



Dataset
Dataset[data]
リストおよび連想の階層に基づく,構造化データ集合を表す.
詳細とオプション





















- Datasetは,データの完全な多次元矩形配列だけでなく,任意の階層構造を持ったデータに対応する任意の木構造も表すことができる.
- Datasetオブジェクトは,含んでいるデータによって,表としてあるいは要素の格子として表示されることが多い.
- Map,Select等の関数は,Map[f,dataset],Select[dataset,crit]等を書くことで,Datasetに直接適用することができる.
- Datasetオブジェクト中のデータの部分集合は,dataset[[parts]]を書くことで得ることができる.
- Datasetオブジェクトは,dataset[query]を書いて特化したクエリ構文を使うことでクエリすることもできる.
- リストおよび連想の任意のネストが可能であるが,もっともよく使われるのは二次元(表)形式である.
- 次の表は,Datasetのよく使われる表示形式,それが含むWolfram言語の形式,その構造の論理解釈を表で表したものの間の対応関係である.
-

{{◻,◻,◻},
{◻,◻,◻},
{◻,◻,◻},
{◻,◻,◻}}
リストのリスト名前付きの行・列がない表 
{<"x"◻,"y"◻,…>,
<"x"◻,"y"◻,…>,
<"x"◻,"y"◻,…> }
連想のリスト名前付きの列がある表 
<"a"{◻,◻,◻},
"b"{◻,◻,◻},
"c"{◻,◻,◻},
"d"{◻,◻,◻}>
リストの連想名前付きの行がある表 
<"a"<"x"◻,"y"◻>,
"b"<"x"◻,"y"◻>,
"c"<"x"◻,"y"◻>>
連想の連想名前付きの行・列がある表 - Datasetはネストしたリストと連想を,行ごとに解釈する.つまり,データのレベル1(最も外側のレベル)は表の行として,レベル2は列として解釈される.
- 「名前付き」の行と列は,レベル1とレベル2の連想(キーは名前を含む文字列)にそれぞれ対応する.名前のない行と列はそれぞれのレベルのリストに対応する.
- データ集合の業および列はTranspose[dataset]を書くことで入れ替えることができる.
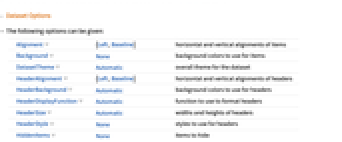
- 次は,使用可能なオプションである.
-
Alignment {Left,Baseline} 項目の水平および垂直の位置合せ Background None 項目の背景色 DatasetTheme Automatic データ集合の全体的なテーマ HeaderAlignment {Left,Baseline} ヘッダの水平および垂直の位置合せ HeaderBackground Automatic ヘッダの背景色 HeaderDisplayFunction Automatic ヘッダのフォーマットに使用する関数 HeaderSize Automatic ヘッダの高さと幅 HeaderStyle None ヘッダのスタイル HiddenItems None 隠す項目 ItemDisplayFunction Automatic 項目のフォーマットに使用する関数 ItemSize Automatic 項目の高さと幅 ItemStyle None 列と行のスタイル MaxItems Automatic 表示する項目の最大数 - HiddenItems,MaxItems,DatasetThemeを除くオプションの設定は,次のように各項目に別々に適用できる.
-
spec すべての項目に spec を適用する {speck} 連続するレベルで speckを適用する {spec1,spec2,…, specn,rules} 特定の部分に明示的な規則が使えるようにする - speckは以下の形でよい.
-
{s1,s2,…,sn} s1から snまでを使い,次にデフォルトを使う {{c}} すべての場合に c を使う {{c1,c2}} c1と c2を交互に使う {{c1,c2,…}} すべての ciを循環的に使う {s,{c}} s を使い,次に c を繰り返し使う {s1,{c},sn} s1を使い,次に c を繰り返し使うが,最後は snを使う {s1,s2,…,{c1,c2,…},sm,…,sn} 最初の一続きの siを使い,次に ciを循環的に使い,最後に siの最後の一続きを使う {s1,s2,…,{},sm,…,sn} はじめに siの最初の一続きを使い,最後に終りの一続きを使う - {s1,s2,…,{…},sm,…,sn}の形の設定のとき,データ集合内の項目数よりも指定されたの siの方が多い場合は,最初の方の項目には最初の siが使われ,最後の方の項目には最後のものが使われる.
- 規則は ispec の形をしている.i はDataset中の位置を指定する.位置はパターンでもよい.
- 要素の位置は,要素にカーソルを合わせてデータ集合の一番下から読むことができる.
- MaxItemsの設定は以下のように与えられる.
