线性代数
线性代数
| Table[f,{i,m},{j,n}] | 建立一个 m×n 矩阵,其中 f 是 i 和 j 的函数,给出第 i,j 项的值 |
| Array[f,{m,n}] | 建立一个 m×n 矩阵,其第 i,j 项是 f[i,j] |
| ConstantArray[a,{m,n}] | 建立一个 m×n 矩阵,其所有的项都等于 a |
| DiagonalMatrix[list] | 生成对角矩阵,对角线上是 list 的元素 |
| IdentityMatrix[n] | 生成 n×n 单位阵 |
| Normal[SparseArray[{{i1,j1}->v1,{i2,j2}->v2,…},{m,n}]] | 生成一个矩阵,其中位于 {ik,jk} 的项为非零的值 vk |
DiagonalMatrix 产生一个主对角线以外的元素均为零的矩阵:
MatrixForm 以二维矩阵形式显示矩阵:
| Table[0,{m},{n}] | 零矩阵 |
| Table[If[i>=j,1,0],{i,m},{j,n}] | 下三角矩阵 |
| RandomReal[{0,1},{m,n}] | 元素为随机数字的矩阵 |
| SparseArray[{},{n,n}] | 零矩阵 |
| SparseArray[{i_,i_}->1,{n,n}] | n×n 单位阵 |
| SparseArray[{i_,j_}/;i>=j->1,{n,n}] | 下三角矩阵 |
用 SparseArray 构造特殊类型的矩阵.
| m[[i,j]] | 第 i,j 个元素 |
| m[[i]] | 第 i 行 |
| m[[All,i]] | 第 i 列 |
| Take[m,{i0,i1},{j0,j1}] | 第 i0 行到第 i1 行、第 j0 列到第 j1 列构成的子阵 |
| m[[i0;;i1,j0;;j1]] | 第 i0 行到第 i1 行、第 j0 列到第 j1 列构成的子阵 |
| m[[{i1,…,ir
},{
j1,… , js
}]]
| 行标为 ik 列标为 jk 的元素构成 r×s 子阵 |
| Tr[m,List] | 对角线上的元素 |
| ArrayRules[m] | 非零元素的位置 |
| m={{a11,a12,…},{a21,a22,…},…} | 给 m 赋值为一个矩阵 |
| m[[i,j]]=a | 重新设置元素 {i,j} 为 a |
| m[[i]]=a | 重新设置第 i 行的所有元素为 a |
| m[[i]]={a1,a2,…} | 重新设置第 i 行的元素为 {a1,a2,…} |
| m[[i0;;i1]]={v1,v2,…} | 重新设置第 i0 行到第 i1 行为向量 {v1,v2,…} |
| m[[All,j]]=a | 重新设置第 j 列的所有元素为 a |
| m[[All,j]]={a1,a2,…} | 重新设置第 j 列的元素为 {a1,a2,…} |
| m[[i0;;i1,j0;;j1]]={{a11,a12,…},{a21,a22,…},…} | 重新设置第 i0 行到第 i1 行,第 j0 列到第 j1 列的子矩阵为新的数值 |
| VectorQ[expr] | |
| MatrixQ[expr] | |
| Dimensions[expr] | 向量或矩阵的维数列表 |
Wolfram 语言中的大部分数学函数能分别作用于列表中的每个元素,特别是具有属性 Listable 的函数都能做到这一点.
Log 分别作用于向量中的每个元素:
微分函数 D 也能分别作用于列表的每个元素:
在特定运算中只有当对象明显是一个列表时,Wolfram 语言才将其作为向量处理. 认识这一点很重要. 如果对象不明显是一个列表,Wolfram 语言总是作为标量处理. 这意味着在特定运算之前还是之后给某个对象赋列表值,得到的结果是不同的.
| cv , cm, etc. | 用标量乘每个元素 |
| u.v , v.m, m.v, m1.m2, etc. | 向量和矩阵相乘 |
| Cross[u,v] | 向量叉积(也输入为 u×v) |
| Outer[Times,t,u] | 外积 |
| KroneckerProduct[m1,m2,…] | Kronecker 积 |
注意,"." 算符用于矩阵左乘和右乘向量,Wolfram 语言不区分“行”和“列”向量. Dot (点)算符将进行任何可能的运算. (用正式的数学语言来说,即 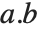 将张量
将张量 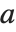 的最后一个下标和
的最后一个下标和 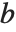 的第一个下标缩并起来.)
