData"];The Shapiro–Wilk test suggests that the residuals are not normally distributed:
ℋ["TestDataTable", "ShapiroWilk"]The QuantilePlot suggests large deviations in the left tail of the distribution:
QuantilePlot[res, ℋ["FittedDistribution"]]Simulate the distribution of a test statistic to obtain a Monte Carlo ![]() -value:
-value:
mcSamples = RandomVariate[𝒹 = NormalDistribution[], {2500, 25}];Subscript[ℋ, MC] = DistributionFitTest[#, 𝒹, "HypothesisTestData"]& /@ mcSamples;T = Table[i["TestStatistic", "AndersonDarling"], {i, Subscript[ℋ, MC]}];Visualize the distribution of the test statistic using SmoothHistogram:
SmoothHistogram[T, PlotLabel -> "A-D Distribution: n = 25", Filling -> Axis]Obtain the Monte Carlo ![]() -value from an Anderson–Darling test:
-value from an Anderson–Darling test:
data = RandomReal[𝒹, 25];ℋ = DistributionFitTest[data, 𝒹, "HypothesisTestData"];t = ℋ["TestStatistic", "AndersonDarling"]Subscript[P, MC] = Length[Cases[T, x_ /; x > t]] / Length[T]//NCompare with the ![]() -value returned by DistributionFitTest:
-value returned by DistributionFitTest:
ℋ["PValue", "AndersonDarling"] - Subscript[P, MC]Obtain an estimate of the power for a hypothesis test:
data = Table[RandomVariate[StudentTDistribution[2], {500, i}], {i, n = {5, 7, 10, 15, 20, 25, 30, 40, 50}}];ℋ = Table[DistributionFitTest[data[[i, j]], NormalDistribution[], "ShapiroWilk"], {i, Length[data]}, {j, Length[data[[i]]]}];pC = Interpolation[Transpose[{n, Table[Probability[x ≤ 0.05, xi], {i, ℋ}]}], InterpolationOrder -> 1];Visualize the approximate power curve:
Plot[pC[x], {x, 5, 50}, PlotRange -> {0, 1}, Ticks -> {n, Automatic}, AxesOrigin -> {0, 0}]Estimate the power of the Shapiro–Wilk test when the underlying distribution is a StudentTDistribution[2], the test size is 0.05, and the sample size is 35:
pC[35]//NSmoothing a dataset using kernel density estimation can remove noise while preserving the structure of the underlying distribution of the data. Here two datasets are created from the same distribution:
data1 = BlockRandom[SeedRandom[1];RandomVariate[NormalDistribution[], 100]];
data2 = BlockRandom[SeedRandom[14];RandomVariate[NormalDistribution[], 100]];The unsmoothed data provides a noisy estimate of the underlying distributions:
Plot[Evaluate[CDF[EmpiricalDistribution[#], x]& /@ {data1, data2}], {x, -5, 5}, Exclusions -> None]Noise would lead to committing a type I error:
DistributionFitTest[data1, data2]𝒟 = SmoothKernelDistribution[data2];Plot[{CDF[EmpiricalDistribution[data1], x], CDF[𝒟, x]}, {x, -5, 5}, Exclusions -> None]Smoothing reduces the noise and results in a correct conclusion at the 5% level:
DistributionFitTest[data1, 𝒟]Properties & Relations (16)
By default, univariate data is compared to a NormalDistribution:
data = RandomVariate[CauchyDistribution[0, 1], 10];ℋ1 = DistributionFitTest[data, Automatic, "HypothesisTestData"];
ℋ2 = DistributionFitTest[data, NormalDistribution[μ, σ], "HypothesisTestData"];The parameters of the distribution are estimated from the data:
{ℋ1["FittedDistribution"], ℋ2["FittedDistribution"]}Multivariate data is compared to a MultinormalDistribution by default:
data = RandomVariate[BinormalDistribution[.5], 10];ℋ1 = DistributionFitTest[data, Automatic, "HypothesisTestData"];
ℋ2 = DistributionFitTest[data, MultinormalDistribution[{μ1, μ2}, IdentityMatrix[2]], "HypothesisTestData"];Unspecified parameters of the distribution are estimated from the data:
{ℋ1["FittedDistribution"], ℋ2["FittedDistribution"]}//TraditionalFormMaximum likelihood estimates are used for unspecified parameters of the test distribution:
data = RandomVariate[ExponentialDistribution[3], 10^3];ℋ = DistributionFitTest[data, ExponentialDistribution[λ], "FittedDistribution"]EstimatedDistribution[data, ExponentialDistribution[λ]]The ![]() -value suggests the expected proportion of false positives (type I errors):
-value suggests the expected proportion of false positives (type I errors):
data = RandomVariate[NormalDistribution[], {1000, 10}];pvals = Table[DistributionFitTest[i, NormalDistribution[], "CramerVonMises"], {i, data}];Setting the size of a test to 0.05 results in an erroneous rejection of ![]() about 5% of the time:
about 5% of the time:
Probability[x ≤ 0.05, xpvals]//NType II errors arise when ![]() is not rejected, given it is false:
is not rejected, given it is false:
data = RandomVariate[CauchyDistribution[0, 1], {1000, 25}];ℋs = Table[DistributionFitTest[i, NormalDistribution[a, b], "AndersonDarling"], {i, data}];Increasing the size of the test lowers the type II error rate:
ListLinePlot[Table[{sz, Probability[x > sz, xℋs]//N}, {sz, Range[0.001, .25, .01]}], AxesLabel -> {"Size", "Type II Error"}]The ![]() -value for a valid test has a UniformDistribution[{0,1}] under
-value for a valid test has a UniformDistribution[{0,1}] under ![]() :
:
data = RandomVariate[NormalDistribution[], {1000, 25}];tests = {"AndersonDarling", "CramerVonMises", "KolmogorovSmirnov", "Kuiper"};p = Table[DistributionFitTest[i, NormalDistribution[], tests], {i, data}]//Transpose;Table[Histogram[p[[i]], Automatic, "ProbabilityDensity", PlotLabel -> tests[[i]]], {i, 4}]Verify the uniformity using the Kolmogorov–Smirnov test:
TableForm[Table[{tests[[i]], Round[DistributionFitTest[p[[i]], UniformDistribution[{0, 1}], "KolmogorovSmirnov"], .001]}, {i, 4}]]The power of each test is the probability of rejecting ![]() when it is false:
when it is false:
data = RandomVariate[CauchyDistribution[0, 1], {1000, 25}];tests = {"AndersonDarling", "CramerVonMises", "JarqueBeraALM", "KolmogorovSmirnov", "Kuiper", "PearsonChiSquare", "ShapiroWilk", "WatsonUSquare"};p = Table[DistributionFitTest[i, Automatic, tests], {i, data}]//Transpose;Under these conditions, the Pearson ![]() test has the lowest power:
test has the lowest power:
N[Table[{tests[[i]], Probability[x ≤ 0.05, xp[[i]]]}, {i, Length[tests]}]]//TableFormThe power of each test decreases with sample size:
data = RandomVariate[CauchyDistribution[0, 1], {500, 10}];tests = {"AndersonDarling", "CramerVonMises", "JarqueBeraALM", "KolmogorovSmirnov", "Kuiper", "PearsonChiSquare", "ShapiroWilk", "WatsonUSquare"};p = Table[DistributionFitTest[i, Automatic, tests], {i, data}]//Transpose;Some tests perform better than others with small sample sizes:
N[Table[{tests[[i]], Probability[x ≤ 0.05, xp[[i]]]}, {i, Length[tests]}]]//TableFormSome tests are more powerful than others for detecting differences in location:
data = RandomVariate[NormalDistribution[1, 1], {500, 25}];tests = {"AndersonDarling", "CramerVonMises", "KolmogorovSmirnov", "Kuiper", "PearsonChiSquare", "WatsonUSquare"};p = Table[DistributionFitTest[i, NormalDistribution[0, σ], tests], {i, data}]//Transpose;N[Table[{tests[[i]], Probability[x ≤ 0.05, xp[[i]]]}, {i, Length[tests]}]]//TableFormSome tests are more powerful than others for detecting differences in scale:
data = RandomVariate[NormalDistribution[1, 1], {500, 25}];tests = {"AndersonDarling", "CramerVonMises", "KolmogorovSmirnov", "Kuiper", "PearsonChiSquare", "WatsonUSquare"};p = Table[DistributionFitTest[i, NormalDistribution[μ, 2], tests], {i, data}]//Transpose;N[Table[{tests[[i]], Probability[x ≤ 0.05, xp[[i]]]}, {i, Length[tests]}]]//TableFormThe Pearson ![]() test requires large sample sizes to have high power:
test requires large sample sizes to have high power:
data1 = RandomVariate[StudentTDistribution[2], {500, 25}];
data2 = RandomVariate[StudentTDistribution[2], {500, 50}];
data3 = RandomVariate[StudentTDistribution[2], {500, 100}];p1 = Table[DistributionFitTest[i, Automatic, "PearsonChiSquare"], {i, data1}];
p2 = Table[DistributionFitTest[i, Automatic, "PearsonChiSquare"], {i, data2}];
p3 = Table[DistributionFitTest[i, Automatic, "PearsonChiSquare"], {i, data3}];{Probability[x ≤ 0.05, xp1], Probability[x ≤ 0.05, xp2], Probability[x ≤ 0.05, xp3]}//NSome tests perform better than others when testing normality:
data = RandomVariate[StudentTDistribution[2], {500, 100}];tests = {"AndersonDarling", "CramerVonMises", "JarqueBeraALM", "KolmogorovSmirnov", "Kuiper", "PearsonChiSquare", "ShapiroWilk", "WatsonUSquare"};p = Table[DistributionFitTest[i, NormalDistribution[a, b], tests], {i, data}]//Transpose;The Jarque–Bera ALM and Shapiro–Wilk tests are the most powerful for small samples:
N[Table[{tests[[i]], Probability[x ≤ 0.05, xp[[i]]]}, {i, Length[tests]}]]//TableFormTests designed for the composite hypothesis of normality ignore specified parameters:
data = RandomVariate[NormalDistribution[], 100];ℋ1 = DistributionFitTest[data, NormalDistribution[1, 10], "ShapiroWilk"]ℋ2 = DistributionFitTest[data, NormalDistribution[10, 1], "ShapiroWilk"]Different tests examine different properties of the distribution. Conclusions based on a particular test may not always agree with those based on another test:
data = RandomVariate[StudentTDistribution[3], {100, 50}];tests = {"Kuiper", "CramerVonMises", "KolmogorovSmirnov", "PearsonChiSquare"};pvs = Table[(DistributionFitTest[#1, Automatic, i]&) /@ data, {i, tests}];α = 0.2;conclusions[α_] := Show[Graphics[{Opacity[.5], Lighter[Purple], Rectangle[{0, 0}, {α, α}]}], Graphics[{Opacity[.5], Orange, Rectangle[{α, α}, {1, 1}]}], Graphics[{Opacity[.1], Gray, Rectangle[{0, α}, {α, 1}]}], Graphics[{Opacity[.1], Gray, Rectangle[{α, 0}, {1, α}]}]];The green region represents a correct conclusion by both tests. Points fall in the red region when a type II error is committed by both tests. The gray region shows where the tests disagree:
MapThread[Show[conclusions[α], ListPlot[Transpose[{pvs[[#1]], pvs[[#2]]}], AspectRatio -> 1], Frame -> True, FrameLabel -> {tests[[#1]], tests[[#2]]}]&, {{1, 1, 1, 2, 2, 3}, {2, 3, 4, 3, 4, 4}}]Estimating parameters prior to testing affects the distribution of the test statistic:
data = RandomVariate[NormalDistribution[], {1000, 35}];ℋ1 = Table[DistributionFitTest[i, NormalDistribution[μ, σ], "TestData"], {i, data}]//Transpose;The distribution of the test statistics and resulting ![]() -values under
-values under ![]() :
:
{Histogram[ℋ1[[1]], Automatic, "PDF", PlotLabel -> "Test Statistics"], Histogram[ℋ1[[2]], Automatic, "PDF", PlotLabel -> "P-Values"]}ℋ2 = Table[DistributionFitTest[i, EstimatedDistribution[i, NormalDistribution[μ, σ]], "TestData"], {i, data}]//Transpose;Failing to account for the estimation leads to an overestimate of ![]() -values:
-values:
{Histogram[ℋ2[[1]], Automatic, "PDF", PlotLabel -> "Test Statistics"], Histogram[ℋ2[[2]], Automatic, "PDF", PlotLabel -> "P-Values"]}The distribution fit test works with the values only when the input is a TimeSeries:
ts = TemporalData[TimeSeries, {{{1.224578634529677, 0.47929635789978015, 0.6572781300178168,
0.21496048742669355, 0.7299608014554928, -0.2495111111278263, -1.3286551762002712,
0.552725018274874, 0.19272112205837066, 1.1809144012420882, -1.1671 ... 40938613662046, 1.052394590214582, 0.9345044123980388, 0.38537803109557855,
-0.48660931166089394, -0.71203560340161}}, {{0, 100, 1}}, 1, {"Continuous", 1},
{"Discrete", 1}, 1, {ValueDimensions -> 1, ResamplingMethod -> None}}, False, 10.1];DistributionFitTest[ts, Automatic, {"TestDataTable", All}]DistributionFitTest[ts["Values"], Automatic, {"TestDataTable", All}]%% == %Possible Issues (5)
Some tests require that the parameters be prespecified and not estimated for valid ![]() -values:
-values:
data = RandomVariate[ArcSinDistribution[{-1, 4}], 10];ℋ = DistributionFitTest[data, ArcSinDistribution[{a, b}], "AndersonDarling"]It is usually possible to use Monte Carlo methods to arrive at a valid ![]() -value:
-value:
DistributionFitTest[data, ArcSinDistribution[{a, b}], "AndersonDarling", Method -> "MonteCarlo"]For many distributions, corrections are applied when parameters are estimated:
ℋ2 = DistributionFitTest[RandomVariate[NormalDistribution[], 10], NormalDistribution[a, b], "AndersonDarling"]The Jarque–Bera ALM test must have sample sizes of at least 10 for valid ![]() -values:
-values:
data = RandomVariate[NormalDistribution[], 5];DistributionFitTest[data, Automatic, "JarqueBeraALM"]Use Monte Carlo methods to arrive at a valid ![]() -value:
-value:
DistributionFitTest[data, Automatic, "JarqueBeraALM", Method -> "MonteCarlo"]The Kolmogorov–Smirnov test and Kuiper's test expect no ties in the data:
data = {1., 2., 1.5, 2., 1.75, 2.5, 3.};DistributionFitTest[data, Automatic, {"TestDataTable", {"KolmogorovSmirnov", "Kuiper"}}]The Jarque–Bera ALM test and Shapiro–Wilk test are only valid for testing normality:
data = RandomVariate[BetaDistribution[1, 2], 10];DistributionFitTest[data, BetaDistribution[a, b], {"TestDataTable", {"JarqueBeraALM", "ShapiroWilk"}}]Careful interpretation is required when some tests are used for discrete distributions:
data = RandomVariate[𝒹 = DiscreteUniformDistribution[{1, 10}], 100];ℋ = DistributionFitTest[data, 𝒹, "HypothesisTestData"];ℋ["TestDataTable", {"CramerVonMises", "AndersonDarling", "KolmogorovSmirnov", "Kuiper", "WatsonUSquare"}]The Pearson ![]() test applies directly for discrete distributions:
test applies directly for discrete distributions:
ℋ["TestDataTable", "PearsonChiSquare"]Neat Examples (1)
The distributions of some test statistics:
data = RandomVariate[𝒹 = NormalDistribution[], {5000, 50}];ℋ = DistributionFitTest[#, 𝒹, "HypothesisTestData"]& /@ data;T = Table[h["TestStatistic", i], {h, ℋ}, {i, tests = {"AndersonDarling", "CramerVonMises", "Kuiper", "KolmogorovSmirnov", "PearsonChiSquare", "WatsonUSquare"}}]//Transpose;Table[SmoothHistogram[T[[i]], PlotLabel -> tests[[i]], Filling -> Axis], {i, 6}]Text
Wolfram Research (2010), DistributionFitTest, Wolfram Language function, https://reference.wolfram.com/language/ref/DistributionFitTest.html (updated 2015).
CMS
Wolfram Language. 2010. "DistributionFitTest." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2015. https://reference.wolfram.com/language/ref/DistributionFitTest.html.
APA
Wolfram Language. (2010). DistributionFitTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/DistributionFitTest.html