-
m m 行を指定する {m1, m2,…,mn} データ集合のレベル i の mi項目を表示する - MaxItemsのAutomaticはデフォルト数の項目を表示すべきであることを示す.
- HiddenItemsの設定は以下のように与えられる.
-
i 位置 i の項目を隠す {i1,i2,…,in} 位置 ikの項目を隠す {…, iFalse,…} 位置 i の項目を表示する {…, iTrue,…} 位置 i の項目を隠す - HiddenItemsリスト内の後ろの設定は前の設定を無効にする.
- ItemDisplayFunctionとHeaderDisplayFunctionについての個別の設定は,表示される項目を返す純関数である.関数は,項目の値,項目の位置,項目を含むデータ集合の3つの引数を取る.
- ItemStyleとHeaderStyleの設定の位置の中で,明示的な規則が ispec として解釈されることがある.スタイルオプションのつもりなら規則をDirectiveでラップするとよい.
- Alignment,HeaderAlignment,ItemSize,HeaderSizeのような値のリストの場合があるオプションでは,トップレベルのリストは可能な場合は単一のオプション値として,それ以外の場合は連続するDatasetレベルについての値のリストとして解釈される.
- 規則の左辺がリストではない場合は,左辺をキーまたは指標として含む任意の位置に設定が適用される.
- 設定を返す純関数 f を設定の位置に使うことができる.この設定は f[item,position,dataset]で与えられる.
- Normalを使って任意のDatasetオブジェクトをもとになっているデータ(リストと連想の組合せのことが多い)に変換できる.
- 構文 dataset[[parts]]あるいはPart[dataset,parts]を使ってDatasetの一部を抽出することができる.
- Datasetから抽出できる部分には,Partの通常の指定が含まれる.
- Partの通常の動作とは異なり,Datasetに指定された下位区分が存在しない場合は,結果としてその代りにMissing["PartAbsent",…]が生成される.
- 次は,表形式のデータ集合から行を抽出するのによく使われる部分操作である.
-
dataset[["name"]] 名前付きの行を抽出(該当する場合) dataset[[{"name1",…}]] 名前付きの行の集合を抽出 dataset[[1]] 第1行を抽出 dataset[[n]] 第 n  列を抽出
列を抽出dataset[[-1]] 最終行を抽出 dataset[[m;;n]] 第 m 行から第 n 行までを抽出 dataset[[{n1,n2,…}]] 番号付きの行集合を抽出 - 次は,表形式のデータ集合から列を抽出するのによく使われる部分操作である.
-
dataset[[All,"name"]] 名前付きの列を抽出(該当する場合) dataset[[All,{"name1",…}]] 名前付きの列の集合を抽出 dataset[[All,1]] 第1列を抽出 dataset[[All,n]] 第 n  列を抽出
列を抽出dataset[[All,-1]] 最終列を抽出 dataset[[All,m;;n]] 第 m 列から第 n 列までを抽出 dataset[[All,{n1,n2,…}]] 列の部分集合を抽出 - Partと同じように,行と列の操作は組み合せることができる.次はその例である.
-
dataset[[n,m]] 第 n  行の第 m 列のセルを取り出す
行の第 m 列のセルを取り出すdataset[[n,"colname"]] 第 n  行の名前付きの列の値を抽出
行の名前付きの列の値を抽出dataset[["rowname","colname"]] 名前付きの行の名前付きの列のセルを取り出す - 次の操作で,事実上連想をリストにすることで,行および列のラベルを取り除くことができる.
-
dataset[[Values]] 行からラベルを取り除く dataset[[All,Values]] 列からラベルを取り除く dataset[[Values,Values]] 行と列からラベルを取り除く - クエリ構文 dataset[op1,op2,…]は,集約と変換の適用を許可してデータの部分集合を取る,Part構文の拡張と考えることができる.
- 次は,よく使われるクエリ形式のリストである.
-
dataset[f] f を表全体に適用 dataset[All,f] f を表内のすべての行に適用 dataset[All,All,f] f を表内のすべてのセルに適用 dataset[f,n] 第 n  列を抽出し,これに f を適用
列を抽出し,これに f を適用dataset[f,"name"] 名前付きの列を抽出し,これに f を適用 dataset[n,f] 第 n  行を抽出し,これに f を適用
行を抽出し,これに f を適用dataset["name",f] 名前付きの行を抽出し,これに f を適用 dataset[{nf}] 第 n  行に選択的に f をマップ
行に選択的に f をマップdataset[All,{nf}] 第 n  列に選択的に f をマップ
列に選択的に f をマップ - 特殊な形のクエリ
-
dataset[Counts,"name"] の名前付きの列中の,異なる値の数を与える dataset[Count[value],"name"] 名前付きの列の中での,value の出現回数を与える dataset[CountDistinct,"name"] 名前付きの列の中で,他とは異なる値の数を数える dataset[MinMax,"name"] 名前付きの列の中の最大値と最小値を与える dataset[Mean,"name"] 名前付きの列の中の平均値を与える dataset[Total,"name"] 名前付きの列の値の合計を与える dataset[Select[h]] 条件 h を満足する行を取り出す dataset[Select[h]/*Length] 条件 h を満足する行数を数える dataset[Select[h],"name"] 行を選択し,結果から名前付きの列を抽出する dataset[Select[h]/*f,"name"] 行を選択し,名前付きの列を抽出し,次にこれに f を適用する dataset[TakeLargestBy["name",n]] 名前付きの列が最大である n 行を与える dataset[TakeLargest[n],"name"] 名前付きの列の中の最大な n 個の値を与える - dataset[op1,op2,…]では,クエリ演算子 opiは,事実上,データの連続的に深いレベルに適用される.しかし,データを「下降中」あるいは「上昇中」に任意の1つが適用されることがある.