的第一个下标缩并起来.)
有时,可能需要用符号表示向量和矩阵,而不是给出其元素. 对这种符号对象,可以用 Dot (点)表示乘法.
| v[[i]] 或 Part[v,i] | 给出向量 v 中的第 i 个元素 |
| c v | c 乘向量 v 的标积 |
| u.v | 两个向量的点积 |
| Norm[v] | 给出 v 的范数(模) |
| Normalize[v] | 给出一个在 v 方向的单位向量 |
| Standardize[v] | 变换 v 以得到零的均值和单位抽样方差 |
| Standardize[v,f1] | 用 f1[v] 变换 v 并按比例调节来得到单位样本方差 |
| Projection[u,v] | 给出 u 在 v 上的垂直投影 |
| Orthogonalize[{v1,v2,…}] | 从给定的一列向量产生正交归一的一组向量 |
| Inverse[m] | 求方阵的逆矩阵 |
必须使用 Together 来消除分母,以得到一个标准单位阵:
可以使用 Chop 去掉非对角线上的微小元素:
当对具有精确值元素的矩阵求逆时,Wolfram 语言总能辨别矩阵是否是奇异的. 当对近似数值阵求逆时,Wolfram 语言通常不能肯定地辨别矩阵是否是奇异的:只能辨别与矩阵元素相比,其行列式的值是很小的. 当 Wolfram 语言怀疑是在给奇异数值阵求逆時,会给出一个警告.
| Transpose[m] | 矩阵转置 m |
| ConjugateTranspose[m] | 共轭转置 m(Hermitian 共轭) |
| Inverse[m] | 矩阵求逆 |
| Det[m] | 行列式 |
| Minors[m] | 矩阵子式 |
| Minors[m,k] | k 阶子式 |
| Tr[m] | 矩阵的迹 |
| MatrixRank[m] | 矩阵的秩 |
矩阵的迹 Tr[m] 是主对角线上的元素之和.
| MatrixPower[m,n] | 矩阵的 n 次幂 |
| MatrixExp[m] | 矩阵指数 |
许多计算涉及求解线性方程组. 在许多情形下,明确写出各个方程,然后使用 Solve 求解是方便的.
注意,如果方程系统是稀疏的,即相应的矩阵 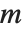 的大多数元素是零,那么最好是把矩阵表示为一个 SparseArray 对象. 就像在 “稀疏数组:线性代数” 中讨论的,能够使用 CoefficientArrays 来把符号方程转化成 SparseArray 对象. 所有这里描述的函数不但对普通的矩阵适用,而且也对 SparseArray 对象适用.
的大多数元素是零,那么最好是把矩阵表示为一个 SparseArray 对象. 就像在 “稀疏数组:线性代数” 中讨论的,能够使用 CoefficientArrays 来把符号方程转化成 SparseArray 对象. 所有这里描述的函数不但对普通的矩阵适用,而且也对 SparseArray 对象适用.
| LinearSolve[m,b] | 给出矩阵方程 |
| NullSpace[m] | 一列线性独立的向量,其线性组合包括矩阵方程 |
| MatrixRank[m] | |
| RowReduce[m] | 通过行的线性组合得到的 |
可以直接用 Solve 解此方程组.
RowReduce 进行一种形式的高斯消元,也可以用来解方程组.
NullSpace 和 MatrixRank 必须决定矩阵元素的特定组合是否为零. 对于近似数值矩阵,能够用 Tolerance 选项来指定在和零多近时才可以被认为是足够近的. 对于精确的符号矩阵,有时需要通过类似于 ZeroTest->(FullSimplify[#]==0&) 的指定来强制进行更多的运算以测试符号表达式是否为零.
欠定
| 方程的个数少于变量的个数;可能无解,也可能有多解 |
超定
| 独立方程的个数多于变量的个数;可能有解,也可能无解 |
非奇异
| 独立方程的个数等于变量的个数,行列式不为零;存在唯一解 |
相容
| 至少存在一个解 |
不相容
| 不存在解 |
LinearSolve 给出欠定方程组的一个解:
LinearSolve 给出的解,加上零空间的基向量的线性组合,仍然是解:
| LinearSolve[m] | 产生一个求解形如 |
产生 LinearSolveFunction 对象.
在某些应用中,会希望多次求解形式为 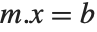 的方程组,其具有相同的
的方程组,其具有相同的 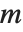 ,但不同的
,但不同的 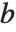 . 在 Wolfram 语言中能这样有效地做,那就是使用 LinearSolve[m] 来产生一个单一的 LinearSolveFunction,应用于任意多的向量.
. 在 Wolfram 语言中能这样有效地做,那就是使用 LinearSolve[m] 来产生一个单一的 LinearSolveFunction,应用于任意多的向量.
产生一个 LinearSolveFunction:
将这个向量作为一个明确的第二自变量给予 LinearSolve,能得到相同的结果:
| LeastSquares[m,b] | 给出一个最小二乘问题 |
| Eigenvalues[m] | m 的特征值列表 |
| Eigenvectors[m] | m 的特征向量的列表 |
| Eigensystem[m] | 形如 {eigenvalues,eigenvectors}({特征值,特征向量})的列表 |
| Eigenvalues[N[m]], etc. | 数字特征值 |
| Eigenvalues[N[m,p]], etc. | p 位精度的数字特征值 |
| CharacteristicPolynomial[m,x] | m 的特征多项式 |
对于 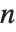 ×
×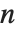 的矩阵,Eigenvalues 总是给出一个
的矩阵,Eigenvalues 总是给出一个 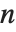 个特征值的列表. 特征值是矩阵的特征多项式的根,可能是相同的. 另一方面,Eigenvectors 给出相互独立的特征向量的列表. 当特征向量的数目小于
个特征值的列表. 特征值是矩阵的特征多项式的根,可能是相同的. 另一方面,Eigenvectors 给出相互独立的特征向量的列表. 当特征向量的数目小于 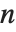 时,Eigenvectors 将在列表中添加零向量,使列表的长度总为
时,Eigenvectors 将在列表中添加零向量,使列表的长度总为 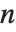 .
.
但是,该矩阵仅有一个独立的特征向量. 此时,Eigenvectors 添加两个零向量给出总共三个向量:
| Eigenvalues[m,k] | m 的最大的 k 个特征值 |
| Eigenvectors[m,k] | m 的相应的特征向量 |
| Eigensystem[m,k] | m 的最大的 k 个特征值以及相应的特征向量 |
| Eigenvalues[m,-k] | m 的最小的 k 个特征值 |
| Eigenvectors[m,-k] | m 的相应的特征向量 |
| Eigensystem[m,-k] | m 的最小的 k 个特征值以及相应的特征向量 |
Eigenvalues 对数值特征值进行排序,使得绝对值大的排在最先. 在很多情况下,也许仅对矩阵的最大或最小的特征值感兴趣. 能用 Eigenvalues[m,k] 和 Eigenvalues[m,-k] 来得到.
| Eigenvalues[{m,a}] | 相对于 a 的 m 的广义特征值 |
| Eigenvectors[{m,a}] | 相对于 a 的 m 的广义特征向量 |
| Eigensystem[{m,a}] | 相对于 a 的 m 的广义特征系统 |
| CharacteristicPolynomial[{m,a},x] | 相对于 a 的 m 的广义特征多项式 |
广义特征值对应于广义特征多项式 Det[m-x a] 的零点.
这两个矩阵共享一个一维的零空间,所以一个广义特征值是 Indeterminate:
| SingularValueList[m] | m 的非零的奇异值的列表 |
| SingularValueList[m,k] | m 的 k 个最大的奇异值 |
| SingularValueList[{m,a}] | m 的相对于 a 的广义奇异值 |
| Norm[m,p] | m 的 p-范数 |
| Norm[m,"Frobenius"] | m 的 Frobenius 范数 |
矩阵 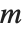 的奇异值是
的奇异值是 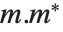 的特征值的平方根,这里
的特征值的平方根,这里  表示 Hermitian 转置. 奇异值的数目是矩阵的最小的维数. SingularValueList 将奇异值从最大到最小进行整理. 非常小的奇异值通常在数值上没有意义的. 当使用 Tolerance->t 这个选项设置时,SingularValueList 去掉小于最大奇异值的 t 部分的那些奇异值. 对于近似数字矩阵,默认下的容限值稍微比零大一点.