- Datasetクエリを構成する演算子は,明確な上昇あるいは下降動作のある,次の大きいカテゴリの1つに入る.
-
All,i,i;;j,"key",… 下降 部分演算子 Select[f],SortBy[f],… 下降 フィルタリング演算子 Counts,Total,Mean,… 上昇 集約演算子 Query[…],… 上昇 サブクエリ演算子 Function[…],f 上昇 任意の関数 - 「下降」演算子は,続く演算子がより深いレベルに適用される前に,もとのデータ集合の対応する部分に適用される.
- 下降演算子は,あるレベルに適用された場合に,データのより深いレベルの構造は変えないという特徴を持つ.このため,続く演算子はもとのデータ集合の対応するレベルにあるのと同一の構造を持つ部分式に遭遇することになる.
- 最も単純な下降演算子はAllである.この演算子は指定されたレベルのすべての部分を選択し,そのレベルのデータ構造はそのままに残す.Allは,他の有効なクエリを行うために,他の下降演算子と問題なく置換することができる.
- 「上昇」演算子は,より深いレベルに続く上昇・下降演算子がすべて適用された後で適用される.下降演算子がもとのデータのレベルに対応するのに対し,上昇演算子は結果のレベルに対応する.
- 下降演算子とは異なり,上昇演算子はそれが適用されるデータの構造を必ずしも保存しない.演算子は,特に下降演算子として認識されている場合を除いて,上昇演算子であるとみなされる.
- 「下降」部分演算子は,続く演算子をより深いレベルに適用する前に,あるレベルでどの要素を取るかを指定する.
-
All 続く演算子をリストあるいは連想の各部分に適用する i;;j i から j までの部分を取り,続く演算子を各部分に適用する i i の部分だけを取り,続く演算子をそれに適用する "key",Key[key] 連想中の key の値を取り,続く演算子をそれに適用する Values 連想の値を取り,続く演算子を各値に適用する {part1,part2,…} 指定された部分を取り,続く演算子を各部分に適用する - 「下降」フィルタリング演算子は,より深いレベルに続く演算子を適用する前に,あるレベルで要素をどのように並べ直すか,あるいは要素にどのようにフィルタをかけるかを指定する.
-
Select[test] test を満足するリストあるいは連想の部分だけを取る SelectFirst[test] test を満足する最初の部分を取る KeySelect[test] キーが test を満足する連想の部分を取る TakeLargestBy[f,n],TakeSmallestBy[f,n] f[elem]が最大または最小になる n 個の要素を順に取る MaximalBy[crit],MinimalBy[crit] 基準 crit が他のすべての要素よりも小さいあるいは大きい部分を順に取る SortBy[crit] crit の順で部分を並び替える KeySortBy[crit] 連想の各部分をそのキーに基づいて crit の順にソートする DeleteDuplicatesBy[crit] crit によって一意的である部分を取る DeleteMissing 頭部Missingを持つ要素を除去する - 構文 op1/*op2を使って2つあるいはそれ以上のフィルタリング演算子を組み合せて,1つのレベルで動作する1つの演算子にすることができる.
- 「上昇」集合演算子は,続く演算子をより深いレベルに適用した結果を,組み合せたり要約したりする.
-
Total 結果のすべての数量を合計する Min,Max 結果の最大量と最小量を与える Mean,Median,Quantile,… 結果の統計的要約を与える Histogram,ListPlot,… 結果の可視化を計算する Merge[f] 関数 f を使って,結果の連想の共通キーを1つにする Catenate リストあるいは連想の要素を連結させる Counts 結果中の値の出現を数える連想を与える CountsBy[crit] 値の出現を crit に従って数える連想を与える CountDistinct 結果中の他とは異なる値の数を与える CountDistinctBy[crit] 結果中の他とは異なる値の数を,crit に従って与える TakeLargest[n],TakeSmallest[n] 最大または最小のt n 個の要素を取る - 構文 op1/*op2を使って2つあるいはそれ以上の集約演算子を組み合せて,1つのレベルで動作する1つの演算子にすることができる.
- 「上昇」サブクエリ演算子は,より深いレベルに連続する演算子を適用した後で,サブクエリを行う.
-
Query[…] 結果にサブクエリを実行する {op1,op2,…} 複数の演算子を結果に同時に適用し,リストを返す <key1op1,key2op2,…> 複数の演算子を結果に同時に適用し,指定されたキーを持つ連想を返す {key1op1,key2op2,…} 結果の特定の部分に異なる演算子を適用する - 1つあるいは複数の下降演算子が1つあるいは複数の上昇演算子と組み合せられると(例:desc/*asc),最初に下降部分が適用され,続く演算子がより深いレベルに適用され,最後に上昇部分がそのレベルの結果に適用される.
- 特殊「下降」演算子GroupBy[spec]は,それが現れたレベルに新たな連想を導入し,他の演算子の動作に影響することなく,既存のクエリに挿入されることも既存のクエリから削除されることもできる.
- CountsBy,GroupBy,TakeLargestBy等の関数は,通常は他の関数を引数の1つとして取る.Dataset中の連想と使う場合は,この引数関数を使って表の列の値を見ることがよくある.
- これを簡単にするために,Datasetクエリでは,そのようなコンテキストの場合に構文"string"でKey["string"]を表すことができる.例えば,クエリ演算子GroupBy["string"]は,実行前に自動的にGroupBy[Key["string"]]に書き換えられる.
- 同様に,式GroupBy[dataset,"string"]はGroupBy[dataset,Key["string"]]に書き換えられる.
- 可能な場合は,クエリが成功するかどうかを決定するためにタイプインターフェースが使われる.失敗すると推測される操作については,クエリは実行されず,Failureオブジェクトが返される.
- デフォルトで,クエリの最中にメッセージが生成されると,クエリは放棄され,メッセージを含むFailureオブジェクトが返される.
- クエリが構造化データ(例:連想のリスト,あるいはそのネストした組合せ)を返すと,結果は別のDatasetオブジェクトの形式で返される.その他の場合は,結果は通常のWolfram言語式で返される.
- Datasetクエリの特別の動作についてのその他の情報は,Queryの関数ページを参照されたい.
- Datasetオブジェクトは,ImportとSemanticImportを使って"CSV"や"XLSX"等の形式からインポートできる.
- Datasetオブジェクトは,Exportを使って"CSV","XLSX","JSON"等の形式にエキスポートできる.
データ集合の構造
データ集合のオプション
部分操作
データ集合のクエリ
下降演算子と上昇演算子
部分操作
フィルタリング演算子
集約演算子
サブクエリ演算子
特殊演算子
構文のショートカット
クエリ動作
インポートとエキスポート
例題
すべて開く すべて閉じるスコープ (1)
オプション (42)
アプリケーション (3)
表(連想のリスト) (1)
指標付きの表(連想の連想) (1)
階層的データ(他のデータの連想の連想) (1)
もとのデータは,キーが国で,値が行政地区とその人口の間のさらなる連想である連想である:
総人口を与える(データ集合に世界中のすべての国が含まれているわけではない):
ListLogPlotに渡されたもとのデータは,それぞれの長さが2であるリストの連想である:
特性と関係 (4)
QueryはDatasetがサポートするクエリ言語の演算子形である:
EntityValueを使って,Wolfram KnowledgebaseからEntityオブジェクトの特性のDatasetを得る:
SemanticImportを使い,ファイルをDatasetとしてインポートする:
「タイタニック号」の乗客のデータ集合の小さいサンプルを得る:
このサンプルを"JSON"形式でエキスポートする:
名前付きの列があるデータは,まず最初に転置をすることでよりコンパクトに表すことができる:
このサンプルを"CSV"としてエキスポートする:
考えられる問題 (3)
一貫した構造がないデータは,一般には,構造化データと同じようにはフォーマットされない:
クエリの部分的な操作が失敗すると推定される場合は,クエリ全体が実行されず,Failureオブジェクトが返される:
デフォルトで,Datasetに対する操作中にメッセージが生成されると,Failureオブジェクトが返される:
異なる動作を指定したければ,FailureAction操作と合わせて明示的なQuery式を使うとよい:
テキスト
Wolfram Research (2014), Dataset, Wolfram言語関数, https://reference.wolfram.com/language/ref/Dataset.html (2021年に更新).
CMS
Wolfram Language. 2014. "Dataset." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2021. https://reference.wolfram.com/language/ref/Dataset.html.
APA
Wolfram Language. (2014). Dataset. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/Dataset.html