表示 Hermitian 转置. 奇异值的数目是矩阵的最小的维数. SingularValueList 将奇异值从最大到最小进行整理. 非常小的奇异值通常在数值上没有意义的. 当使用 Tolerance->t 这个选项设置时,SingularValueList 去掉小于最大奇异值的 t 部分的那些奇异值. 对于近似数字矩阵,默认下的容限值稍微比零大一点.
| LUDecomposition[m] | 求任意方阵的 LU 分解 |
| CholeskyDecomposition[m] | Cholesky 分解 |
LU 分解将任何方阵有效地分解为下三角和上三角阵的乘积. Cholesky 分解将任何 Hermitian 正定矩阵分解为一个下三角阵和其 Hermitian 共轭的乘积,这可以看成是类似于求一个方阵的平方根.
| PseudoInverse[m] | 计算矩阵的伪逆 |
| QRDecomposition[m] | 求数值矩阵的 QR 分解 |
| SingularValueDecomposition[m] | 奇异值分解 |
| SingularValueDecomposition[{m,a}] | 广义奇异值分解 |
当矩阵不是方阵或是奇异时,标准的逆矩阵定义不再有效. 然而,可以定义矩阵 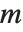 的伪逆矩阵
的伪逆矩阵 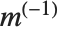 . 使得
. 使得 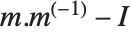 中的所有元素的平方和被最小化,其中
中的所有元素的平方和被最小化,其中 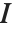 是单位阵. 伪逆矩阵有时被称为广义逆,或 Moore–Penros. 这尤其在关于最小平方拟合的问题中使用.
是单位阵. 伪逆矩阵有时被称为广义逆,或 Moore–Penros. 这尤其在关于最小平方拟合的问题中使用.
| JordanDecomposition[m] | Jordan 分解 |
| SchurDecomposition[m] | Schur 分解 |
| SchurDecomposition[{m,a}] | 广义 Schur 分解 |
| HessenbergDecomposition[m] | Hessenberg 分解 |
绝大多数的方阵都能被变成一个特征值的对角阵,这可以通过用其特征向量矩阵作为相似变换来完成. 但是即使在没有足够的特征向量来做这个时,仍然可以将矩阵变成 Jordan 形式,在其中对角线上既有特征值又有 Jordan 块. Jordan 分解一般将任何方阵写成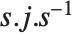 的形式.
的形式.
数值上更稳定的是 Schur 分解,将任何矩阵 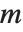 写成
写成 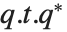 的形式,其中
的形式,其中 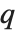 是一个正交归一的矩阵,
是一个正交归一的矩阵,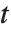 是块式上三角. 也相关的是 Hessenberg 分解,将一个方阵写成
是块式上三角. 也相关的是 Hessenberg 分解,将一个方阵写成 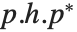 的形式,其中
的形式,其中 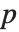 是一个正交归一的矩阵,
是一个正交归一的矩阵, 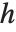 可以在主对角线以下的对角线上有非零的元素.
可以在主对角线以下的对角线上有非零的元素.
产生 k 阶张量的一个简单方法是给出 k 个变量的函数的值表. 在物理学中出现的张量具有指出空间或时空方向的指标. 注意,在 Wolfram 系统中,没有共变和协变张量指标的概念. 用户须使用度量张量来建立这些概念.
| Table[f,{i1,n1},{i2,n2},…,{ik,nk}] | |
建立一个 n1×n2×…×nk 张量,其元素是 f 的值 | |
| Array[a,{n1,n2,…,nk}] | 建立一个 n1×n2×…×nk 张量其元素通过把 a 用于每个指标集合给出 |
| ArrayQ[t,n] | 检验是否 t 是一个 n 阶张量 |
| Dimensions[t] | 给出张量的维数的列表 |
| ArrayDepth[t] | 求张量的阶 |
| MatrixForm[t] | 以两维阵列的形式排列张量 t 的元素 |
Dimensions 给出张量的维数:
ArrayDepth 给出张量的阶:
| Transpose[t] | 张量的前两个指标的转置 |
| Transpose[t,{p1,p2,…}] | 转置张量,使第 k 个指标变成为第 pk 个指标 |
| Tr[t,f] | 构造张量 t 的广义迹 |
| Outer[f,t1,t2] | 构造张量 t1 和 t2 在“乘法算子” f 下的广义外积 |
| t1.t2 | 构造 t1 和 t2 的点积(t1 的最后一个指标和 t2 的第一个指标被删去) |
| Inner[f,t1,t2,g] | 构造广义内积,带有“乘法算子” f 和“加法算子” g |
可以把 k 阶张量看作有 k 个插入指标的“位置”. 使用 Transpose 是重排这些位置的有效方法. 如果把张量的元素看作构成 k 维立方体,那么 Transpose 就是旋转(也可能是反射)该立方体.
在最一般的情形,Transpose 允许任意重排张量指标. 函数 Transpose[T,{p1,p2,…,pk}] 给出一个新的张量 T′,使得 T′i1 i2 … ik 的值由 Tip1 ip2 … ipk 给定.
如果一个张量的不同层次具有同样的长度,则可以使用 Transpose 压缩不同的层次.
也可以用 Tr 提取张量的对角元素.
用指标来描述,对两个张量 Ti1 i2 … ir 和 Uj1 j2 … js 应用 Outer 的结果是张量 Vi1 i2 … irj1 j2 … js,其元素是 f[Ti1 i2 … ir,Uj1 j2 … js].
构造 Outer[f,t,u] 时,把 u 插入到 t 的每一点. 构造 Inner[f,t,u] 时,组合并删去 t 的最后一维和 u 的第一维,即取 m1×m2×…×mr 张量和 n1×n2×…×ns 张量(其中 mr=n1),得到一个 m1×m2×…×mr-1×n2×…×ns 张量.
在张量的许多应用中,需要添加正负号实现反对称. 函数 Signature[{i1,i2,…}] 给出交换的正负号,常常用于这种目的.
| Outer[f,t1,t2,…] | 通过组合 t1,t2,… 最低层元素构造广义外积 |
| Outer[f,t1,t2,…,n] | 将第 n 层子列表作为分离元素处理 |
| Outer[f,t1,t2,…,n1,n2,…] | 将 ti 中的第 ni 层子列表作为分离元素 |
| Inner[f,t1,t2,g] | 使用 t1 的最低层元素,构造广义内积 |
| Inner[f,t1,t2,g,n] | 将第一个张量的指标 n 与第二个张量的第一个指标合并压缩 |
| ArrayFlatten[t,r] | 从一个 r 阶的 r 阶张量产生一个展平的 r 阶张量 |
| ArrayFlatten[t] | 展平矩阵的矩阵(等同于 ArrayFlatten[t,2]) |
许多大型的线性代数的应用涉及到含有很多元素的矩阵,但是这些元素中很少是非零的. 在 Wolfram 系统中可以使用 SparseArray 对象有效地表示这些稀疏矩阵,这在 “稀疏数组:操作列表” 中讨论. SparseArray 对象是通过用规则列表指定非零数值出现的地方来工作的.
| SparseArray[list] | 一个普通列表的 SparseArray 形式 |
| SparseArray[{{i1,j1}->v1,{i2,j2}->v2,…},{m,n}] | |
一个 m×n 稀疏数组,其元素 {ik,jk} 具有数值 vk | |
| SparseArray[{{i1,j1},{i2,j2},…}->{v1,v2,…},{m,n}] | |
同样的稀疏数组 | |
| Normal[array] | 相应于一个 SparseArray 的普通列表 |
| Dimensions[m] | 数组的维数 |
| ArrayRules[m] | 对于数组中非零元素的规则 |
| m[[i,j]] | 元素 i,j |
| m[[i]] | 第 i 行 |
| m[[All,j]] | 第 i 行 |
| m[[i,j]]=v | 重新设置元素 i,j |
可以直接应用于 SparseArray 对象的几个结构运算.
| SparseArray[rules] | 根据规则产生稀疏数组 |
| CoefficientArrays[{eqns1,eqns2,…},{x1,x2,…}] | |
从方程中获得系数的数组 | |
| Import["file.mtx"] | 从文件中导入稀疏数组 |
CoefficientArrays 可以处理一般的多项式方程: