文本输入和输出
Wolfram 语言中可以有许多不同的方式输出表达式.
输出形式提供了 Wolfram 语言表达式的文本表示形式. 在有些情况下,这些文本表示方式也适用于 Wolfram 语言的输入. 但是在其他情况下,这仅用来进行查看,或者输出到其他程序,而不是用来作为 Wolfram 语言的输入.
CForm 产生一个能包含在 C 程序中的输出. 诸如
Power 等对象的宏被包含在头文件
mdefs.h 中:
"底层的输入输出规则" 节中讨论怎样产生自己的输出形式. 但应该看到在与外部程序的交互时,最好用 Wolfram Symbolic Transfer Protocol (WSTP)
去直接传送表达式,而不是产生这些表达式的文本表示形式.
■ 交换表达式的文本形式. |
■ 通过 WSTP 直接交换表达式. |
| 将文本形式转化为一个表达式 |
Processing | 进行表达式的计算 |
Output | 将结果中的表达式转化为文本形式 |
以
x^2 为例,Wolfram 语言现将用户输入的内容当作由字符
x、
^、
2 组成的字符串. 但根据 Wolfram 语言通常的设置方式,立刻就知道把这个字符串转化为表达式
Power[x,2].
接着,当可能的运算完成后,Wolfram 语言就把表达式
Power[x,2] 转化为输出中的文本表示方式.
Wolfram 语言读入字符串
x、
^、
2,并将其转化为表达式
Power[x,2]:
重要的一点是要理解在 Wolfram 语言的一个常规进程中,
In[n] 和
Out[n] 仅记录被处理的表达式,而不是输入和输出中恰巧所用的文本形表达式.
如果用户通过使用使用
TraditionalForm[expr] 等明确要求一种特定的输出形式,则用户得到的结果将被标以
Out[n]//TraditionalForm. 这表明即使
Out[n] 的值自身仅是一个表达式
expr,所看到的仍是
expr//TraditionalForm.
Wolfram 语言还允许用户进行全局设定输出形式. 这样做时,每行就不再显式标出输出形式. 但
In[n] 和
Out[n] 仍仅记录被处理的表达式,而不是用在输入和输出中的文本形式.
与 Wolfram 系统中的其他内容相似,表达式的文本形式本身也可以表示为一个表达式. 由一维字符序列组成的文本形式可以用普通的 Wolfram 系统字符串直接表示. 而涉及到上、下标和其他二维结构的文本形式可用二维框符的嵌套集合来表示.
当使用 Wolfram 系统的笔记本前端时,通过使用的菜单项可以看到与每个单元的文本形式对应的表达式.

通过使用 的菜单项,此处以框符形式显示该表达式的底层表示:

| ToString[expr,form] | 创建一个字符串,代表 expr 的指定文本形式 |
| ToBoxes[expr,form] | 创建一个框符结构,代表 expr 的指定文本形式 |
在 Wolfram 系统的任何进程中,Wolfram 系统总是有效利用
ToExpression 将输入的文本形式翻译为要计算的实际表达式.
使用 Wolfram 系统的笔记本前端时,仅当一个单元的内容送到内核进行计算时才进行翻译. 这意味着在笔记本中,不需要将设置的文本形式与有意义的 Wolfram 系统表达式相对应,仅当要把这些文本形式送往内核时这样做才有必要.
标准 Wolfram 系统输入形式的层次结构 (hierarchy).
Wolfram 系统内部建立了一系列标准规则供
ToExpression 使用,将文本形式转化为表达式.
这些规则定义了 Wolfram 系统的
语法. 规则指出,
x+y 应该被解释为
Plus[x,y],而
xy 应该被解释为
Power[x,y]. 若所给的输入是
FullForm 的形式,翻译的规则很简单:每个表达式仅由头部和随后括号内的一列元素组成. 对于
InputForm 的规则稍微复杂一些:其允许使用
+、
= 和
-> 等运算符,并理解运算符出现在运算对象之间时的表达式.
StandardForm 涉及到的规则更加复杂,不仅允许运算符和运算对象以一维序列形式排列,还允许这些运算符和运算对象以二维结构排列.
Wolfram 系统的设置使得
FullForm、
InputForm 和
StandardForm 形成一个严格的分层结构:能用
FullForm 输入的肯定能用
InputForm 输入,而能用
InputForm 输入的也肯定能用
StandardForm 输入.
当使用 Wolfram 系统的笔记本前端时,一般使用
StandardForm 的所有特性. 而当使用的界面基于文本时,一般仅能使用
InputForm 的特性.
当在 Wolfram 系统的笔记本中使用
StandardForm 时,可以直接输入如
x2 或加注图形等的二维形式. 但
InputForm 仅允许一维形式的输入.
如果复制一个不许计算就能翻译的
StandardForm 表达式,该表达式将以
InputForm 形式贴入外部应用. 否则该文本将以线性格式被复制,该格式使用
∖!∖(…∖) 能够精确表示二维结构. 这个线性格式被重新粘贴到 Wolfram 系统笔记本中时将自动转为二维形式.
StandardForm 和其子集
FullForm 和
InputForm 提供了以文本形式代表任意 Wolfram 系统表达式的确切方式. 当给定一种文本形式时,总能被无歧义地转化为所代表的表达式.
TraditionalForm 是作为输出的文本形式的一个例子. 可以将任何 Wolfram 系统表达式显示为
TraditionalForm 的形式. 但
TraditionalForm 不具有
StandardForm 的精确性,通常不能无歧义的由一种
TraditionalForm 的表示返回得到其所代表的表达式.
当
TraditionalForm 的输出是以计算结果的形式生成时,代表输出的实际字符盒集合通常包含特殊的
Interpretation 对象或其他加以特殊标签的形式来指定一个表达式如何由
TraditionalForm 格式的输出被重新构建.
由
StandardForm 通过显式转换得到的
TraditionalForm 也同样如此. 但若要对
TraditionalForm 进行大量编辑,或从头输入时,Wolfram 系统就不得不在没有额外信息的情况下尝试将其进行转化.
在 Wolfram 语言中生成一个庞大的输出表达式时,往往并不希望一下子看到所有的表达式,而是希望先对表达式的一般结构有一个初步认识,然后才有可能深入到具体部分仔细查看.
函数
Short 和
Shallow 可以使用户得到庞大的 Wolfram 语言表达式的
“缩略形式
”.
| Short[expr] | 用一行显示 expr 的缩略形式 |
| Short[expr,n] | 用 n 行显示 expr 的缩略形式 |
| Shallow[expr] | 显示 expr 的 “顶层” |
| Shallow[expr,{depth,length}] | 显示 expr 中指定深度和长度的部分 |
生成一个很长的表达式. 将整个表达式显示出来要占用23行:
用一行给出
t 的
“缩略形式
”,其中
<<>> 表示被省略的项的个数:
Wolfram 语言在生成如
OutputForm 的文本格式的输出时,首先将输出写为一个长行,然后根据要求的文本宽度,将该长行切分成一些
“行
”. 这些切分后的每一
“行
” 当然可能会含有上标或嵌入分式,所以在输出设备上实际显示的可能多于一行. 当在
Short 中指定某一数目的行时,Wolfram 语言认为要选择的是
“逻辑行
” 的数目,而不是在输出设备上实际显示的自然行的数目.
4行形式的
t. 在这个例子中更多的项被显示出来:
Short 在其他形式中也有效,比如在
StandardForm 和
TraditionalForm 等形式中. 当使用这些形式时,自动换行由输出被显示时的笔记本界面决定,而不是由输出被创建时的内核决定. 因此,对由
Short 生成的行数的设定,只能近似于屏幕上实际显示的行数.
Short 指令通过删除表达式中的一些项使得结果中的输出形式能放在所指定的行数内. 但有时最好不指定输出结果中有多少行,而是指定要丢掉表达式中的哪些项.
Shallow[expr,{depth,length}] 仅包含任意函数的
length 个变量,丢掉指定深度之下的所有子表达式.
Shallow 在以统一的方式删除多层嵌套表达式中的项时特别有用,例如
Trace 返回值所产生的大列表结构.
当在笔记本界面中生成的输出过于庞大时,Wolfram 语言自动在输出时应用
Short. 这种用户界面的改善可以避免 Wolfram 语言使用过多的时间对用户可能并不想要的打印输出进行生成和格式化.
用户界面中的按钮允许用户对输出的多少进行控制. 使该行为生效的尺寸临界值由输出表达式的字节计数决定. 该字节计数可以在笔记本界面的
偏好设置 对话框中设置,这一对话框由按钮
设定大小限制 打开.
在 Wolfram 系统的标准输出格式中不包含引号:
可以将任意类型的文本放在 Wolfram 语言字符串中,这包括非英文字符、换行符和其他控制信息.
"字符串和字符" 一节将更深入的讨论字符串的操作.
| StringForm["cccc``cccc",x1,x2,…] | 输出一个字符串,其中相继的 `` 用相继的 xi 替换 |
| StringForm["cccc`i`cccc",x1,x2,…] | 输出一个字符串,其中每个 `i` 由对应的 xi 替换 |
在许多情况下需要使用一字符串作为
“模板
”,而将各种 Wolfram 语言表达式
“拼接
” 在一起输出. 这可用
StringForm 实现.
生成一个输出,其中每一个相继的
`` 由一个表达式替换:
在
StringForm 中的字符串有点像的格式输出语句中的格式指令(format directive). 可以通过将表达式封装在标准输出格式函数内的途径决定在
StringForm 中表达式的输出格式.
应该认识到
StringForm 仅是一种输出格式,其不以任何方式进行计算. 可以使用函数
ToString 从一个
StringForm 的对象创建一个普通字符串.
StringForm 允许用户设定一个
“模板字符串
”,然后填以各种表达式. 有时还需要将一系列表达式的输出形式连接在一起,这可以用
Row 实现.
| Row[{expr1,expr2,…}] | 给出连接在一起的 expri 表达式的输出形式 |
| Row[list, s] | 在连续元素之间插入 s |
| Spacer[w] | |
| Invisible[expr] | 由 expr 的物理尺寸决定的空格 |
Row 也适用于排版表达式(typeset expression):
Row 可以在被展示的元素之间自动插入任何表达式:
利用
Row 等文本字符串和函数,可以生成一段不必对应于 Wolfram 语言有效表达式的输出. 然而有时希望只要不进行表达式的计算,则生成的输出应对应于 Wolfram 语言有效表达式. 函数
Defer 可以使其自变量不被计算但允许其被格式化成 Wolfram 系统的标准输出形式.
当
Defer 的输出被再次计算时(这种情况可以通过对输出进行修改或者使用拷贝和粘贴而发生),计算将正常进行.
下面的输出是从前面的输出单元中拷贝至一个输入单元中:
通过使用
Interpretation,可以生成外观与其计算方式没有直接关联的输出. 当 Wolfram 系统在对某些形式的输出进行格式化,而可读性最好的形式并不与对象的内部表示良好对应时,这种方法被有效使用. 例如,
Series 在其默认输出时,总是生成一个
Interpretation 对象.
将上述输出拷贝和粘贴,所参照的值是先前赋给
x 的值:
数字按照默认输出格式给出. 大数用科学记数法给出:
按照工程记数法给出这些数,其中10的幂指数均是3的倍数:
按照标准会计记数法,负数放在括号中,不用科学记数法:
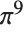
计算到30位:
显示
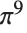
的10位数字:
表中除最后一个选项外的所有选项适用于整数和近似实数.
所有的选项均可用于函数
NumberForm、
ScientificForm、
EngineeringForm 和
AccountingForm. 事实上,这些函数中某个函数行为的再现,可以通过对其他三个函数之一进行适当的选项设置实现. 表中所列的默认选项设置是对
NumberForm 设置的.
Wolfram 语言显示近似实数时,必须对是否使用科学记数法作出选择,如果是,还要知道小数点左边有多少位. 如果使用科学记数法,Wolfram 语言首先找到10的幂指数是多少,并给出小数点左边一位数字. 然后取这个指数值,应用于以选项
ExponentFunction 给出的任意函数. 这个函数的返回值是实际使用的指数,如果不使用科学记数法则返回
Null.
默认格式是对于数字的10的幂指数在
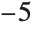
和

之外时使用科学记数法:
在确定了尾数和指数之后,最后一步是将这些组合在一起将对象输出. 选项
NumberFormat 允许给出任意函数设定数字的显示形式. 该函数取三个字符串作为变量:尾数,基底和指数. 如果无指数,则给出
"".
用类似于 Fortran 中
“e
” 格式的形式给出指数:
| PaddedForm[expr,tot] | 所有数字用 tot 位显示,不足时前面加空格 |
| PaddedForm[expr,{tot,frac}] | 所有数字用 tot 位显示,小数点右边有 frac 位 |
| NumberForm[expr,{tot,frac}] | 所有数字最多有 tot 位,其中小数点右边有 frac 位 |
| Column[{expr1,expr2,…}] | expri 左对齐排在一列 |
当在一列中或以其他明确的方式显示一组数字时,通常需要将这些数字按一定方式对齐. 通常希望设置所有数字,使得对应于某一幂指数的位总是出现在数字显示区域中的同一位置.
通过不同的填充方式可以改变数字显示格式中各位的位置. 通常可以通过在小数点后加零进行右填充,或者通过在数字的前面加空格进行左填充.
选项
NumberPadding 使用默认设置时,
NumberForm 和
PaddedForm 从右边填充一个数时插入尾随零(trailing zeros). 通过设置
NumberPadding->{" "," "} 可以用空格进行左右填充.
"不同形式的数之间的转换" 讨论在任意进位制下数的输入,以及如何得到数字各个位的列表.
Grid 和
Column 是封装,不进行计算,只是把内容排版成合适的形式. 他们是排版结构,需要前端正确呈现.
这些封装都可以用来表示任何类型的数据,包括图形数据:
Grid 把矩形矩阵作为其第一个参数. 通过指定跨越区域,
Grid 的单个元素可以跨越多行,多列或一个矩阵子网格. 横跨元素总是在跨越区域的左上角,剩下的区域由适当的跨越符号填补.
设置整个
Grid 基本样式为 Subsection 样式:
Column 是只有一列的
Grid 的缩写. 由于这两个函数是相似的,他们可以用相同的选项.
影响行和列的
Grid 选项都有一个类似的语法. 这些选项可以指定为
{x,y},其中
x 适用于所有列和
y 适用于所有行;
x 和
y 可以是单个值,也可以是值的集合,依次代表每列或行.
当
Background 或
ItemStyle 选项对行和列指定不同的设置,在行和列重叠处前端将尝试组合设置.
要在多个行或列中重复个别行或列的规格,可以将其包装在一个列表中. 重复的元素会尽可能的被使用. 如果你在列表中包装多个元素,整个列表将按序重复.
ItemSize 和
Spacings 选项的ems的水平测量和行高的垂直测量是基于目前的字体设置. 这两个选项也可以采取
Scaled 按比例坐标,坐标指定总的单元宽度或窗口高度的比例. 通过使用关键字
Full,
ItemSize 选项也可让您要求尽可能多的空间,使得所有元素都适合给定的行或列.
这个例子中的按钮大小始终是一个单元格宽度的四分之一:
通过使用
Item,适用于整个行和列的许多设置也适用于
Grid 或
Column 中个别的的项.
Item 允许您更改一个单项的这些设置. 在
Item 级别上定义的设置总是作为一个整体覆盖
Grid 或
Column 的设置.
Item 的大多数选项采取与
Grid 同样的设置. 但是,
Alignment 和
ItemSize 选项例外,在
Grid 中允许复杂的行和列设置,在
Item 中只采取
{horizontal,vertical} 设置.
多维数据格式化
Column 支持一维数据,
Grid 支持二维数据. 可以使用
TableForm 打印任意维的数据.
一般来说,当您打印一个
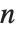
维表,相连的维是以列和行交替给出的. 通过设置选项
TableDirections->{dir1,dir2,…},其中
diri 是
Column 或
Row,您可以明确指定每个维度的方向. 默认情况下,该选项设为
{Column,Row,Column,Row,…}.
TableForm 可以处理任意
“不规则
” 数组. 没有元素时,用空白填补.
可以在嵌套列表中控制层次,在
TableForm 中设置选项
TableDepth.
| | |
| TableDepth | Infinity | 表格中所包含的最大层数 |
| TableDirections | {Column,Row,Column,…} | 每一维是否按行或列排列 |
| TableAlignments | {Left,Bottom,Left,…} | 每一维中如何对齐元素 |
| TableSpacing | {1,3,0,1,0,…} | 在每一维中加多少空格 |
| TableHeadings | {None,None,…} | 怎样标记每一维的元素 |
使用
TableAlignments 选项,可以指定表中的每个项应该是行对齐或列对齐. 对于列,可以指定
Left、
Center 或
Right. 对于行,可以指定
Bottom、
Center 或
Top. 如果设置
TableAlignments->Center,所有项水平和垂直方向均会中心对齐.
TableAlignments->Automatic 使用对齐的缺省选项.
可以用
TableSpacing 选项指明连续的列间应该有多少水平空隙,或连续的行间应该有多少垂直空隙. 设置为
0 指定连续对象应紧挨着.
| Style[expr,options] | 按指定的样式选项显示 |
| Style[expr,"style"] | 按指定的单元样式显示 |
第2个
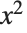
用黑体显示:
如果使用的是 Wolfram 语言的笔记本前端,则生成的每一段输出将默认采用该输出所在单元的样式. 而使用
Style[expr,"style"] 可以令 Wolfram 语言用不同的样式输出一个特定的表达式.
"作为 Wolfram 语言表达式的单元" 更深入地介绍了单元样式的工作方式. 通过使用
Style[expr,"style",options] 可以生成某一特定样式的输出,但需要修改某些选项.
Wolfram 语言中的所有文本和图形格式最终是用框符的嵌套集合来表示的. 通常这些框符中的元素对应于要放在二维相对位置处的对象.
| "text" | 原样的文本 |
| RowBox[{a,b,…}] | 一行框符或字符串 a,b,… |
| GridBox[{{a1,b1,…},{a2,b2,…},…}] |
| |
| SubscriptBox[a,b] | 下标 ab |
| SuperscriptBox[a,b] | 上标 ab |
| SubsuperscriptBox[a,b,c] | 上下标 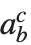 |
| UnderscriptBox[a,b] | 底标 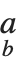 |
| OverscriptBox[a,b] | 顶标 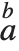 |
| UnderoverscriptBox[a,b,c] | 顶底标 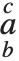 |
| FractionBox[a,b] | 分式 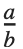 |
| SqrtBox[a] | 平方根 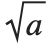 |
| RadicalBox[a,b] | b 次方根 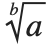 |
StyleBox 与
Style 的选项相同,区别在于
Style 是一个高层函数,应用于表达式中决定其显示方式,而
StyleBox 是对应的低层函数,表示框符的自身结构.
如果使用的是 Wolfram 语言的笔记本前端,则可以用菜单项直接改变屏幕上显示的样式和外观,但这些改变在内部仍将通过插入适当的
StyleBox 对象而记录下来.
在编辑
InterpretationBox 中给出的框符时,无法保证解释框符给出的解释仍是正确的. 于是,Wolfram 语言就提供了许多选项使用户对
InterpretationBox 对象的选择和编辑进行控制.
TagBox 对象用于存储不显示的信息,这些信息被解释框符的规则使用. 一般情况下,
TagBox[boxes,tag] 中的
tag 是一个符号,给出对应于
boxes 的表达式的头部. 如果仅编辑这个表达式中的变量,由
TagBox 指定的解释很可能是适当的. 因此,
Editable->True 是
TagBox 的默认设置.
Wolfram 语言用于解释框符的规则一般不考察
StyleBox 等对象定义的格式细节. 这样在不使用
StripWrapperBoxes->False 时,红色的
x 与普通的黑色
x 没有区别.
Wolfram 语言提供了一种简洁的方式来用字符串表示框符. 在将框符的设定作为普通文本进行导入和导出时,这种方式尤其方便.
重要的一点是区分表示原始框符的格式和表示框符意义的格式.
| ∖(input∖) | 原始框符 |
| ∖!∖(input∖) | 框符的意义 |
如果将一个
StandardForm 单元的内容复制到另一个如文本编辑器的程序中,Wolfram 系统将在必要时生成一个
∖!∖(…∖) 形式. 这样做是为了当讲这个格式的内容重新复制回 Wolfram 系统中时,该
StandardForm 单元的原始内容会自动再次生成. 如果没有
∖!,则仅得到对应于这些内容的原始框符.
在选项的默认设置下,贴入 Wolfram 系统笔记本中的
∖!∖(…∖) 格式自动显示成二维格式.
| "∖(input∖)" | 一个原始字符串 |
| "∖!∖(input∖)" | 含有框符的字符串 |
Wolfram 语言通常将出现在字符串内的
∖(…∖) 格式与其他的一系列字符一样对待. 通过插入
∖! 可以令 Wolfram 语言将这个格式视作所代表的框符. 通过这种方式可以在普通字符串内嵌入框符结构.
\! 告诉 Wolfram 语言这个字符串含有框符:
| ∖(box1,box2,…∖) | RowBox[box1,box2,…] |
| box1∖^box2 | SuperscriptBox[box1,box2] |
| box1∖_box2 | SubscriptBox[box1,box2] |
| box1∖_box2∖%box3 | SubsuperscriptBox[box1,box2,box3] |
| box1∖&box2 | OverscriptBox[box1,box2] |
| box1∖+box2 | UnderscriptBox[box1,box2] |
| box1∖+box2∖%box3 | UnderoverscriptBox[box1,box2,box3] |
| box1∖/box2 | FractionBox[box1,box2] |
| ∖@box | SqrtBox[box] |
| \@box1\%box2 | RadicalBox[box1,box2] |
| form∖` box | FormBox[box,form] |
| \*input | 构建来自 input 的框符 |
Wolfram 语言要求用户给框符的任何输入格式被包括在
∖( 和
∖) 内. 在最外围的
∖( 和
∖) 内还可使用附加的
∖( 和
∖) 来进行分组.
∖( 和
∖) 对分组进行设定,但不像显式的括号一样被显示:
当用户在 Wolfram 语言中敲入
aa+bb 作为输入时,首先发生的是,
aa、
+ 和
bb 被当作一个个单独的项. 当由包括在
∖(…∖) 内的输入构建框件时,也同样如此. 而在框件内部,每一项是以一个字符串的形式给出,而非其原始格式.
RowBox 中的
aa、
+ 和
bb 被分成单独的字符串:
即使给出的字符串不与一个完整的 Wolfram 语言表达式对应,所形成的还是相同的框件结构:
在
∖(…∖) 序列内部,可以通过使用反斜杠标记如
∖^ 和
∖@ 等来设置某些类型的框符. 但对其他的框符,用户需要给出普通的 Wolfram 系统输入,以
∖* 作为开始.
∖* 的行为实际上像一个换码:其允许用户即使在一个
∖(…∖) 序列内也能进入普通 Wolfram 语言语法. 用户在一个
∖* 后给出的输入自身也能够含有
∖(…∖) 序列.
可以对嵌套的
∖* 和
∖(…∖) 互换. 在
∖(…∖) 的外部需要显式引用:
| ∖!∖(input∖) | 解释当前形式中的输入 |
| ∖!∖(form∖`input∖) | 使用指定形式解释输入 |
当用户将一个笔记本中的单元内容复制到文本编辑器等程序中时,通常不包括显式的反斜杠反引号序列. 但如果用户希望将所得到的重新复制到一个不同类型的单元中时,则需包括反斜杠反引号序列以确保所有的解释均正确.
为文件和外部程序生成数据时,有时需要仅用普通键盘字符产生二维形式. 这可以通过使用
OutputForm 实现.
生成一个仅用普通键盘字符的字符串,以二维形式显示表达式:
如果仅对一维结构进行操作,可以通过
ToString 利用格式函数进行字符串操作.
ToExpression 将试图将每个字符串解释为 Wolfram 语言输入. 但如果给出的字符串不能对应于一个语法正确的输入时,就显示一个信息,并返回
$Failed.
可使用函数
SyntaxQ 测试一个特定的字符串是否对应于语法正确的 Wolfram 语言输入. 如果
SyntaxQ 返回
False,可使用
SyntaxLength 找到错误发生的位置.
SyntaxLength 的返回值是语法错误发生之前成功运行的字符数.
SyntaxQ 表明字符串不对应于语法正确的 Wolfram 语言输入:
Wolfram 语言用各种语法规则去解释输入,将字符串或框符转化为表达式. 由
StandardForm 和
InputForm 使用的规则定义了基本的 Wolfram 语言. 由
TraditionalForm 等其他形式使用的规则遵循了同样的原则,但细节上有许多区别.
| a
,
xyz
,
αβγ | 符号 |
| "some text"
,
"α+β" | 字符串 |
| 123.456
,
3*^45 | 数字 |
| +
,
->
,
≠ | 运算符 |
| (*comment*) | 将被忽略的输入 |
当在 Wolfram 语言中输入文本时,Wolfram 语言首先将其分解为
记号序列,其中每个记号代表一个语法单元.
例如输入
xx+yy-zzzz 时,Wolfram 语言将其分解为记号序列
xx、
+、
yy、
- 和
zzzz. 这里
xx、
yy 和
zzzz 是对应于符号的记号,而
+ 和
- 是运算符.
运算符最终决定从一个输入得到的表达式的结构. Wolfram 语言涉及几种一般类型的运算符,这些类型的区别在于运算符相对于运算量的位置.
运算符要从其前后的指定位置找出运算量,当一个字符串中包含多个运算符时,就要确定哪一个运算符先选择运算量.
例如,
a*b+c 有可能被解释为
(a*b)+c 或者
a*(b+c),取决于是
* 还是
+ 先选择其运算量.
为了避免歧义,Wolfram 语言指定了每个运算符的
优先级别,优先级别高的运算符先选择其运算量.
例如,乘号
* 比加号
+ 的优先级别高,所有先选择运算量,
a*b+c 被解释为
(a*b)+c 而不是
a*(b+c).
运算符
* 的优先级别比
+ 高,因此在两种情况下,
Times 都是最里层的函数:
不管所使用运算符的优先级别高低,通过适当插入括号就可以指定所要形成的表达式的结构.
符号名的扩展 | x_
,
#2
,
e::s
, 等等.
|
函数应用变量 | e[e]
,
e@@e
, 等等.
|
与幂相关的运算 | √e
,
e^e
, 等等.
|
| ∇e
,
e/e
,
e⊗e
,
ee
, 等等.
|
与加法相关的运算 | e⊕e
,
e+e
,
e⋃e
, 等等.
|
关系型运算符 | e==e
,
e∼e
,
e⪡e
,
e⧏e
,
e∈e
, 等等.
|
箭头及向量运算 | e⟶e
,
e↗e
,
e⇌e
,
e⥓e
, 等等.
|
逻辑运算符 | ∀ee
,
e&&e
,
e∨e
,
e⊢e
, 等等.
|
模式和规则运算符 | e..
,
e|e
,
e->e
,
e/.e
, 等等.
|
纯函数运算符 | e& |
赋值运算符 | e=e
,
e:=e
, 等等.
|
复合表达式 | e;e |
在
"运算符的输入形式" 一节的表按优先级别次序,给出了 Wolfram 语言中全部的运算符的列表. 如
* 和
+ 的情形相同,大部分次序是由标准数学用法决定的. 一般,设定的次序使在典型的输入块中能尽量少用括号.
注意第一、第二个形式是相同的,第三个则需要加括号:
平等 | x+y+z | x+y+z |
左分组 | x/y/z | (x/y)/z |
右分组 | x^y^z | x^(y^z) |
Wolfram 语言的语法不仅适用于键盘上能输入的字符,也适用于 Wolfram 语言支持的特殊字符.
如
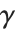
、

和
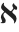
等字母与通常的英语字母一样处理,例如可以以符号名的形式出现. 对

、
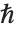
和

等字母型符号也是如此.
但也有许多特殊字符作为运算符,例如

和

为中缀算符,

为前缀算符,
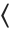
和
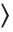
为匹配缀算符.

是中缀算符:

是中缀算符,其含义与
* 相同:
一些特殊字符形成相当复杂的运算符的元素. 例如
∫fx 是含有元素
∫ 和
的复合运算符.
Wolfram 语言中可以用一维字符串输入,也可以用二维单元的形式输入. Wolfram 语言的语法适用于一维结构和二维结构.
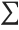
是更复杂的二维复合运算符的一部分:
运算符
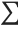
的优先级别比
+ 高:
以
2+2 为例,当进行输入时,Wolfram 语言首先将
+ 识别为一个运算符,并构造表达式
Plus[2,2],然后用
Plus 的内部规则计算该表达式从而得到结果
4.
当并非所有能被 Wolfram 语言识别的运算符都与一个有内部含义的函数相联系. Wolfram 语言也支持几百种额外的运算符用于表达式的构造,但对这些运算符没有事先定义的计算规则.
在 Wolfram 语言语言内部,可以用这些运算符构造自己的记号.

被看作一个中缀运算符,但没有事先定义的值:
可以为

定义一个值:

不仅被看作一个运算符,而且可以进行计算:
对应于未预先定义值函数的一些 Wolfram 语言运算符.
Wolfram 语言按照常规约定,与一个运算符对应的函数与表示这个运算的特定字符具有相同的名称.
| x \[name] y |
name
[
x
,
y
]
|
| \[name] x |
name
[
x
]
|
| \[Leftname] x,y,…\[Rightname] |
name
[
x
,
y
,
…
]
|
Wolfram 语言中运算符名称和函数名称之间的常规对应.
应该认识到,即使函数
CirclePlus 和
CircleTimes 没有给定的内部运算规则,运算符

和

仍具有内部设定的优先级别.
"运算符的输入形式" 一节中按照优先次序列出了能被 Wolfram 语言识别的全部运算符.
运算符

和

有明确的优先级别
——
的优先级高于

:
正如 Wolfram 语言允许用户对表达式如何计算进行定义一样,用户也可以定义表达式按何种格式输出. 其基本思想是在无论何时对给定表达式进行格式输出,Wolfram 语言首先调用函数
Format[expr] 找出是否已经定义了该表达式输出格式的特殊规则. 通过给
Format[expr] 赋值,可以令 Wolfram 语言按一定的方式输出某种类型的表达式.
令 Wolfram 语言按特殊方式设置对象
bin 的格式:
| Format[expr1]:=expr2 | 定义 expr1 与 expr2 的格式相同 |
| Format[expr1,form]:=expr2 | 仅定义一个特殊的输出形式 |
通过
Format 的定义可以令 Wolfram 语言将一个特定表达式的格式与另一个表达式相同t. 也可以令 Wolfram 语言运行一个程序去确定怎样格式化一个表达式.
设定 Wolfram 语言运行一个程序确定如何格式化
xrep 对象:
默认时,
“中缀算符
” <> 的
“优先级别
”比
+ 高,因此不需要加括号:
当输出涉及到运算符时,就需要考虑到是否要对一些变量加括号,正如
"表达式输入的特殊方式" 一节中所讨论的,这取决于运算符的
“优先级
”. 在对涉及到运算符的输出形式进行设置时,可使用
PrecedenceForm 来定义运算符的优先级. Wolfram 语言用1到1000的整数来表示运算符的
“优先级别
”,优先级别越高,越不需要加括号.


的优先级别为
100. 级别较低,就需要加括号:
对
Format[expr] 的赋值就是按 Wolfram 语言输出的标准类型定义
expr 的输出形式. 通过定义
Format[expr,form] 可以指定特殊的输出形式.
在需要 TeX 形式时,就使用对
x 指定的输出形式:
Wolfram 语言中有许多规则产生输出和解释输入. 尤其是在
StandardForm 中,这些规则被精心设计成一致的,允许输入和输出交换使用.
一般不需要修改这些规则. 主要是因为 Wolfram 语言对没有特定含义的运算符已经定义了输出和输入规则.
所以当需要进行更一般的相加时,就可以使用运算符

,Wolfram 语言已经对其设置了输入和输出规则.
使用运算符

的输出:
Wolfram 语言理解输入中的

:
通过定义
Format[expr] 可以改变某一特定表达式的输出格式. 但要认识到一旦这样做,无法保证所定义的表达式的输出形式在作为 Wolfram 语言的输入时被正确解释.
需要时可以在 Wolfram 语言中重新定义用于表达式的输入和输出的基本规则,这可以通过定义
MakeBoxes 和
MakeExpression 来实现. 但一定要非常仔细地给出这类定义,否则可能出现不一致的结果.
gplus 用带下标的

输出:
令 Wolfram 语言将带下标的

解释为
FullForm 输入的一个特定部分:
带下标的

被解释成
gplus:
可以将定义
MakeBoxes 看作实质上给出
Format 的底层定义. 一个重要的区别是
MakeBoxes 不计算其变量,所以可以定义表达式格式化的规则,而不需要考虑这些表达式将如何被计算.
另外,对于
Format 产生的任何结果进行格式化时,
Format 被自动再次调用,而
MakeBoxes 不是这样. 这意味着定义了
MakeBoxes 后,对子表达式格式化必须重新明确调用
MakeBoxes.
■ 将输入分解为记号. |
■ 去掉空格字符. |
■ 使用内部的优先级构造框符. |
■ 去掉 StyleBox 和其他不需要被解释的框符. |
|
在
"文本输入和输出" 一节中所介绍的函数决定了表达式被显示时的格式,但这些函数并不能实际上生成任何要显示的内容.
在 Wolfram 语言最常见的使用方式中不需要用指令生成输出. Wolfram 语言通常会自动显示对给定输入处理后的最终结果. 但有时需要显示运算的中间过程,这可以使用函数
Print 实现.
| Print[expr1,expr2,…] | 显示表达式 expri,中间无空格,但结尾换行 |
Print 简单地逐个显示所给变量,变量间无空格. 在很多时候需要以更复杂的形式显示输出,这可以通过将输出形式作为
Print 的一个变量来实现.
由
Print 生成的输出通常是标准 Wolfram 语言输出格式,但通过显示指定也可以使用其他输出格式.
应该认识到
Print 仅是 Wolfram 语言中生成输出的几种途径之一. 另一种途径是在
"消息" 一节中介绍的
Message 函数,其用于生成命名信息. 在
"流和底层的输入输出" 一节中还介绍了一些底层函数,可以用来生成各种格式的输出,这些输出既作为交互进程的一部分,又用于文件和外部程序.
另外还有一个命令,
PrintTemporary,其工作方式与
Print 完全相同,但仅在最终计算完成后才显示输出.
自从版本3以来,Wolfram 语言提供了对任意数学排版和布局的有力支持. 这一切基于所谓的
框符语言(box
language
),其允许笔记本自身作为 Wolfram 语言的表达式. 这种方法被证明是非常强大的,并已形成 Wolfram 语言中许多独特功能的基础. 但尽管这种框符语言非常强大,在实际操作时却很难被用户直接使用.
自从版本6开始,出现了这种框符语言的高层界面,这免去了直接使用框符的苦恼,却仍保持了同样的排版和布局的强大功能. 这个新层的函数被称为
框符生成器,但用户不必意识到框符语言就能够有效使用这些函数. 在本节教程中,我们首先了解一下与显示大量表达式相关的框符生成器,然后再介绍几种超出了简单数学排版的方式,这些方式能用于生成漂亮的格式化输出.
样式化输出(Styling Output)
Wolfram 系统前端支持文字处理器中出现的所有惯用样式机制,例如包括变换字体特征的菜单. 然而,在生成的结果中自动访问这些样式机制曾经非常困难. 输出继续采用纯12号 Courier 字体(或使用
TraditionalForm 时为 Times 字体). 为了解决这个问题,创建了函数
Style. 无论何时对一个
Style 表达式进行计算,其输出结果将以给定的样式特征显示 .
可以将任何表达式封装
Style. 下面这个例子通过
Style 选用不同的字体灰度和颜色对质数和合数进行显示.
有上百种格式化选项可以与
Style 结合使用(更完整的列表请参见关于
Style 的参考资料),此处列出的是最常见的几个选项.
Style 可以被任意嵌套,在有冲突时最内层具有最高的优先权. 这里用
Style 封装整个列表从而对列表中的所有元素应用一种新的字体.
要求一段输出的样式与文本一样也是很常见的. 将代码所用的字体用于文本可能会看上去非常奇怪. 为此,有一个函数
Text 能够使其参数将永远在文本字体中呈现.(熟悉 Wolfram 语言数学图形的用户将把
Text 函数识别为一个图形基元,但那种用法并不会与这种用法冲突.)
Style 可用于屏幕上任何选项被激活处的区域设置,不仅仅是与字体相关的选项. 在本节教程的后面,可以看到
Style 如何影响如
Grid 或
Tooltip 等其他格式结构的显示特征.
网格布局(Grid Layout)
二维布局结构的使用可以如对这些结构应用样式指令一样有用. 在 Wolfram 语言中,这种布局的基本函数是
Grid.
Grid 的布局功能很灵活,能够任意调整对齐方式,框架元素(frame elements),以及跨度元素(spanning element)等. (其他教程更深入地介绍了
Grid 的功能,这里仅介绍讨论其重点部分.)
再次观察将质数和合数进行不同显示的
Style 例子.
要将此放入一个
Grid 中,首先使用
Partition 将这个含有100个元素的列表转换成一个10
×10数组. 尽管可以给
Grid 一个参差不齐的的阵列(列表中的元素为长度不一的列表),在这个例子中我们给
Grid 一个常规数组,且所得到的显示结果经过了漂亮的格式化布局.
注意到各列按中心对齐,且无框架线,使用
Grid 的选项可以很容易的改变这两项的设置.
对于全体
Grid 选项及其语法的完整描述超出了本文的范围,但使用他们完成一些不寻常的任务是可能的. 全部细节参见完全的
Grid 参考资料.
有几项与
Grid 相关的有用的结构,其中一个是
Column,可以取出一列水平的元素将其垂直排列. 用
Grid 完成这一任务会稍显笨拙. 这里是一个简单的例子,可以将一列选项按列显示.
如何水平列出一列事物呢? 那种情况下,你要问的主要的问题是,是否要得到的显示像一行数字或文本一样换行,还是要所有元素保持在一行. 在后一种情况,可以将
Grid 应用于1
×n 的阵列.
但注意到在这个例子中,整个网格收缩,以便其与现有窗口的宽度适合. 因此网格中有的元素自身能够进行多行换行. 这是由于
Grid 的默认
ItemSize 选项. 如果想要允许一个网格的元素具有自然宽度,要将
ItemSize 设置为
Full.
当然,这时整个网格过宽而不能在一行中被容纳(除非将这个窗口设置的很宽),因此网格中有的元素无法被看到. 这把我们带到另一种横向布局函数:
Row.
给定元素的列表,
Row 将使整体结果按自然方式自动换行,就像一个文本行或数学行一样. 曾经可能使用过现已废弃的
SequenceForm 函数的用户会对这种类型的布局比较熟悉.
默认时
Row 不在元素间留空格. 但若给出第二个参数,则表达式将被插入元素之间. 可以使用任何形式的表达式,此处用的是一个逗号.
如果调整笔记本窗口的尺寸,将看到设置为
ItemSize->Automatic 时的
Grid 其行为仍与
Row 不同,每一个在不同的情形中都有用.
将输出用作输入
这是一个很好的机会来指出
Style、
Grid 及其他框符生成器在输出中是持久的. 如果所取的一段输出中的某些格式是由
Style 或者
Grid 创建并作为输入被再次使用,则
Style 或
Grid 表达式将在输入表达式中出现. 对
StyleBox 的旧用法甚至是对
MatrixForm 函数熟悉的用户将会发现这一改变.
将这个具有许多嵌入样式的
Grid 命令的输出用作某个输入表达式.
请注意这仍然是一个网格,仍是蓝色的,其元素仍然像以前一样为粗体或灰色. 还要注意,表达式中有
Grid 和
Style 起到了干预效果,否则会给一个矩阵添加一个标量,并将结果进行乘幂. 这种区分是非常重要的,因为往往希望不要将这些复合结构以某种方式自动解释. 但是若想摆脱这些封装并获得你的数据,这也是很容易做到的.
特殊网格条目(Special Grid Entries)
为了让二维布局更灵活,
Grid 接受
SpanFromLeft 等一些特殊符号作为条目. 条目
SpanFromLeft 表明,紧靠左边的网格条目既占用自己的空间也占用跨越字符的空间. 类似的还有
SpanFromAbove 和
SpanFromBoth. 详细信息请参见
"Mathematica 中的网格、行和列" 一节.
这种方法可以用来创建复杂的跨度设置. 用键盘进行下列输入需要很长的时间. 幸运的是,您可以在 子菜单中使用 和 交互地创建此表. 如果想看看进行下述输入时会牵连到什么,则需要计算该单元,其将展示您应如何进行键盘输入.
我们已经看到了如何作为一个整体或针对个别列或行,在网格中进行对齐方式和背景的设置. 我们还没有看到的是如何针对单个元素对设置进行覆盖. 假设您希望您的整个网格中除一些特殊元素外都有相同的背景,一个方便的方法将每一个这种元素封装在
Item 中,然后指定
Item 的选项,覆盖
Grid 中相应的选项.
也可以通过
Style 来覆盖该选项,但
Item 的目的是使覆盖的方式知道
Grid 的二维布局. 注意到在前面的输出中,一旦两个黄色单元彼此相邻,则两者之间没有蓝色空格,这只能通过
Item 实现.
不仅仅是
Background,对于
Item 的所有选项均是如此. 现在来看
Frame 选项,如果只想在某些特定元素周围加框架,而其他部位不加,您很可能认为必须在这些元素自己的
Grid 中进行
Frame->True 的设置来完成.(在 "
框架和标签" 中我们将学习一种更简单的方法来给任意一个表达式加框架.)
但请注意相邻框架元素不分享其边界. 相比之下,使用
Item,有足够的信息画出不必要的框架元素. 注意现在2和11的框架交于一点,以及2和3的框架如何共享一个像素的线,而这又完全与13和23的左边框对齐. 这就是
Item 的强大功能.
框架和标签
一个表达式添加框架或标签可以通过
Grid 完成,但这些操作在概念上比一般的二维布局简单得多,所以有相应更简单的方法来达到这个目的. 例如
Framed 是一个简单的函数,用于在任意表达式周围绘制一个框架,这样做可以将注意力吸引到表达式的各个部分.
Labeled 也是这样的一个函数,其允许在给定表达式周围的任意一处加标签. 此处我们给上一小节的
Grid 例子加上图例. (
Spacer 是为留空格设计的函数.)
Panel 是另一个构建框架的函数,使用底层操作系统的面板框架. 这不同于
Frame,因为不同的操作系统可能会使用阴影、圆角或用于面板框架的花哨的图形设计元素.
注意
Panel 对于字体类和字体尺寸也有自己的定义,因此
Grid 的内容改变字体类和尺寸,
Text 也改变字体尺寸. (尽管如此
Text 关于字体类有自己的定义,且保持 Wolfram 系统中的文本字体.) 在关于
BaseStyle 选项的小节中,我们将对此进行较深入地探讨.
最后应该指出的是,
Panel 自身有一个可选的第二个参数,用于指定一个或多个标签,其会自动在面板以外定位,还有一个可选的第三个参数,用于给出该位置的细节. 详见
Panel 的参考资料.
其他注释
到目前为止所提到的注释都有一个非常明确的可视组件. 还有一些注释在用户需要之前实际上是不可见的. 例如
Tooltip 不改变其第一个参数的显示,只有将鼠标指针在显示部分移动时,第二个参数才作为一个提示条(tooltips)出现.
Mouseover 也属于这类函数,但不是在提示中显示结果,其使用的屏幕区域与后来鼠标指针在上移动的区域相同. 如果这两个显示的大小不同,那么效果会不和谐,因此使用大小相近的显示,或者使用
Mouseover 中的
ImageSize 选项给两个中较大的显示留出空间,无论正在显示哪一个.
与
Tooltip 类似的是
StatusArea 和
PopupWindow.
StatusArea 在笔记本的状态区域(status area)显示额外信息,该区域通常在左下角,而
PopupWindow 将在点击时将额外信息显示在一个新窗口中.
最后可以通过成对使用
Annotation 和
MouseAnnotation 为一个注释指定一个任意位置.
当使用的注释仅仅通过在屏幕的一个区域移动鼠标指针而触发时,考虑用户是很重要. 移动鼠标不应该引发长时间的计算或很多的视觉混乱. 但是谨慎的使用注释可以给用户带来很大的帮助.
请注意所有这些注释在图形中也同样适用. 因此可以提供提示条(tooltips)或鼠标悬停(mouseovers)协助用户了解所创建的复杂图形.
ListPlot 或者
DensityPlot 这样的可视化函数也支持
Tooltip. 详细情况请参见参考资料.
默认样式
正如在 "
框架和标签" 中所看到的,对
Panel 等的创建实际上类似于
Style,因为其设置了一个能使一组默认样式应用于其内容的环境. 这可以通过明确的
Style 命令进行覆盖,也可以被
Panel 自身通过
BaseStyle 选项覆盖.
BaseStyle 可以被设置为一种样式,或者是一列样式指令,正如在
Style 中的用法一样,并且这些指令成为该
Panel 范围内的默认环境.
Panel 在默认情况下使用对话框字体系列和尺寸,但是这可以用
BaseStyle 选项进行覆盖.
事实上,几乎所用的框符生成器都有一个
BaseStyle 选项. 例如这里是一个默认字体颜色为蓝色的网格,注意灰色的元素保持灰色,因为内部的
Style 封装胜过外围
Grid 的
BaseStyle. (这是
选项可继承性的主要特征之一,其超出了本文的讨论范围.)
默认选项
假设您有一个表达式,多次出现同一框符生成器,如一个
Framed 或
Panel,您想将其全部改变,使之含有相同的选项集合. 在函数每一次出现时都添加相同的选项集可能会非常繁琐, 幸好这里有一个更简单的方法.
DefaultOptions 是
Style 的一个选项,当被设置成形如
head->{opt->val,…} 的一列元素时,该选项会用所给选项设置一个环境,作为给定框符生成头部的默认环境. 在整个
Style 的封装内这些选项都是激活状态,但只针对于相关联的框符发生器.
假设有一个表达式含有某些
Framed 项,你希望所有这些项都用相同背景和框架样式画出.
事实上,这个输入太短,不能看到该语法的优越性. 但是如果手动指定同一列表,就可看出其优越性.
现在在每一个
Framed 的封装内插入
Background 和
FrameStyle 选项会非常耗时,尽管一定能做到(或者通过写一段程序来为您完成). 而使用
DefaultOptions,可以有效的设置一个环境,使得所有的
Framed 封装都使用对
Background 和
FrameStyle 的设置.
这种方法可以方便地建立遵循统一样式的结构,而不必将样式在多处进行指定,这可以产生相对清晰的代码和更小的文件,也更易于维护.
数学排版
没有格式化输出的讨论将是不完整的,至少要提及数学语法中所特有的格式结构.
我们将不对此进行详细,但会指出这些结构在内核中没有任何内置的数学意义. 例如,
Superscript[a,b] 不会被解释为
Power[a,b],尽管两者的显示相同. 因此可以在格式化输出时将这些作为结构元素使用,而不必担心其意义会影响显示.
使用框符语言(Box Language)
最后一点说明是,对于已经很熟悉框符语言的用户可能偶尔会发现,这些框符生成器在构建的底层框符时会产生阻碍,将其显示插入到一段输出中. 这可以适用于任何一个分层技术,在抽象层将试图隐藏其所在层. 然而,通过一个简单的漏洞,可以将您恰好知道是有效的框符直接显示在输出中:
RawBoxes.
正如和其他所有漏洞一样,
RawBoxes 给了更高的灵活性,但也可以让您搬起石头砸自己的脚,请小心使用. 如果还不熟悉框符语言,也许不应该使用.
基本结构
Wolfram 语言提供了在屏幕上或页面上布局内容的广泛的且强大的结构. 其目的是使初学者立即会用,还允许很好的控制几乎每一个方位的外观.
这些结构可以分为三类:显示在笔记本中的排版结构,产生内容排列在网格上的图形函数,在网格内可以调整格式细节的结构.
Grid、
Column 和
Row 形成第一系列,在本教程中是指网格系列. 其界定特点是 Wolfram 语言排版系统紧密集成的一部分. 这意味着任何可以作为内容出现的表达式和结构其本身可以响应诸如窗口宽度,甚至元素大小的变化. 与其他排版结构相同,网格系列的成员是惰性结构,不会计算成其他形式.
当处理图形时,结构的并行设置
——图形网格系列支持特别有用的功能. 这些结构是
GraphicsGrid、
GraphicsColumn 和
GraphicsRow. 虽然图形可以在网格系列中使用,但是图形网格系列支持的大小和编辑行为更适合图形. 图形网格的系列有带参数的函数且可以计算出新的图形表达,这意味着难以使生成的网格与其环境的变化作出反应,但很容易交互地添加任意注释和额外的图形.
最后一个系列
——嵌入式结构系列
——由嵌入自身网格的结构组成,并从内部改变网格的外观. 为了定义周边的样式,
Item 可以封装网格的元素.
SpanFromLeft、
SpanFromAbove 和
SpanFromBoth 用于创建横跨多个行或列的区域.
网格系列
| Grid[{{expr11,expr12,…},{expr21,expr22,…},…}] |
| 将 exprij 放置于二维网格的对象 |
| Column[{expr1,expr2,…}] | 将 expri 排列成一列的对象,其中 expr1 在 expr2 之上,依此类推 |
| Row[{expr1,expr2,…}] | 将 expri 排成一行、可能延续数行的对象 |
图形网格系列
嵌入结构系列
在网格和图形网格系列中嵌入元素时,具有特殊意义的结构.
功能类别
Grid 和相关的结构允许大量的外观自定义,只需很少的语法. 下表显示所支持的功能,在后面的章节会有详细的说明.
|
| 1.234` |
| 12.34` |
| 123.4` |
| 1234.` |
|
| "first" | 1 |
| "second" | 100 |
| "last" | 1000 |
| {,} |
- 可以用跨越元素,或元素本身就是网格的元素来精心制作结构.
选项的语法
调整网格的外观存在着各种各样的选项. 本节介绍了这些选项共同的常用语法. 此语法提供了一种不仅对整个网格分配选项值,而且对单个的行、列、甚至项分配选项值.
对于许多选项的整体语法,诸如 Background 是基于像 Background->{specx,specy} 这种形式,其中 specx 是模块语法包含不同列的值,specy 包含不同行的值.
| spec | 在所有项应用 spec |
| {specx} | 在连续水平位置应用 specx |
| {specx,specy} | 在连续水平和垂直位置应用 speck |
| {specx,specy,rules} | 基于 i,j 在数组的位置给出项的规则 |
specx 和
specy 可以有两种形式,如下所示. 第一种形式就是用索引来指定值,第二种形式是按列表中的顺序给出值.
这两种方法有不同的长处,详见 "使用规则" 和 "使用列表".
使用规则
规则提供了一个直接和可读的方法来提供一个具体的行或列的特定值.
当有很多行或列时,规则很方便设置其中少数的属性.
规则还可以用于对特定的网格构件或分区域赋值. 但是请注意,尽管在概念上是类似的,这下面的语法和先前所讨论的 specx 和 specy 是不同的.
设置从
{1,1} 到
{3,3} 区域的元素的背景:
规则可以有效地指定值的例外. 然而,当用手动指定网格的每块的值时,效率较低.
为了获得重复模式,建议您使用 下一节 讲述的列表语法.
使用列表
给出列表的序列值是一种紧密方便的方式,可以指定相邻的行或列的大量选项值.
另外,可以用子列来指定循环使用的值.
这些循环子列表,可以填充在开始或结束.
因为列表中的位置与网格位置相对应,指定中间位置的单个值需要给出其前面的所有值. 若要更直接地获得这些,使用本节 “使用规则” 所描述的规则.
同时使用
最好是两全其美,使用列表语法指定网格的重复部分,同时使用规则语法指定例外.
| {s1,s2,…,sn} | 使用 s1 到 sn;然后是缺省值 |
| {{c}} | 所有情况下使用 c |
| {{c1,c2}} | 在 c1 和 c2 间变换 |
| {{c1,c2,…}} | 循环使用所有的 ci |
| {s,{c}} | 使用 s,然后重复使用 c |
| {s1,{c},sn} | 使用 s1,然后重复使用 c,最后使用 sn |
| {s1,s2,…,{c1,c2,…},sm,…,sn
}
| 开头使用 si 第一个序列,然后循环使用 ci,结尾使用 si 的剩余序列 |
| {s1,s2,…,{},sm,…,sn} | 开头使用 si 第一个序列,结尾使用 si 的剩余序列 |
| {i1->v1,i2->v2,…} | 指定在位置 ik 使用什么 |
| {spec,rules} | 使用 rules 覆盖 spec 中的规则 |
列、行、 缝隙和项
正如在
前面部分所介绍的,Wolfram 语言提供灵活的语法,可以在网格的不同区域改变选项的值. 本节提供该语言的前后关系和阐述更精细的区分.
| column | 项的垂直序列 |
| row | 项的水平序列 |
| item | 包含一个网格元素的区域 |
| gutter | 连续行或列之间的边界 |
Grid 和 GraphicsGrid 遵循描述网格不同部分的相同的约定. Column、GraphicsColumn 和 GraphicsRow 遵循相同的约定,但只处理两维中的一维. Row 不参与这种约定.
选项集合
下表列出了可以处理的选项,没有选项适用于所有的结构. 从下表中可以看出在给定的结构中可以使用哪些选项.
注意 Row 没有采纳任何选项.
先列后行
要记住选项的语法,最重要的一步是要知道,首先指定列的具体值,然后是指定行的值.
| opt->val | 所有的项使用 val |
| opt->{colspec,rowspec} | 列使用 colspec,行使用 rowspec |
| opt->{colspec} | 列使用 colspec,行使用缺省值 |
在 Wolfram 语言中,带有横向设置 h 和垂直设置 v 的选项指定为 opt->{h,v}. ImageSize 和 PlotRange 是两个常用的建立该约定的选项.
在网格中,这些横向和纵向设置分别对应列和行的值. 这是因为列水平堆叠,因此其属性:如宽度和位置,是与水平方向相对应的. 行是垂直叠放,其属性是与纵向相对应的.
如下网格中,每个项的宽是2个
“ems
”,高是1个
“ex
”:
缝隙
与属性相关的许多 Grid 选项最终与网格中的一列,行或项相关.
然而还有处理行与列的间隙的选项.
Dividers 和 Spacings 的语法与其他选项一样. 对于一个在特定方向上有 n 个项的网格,Dividers 和 Spacings 可以指定元素之间的 n+1 个间隔,在第一个元素之前开始和在最后一个元素之后结束.
项
描述最细致的是项,在网格中的每个项都可以自己的值,如 Background、 Alignment 和 Frame.
分割线和框架
Wolfram 语言提供一个延伸的系统描述在网格中应画怎样的分割线和框架.
Frame 总是在封闭区域的四面画线,Dividers 允许更低层次的控制.
使用分割线时,线只适用与单个方向.
分割线和框架的样式
一般来说,可以使用任何线和色彩指令,包括
Hue、
Thickness、
Dashing、
Dotted 和其他. 多种指令可以用
Directive 来组合.
优先级
当样式给定有冲突时,Dividers 优先于 Frame,而他们优先于 FrameStyle. Item 定义的样式优先级最高.
对齐和位置
漂亮的网格往往需要对齐,Wolfram 语言对于网格中的不同对齐有相当的支持.
还可以不同的列有不同的横向对齐,不同的行有不同的纵向对齐.
设置在
{1,1} 位置的元素左对齐,在
{1,2} 位置的元素右对齐:
在其包围环境中定位网格可以用
BaselinePosition.
对齐网格,使该
{2,1} 元素的基线是在整体基线上:
背景和样式
普通常识
当与元素集合一起工作时,
Grid 提供了设置单独背景的方法.
虽然单个元素可以有自己的背景,但当您把所有元素放在一起时,结果会很糟糕.
Grid 和相关的函数把背景放在包含这些元素的全部项的组合上.
使用更复杂的语法,各种模式都很容易实现.
重叠背景设置的优先级
跨越和嵌套
二维空间的复杂分区可以通过嵌套网格结构和/或使用跨越元素来实现.
顾名思义, 跨越元素允许跨越多列、多行或两者兼而有之.
重要的是要注意:跨越区域必须是矩形,不在矩形内的项不会跨越,而只会显示跨越字符.
虽然许多布局可以用跨越元素实现,有时使用简单的嵌套网格结构更快、更方便:
尤其是复杂的网格,往往使用
Row 和
Column 来创建所需的具体结构更清晰,而不是试图设计一种复杂的跨越系统.
尺寸和间隙
网格中的尺寸
Grid 通常不修改其内容的大小. 此外,默认情况下,行和列设计成只需容纳内容即可.
在上面的例子中,第二行比第一行长,第二列比第一列窄,但元素的尺寸没有改变.
如果在网格中的元素交互或动态变化,整个网格的大小将自动适当调整.
一个有用的例外是, Button 将自动填充可用空间.
ItemSize 可以用来覆盖缺省的设置.
ItemSize 的单位是排版单位:“exs” 和 “ems”.
也可以使用 Scaled 来指定封闭区的一小部分的宽度.
网格中的换行
如果列太窄,文本项会换行,但这会导致行比设置的最小值高.
GraphicsGrid 中的尺寸
默认情况下,GraphicsGrid 将返回一个有相同大小项的网格.
会自动选择适合整个元素集合的纵横比.
和相同的 Grid 例子比较,并没有改变任何一个整体大小或纵横比.
GraphicsGrid 不支持 ItemSize 选项,但是支持 ImageSize.
Wolfram 语言通常根据输入进行处理. 有时在写的程序中需要更多的输入,可以用
Input 和
InputString 来实现.
Input 和
InputString 的工作依赖于所用的计算机系统和 Wolfram 语言界面. 在文本界面中,他们等待标准的输入,用回车结束. 在笔记本界面中,在前端中出现一个
“对话框
” 让用户输入.
一般地,
Input 主要用于读入完整的 Wolfram 语言表达式.
InputString 主要用来读入任意字符串.
Wolfram 语言有处理计算中所产生消息的机制. 许多 Wolfram 语言内部函数用这种机制产生错误和警告消息. 这种机制可以用于自定义函数的消息.
基本思想是每条消息有一个确定的名称,形式为
symbol::tag. 可以用这些名称指代消息(对象
symbol::tag 的头部为
MessageName.)
| Quiet[expr] | 计算 expr 不显示任何消息 |
| Quiet[expr,{s1::tag,s2::tag,…}] | 计算 expr 不显示指定的消息 |
| Off[s::tag] | 关闭消息使其不显示 |
| On[s::tag] | 打开消息 |
如
“提示和消息”所示,可以用
Quiet 控制显示特别的消息. 默认情况下,大部分内部函数的有关消息是打开的. 可以使用
Off 永久关闭消息.
可以使用
On 和
Off 全局改变特殊消息的显示. 可以用
Off 关闭不想看的消息.
尽管大部分与内部函数有关的消息默认是打开的,但也有些是关闭的,要明确打开才能显示. 一个例子是消息
General::newsym,详见
"拦截新符号的产生", 任何新符号产生时会显示一个消息.
| s::tag | 给出消息内容 |
| s::tag=string | 设置消息内容 |
| Messages[s] | 显示与 s 相关的消息 |
名为
s::tag 的消息内容作为
s::tag 的值存放,与符号
s 相联系. 可以简单地用
s::tag 查看该消息. 也可以通过对
s::tag 赋值设置消息.
消息总是以适用于
StringForm 的字符串存放. 当需要显示时,一些相应的表达式就拼接成该消息. 这些表达式用
HoldForm 封装,以防止被计算. 此外,任何被指定为全局变量
$MessagePrePrint 的函数在被交给
StringForm 之前作用于这些表达式.
$MessagePrePrint 默认使用
Short 作为文本格式,并且组合
Short 和
Shallow 来排版.
大部分消息与产生其函数有关. 但也有一些
“一般
” 消息,各种函数都产生这种消息.
当给函数
F 的变量数目不正确时,Wolfram 语言将显示警告消息诸如,
F::argx. 如果 Wolfram 语言找不到命名为
F::argx 的消息时,就用
“一般
”消息
General::argx 代替. 可以用
Off[F::argx] 关闭对函数
F 的变量计数的消息,也可以用
Off[General::argx] 关闭所有使用一般消息文本的消息.
当对内部函数给出的变量个数有误时,Wolfram 语言就显示一个消息:
这个自变量计数消息是一个一般消息,许多函数都使用他:
屏蔽
Sqrt::argx 仅压缩由
Sqrt 函数产生的消息,不是由其他函数产生的.
屏蔽
General::argx 压缩所有使用
General::argx 的消息.
如果
F::tag 消息没有使用
General::tag,压缩
General::tag 不会压缩
F::tag. 比如,关掉
General::targ 消息不会关掉
Entropy::targ 消息,因为两个消息是不一样的.
当计算中出现严重错误时,就会发现同样的警告消息反复产生. 这会导致混乱. 于是 Wolfram 语言就跟踪一个计算过程中的所有消息, 当一条消息重复出现多于3次时就不再显示. 当这一情况发生时,Wolfram 语言就显示消息
General::stop 去提醒用户. 如果需要查看所有 Wolfram 语言显示的消息,就要关闭
General::stop.
在每一个计算中,Wolfram 语言将所产生的全部消息放在列表
$MessageList 中. 在标准的 Wolfram 语言进程中,每一行的输出产生后就清除这个消息列表,但在计算过程中可以访问这个列表. 另外,在一个进程中第
n 行的输出产生时,
$MessageList 的值就赋给
MessageList[n].
在编辑时需要自动知道一个计算过程中是否产生了消息. 如果产生的消息告知生成了一些不确定的数值结果,那么计算的结果可能就失去了意义.
| Check[expr,failexpr] | 当计算 expr 时没有产生消息,则返回值 expr; 否则返回 failexpr |
| Check[expr,failexpr,s1::t1,s2::t2,…] | 仅检查消息 si::ti |
计算
0^0 时产生消息,所以返回值是
Check 的第 2 个变量:
Check[expr,failexpr] 测试实际显示的所有消息. 并不测试用
Off 关闭的消息.
有时仅需要测试某一些特定消息,如与数值溢出有关的消息,这就需要告诉
Check 所需要测试的消息名.
用
Message 函数可以模仿内部函数产生消息的各种方式. 用
On 和
Off 打开或关闭消息,
Message 找不到指定消息
s::tag 时就自动寻找
General::tag.
调用
Message 时,先找指定名称的消息,找不到时就找一个与
General 符号相关的比较合适的消息名. 再找不到时 ,Wolfram 语言就将所定义的任意函数作全局变量
$NewMessage 的值,且将该函数作用到所要求消息的符号和标记上.
通过对
$NewMessage 的适当设置,当第一次需要一个消息时,就可以让 Wolfram 语言从一个文件读入消息内容.
Wolfram 语言内部函数消息的标准设置是用美式英语书写的. 在一些版本的 Wolfram 系统中,也有其他语言的消息. 当自己设置消息时,可以用其他语言.
Wolfram 系统中的各种语言习惯上用字符串给出,并使用英语以避免特殊的符号,例如,在 Wolfram 系统中,用
"French" 指定法语.
当所使用的 Wolfram 系统版本有法语消息时,会产生法语消息:
| symbol::tag | 消息的默认形式 |
| symbol::tag::Language | 特定语言的消息 |
当 Wolfram 语言的内部函数产生消息时,先寻找由
$Language 指定的
s::t::Language 型的消息,找不到时就用一个没有明确语言规范的形式
s::t.
自定义函数用消息名
s::t 调用
Message 的过程与内部函数相同. 如果消息名中明确给出了语言,就仅用那种语言.
有多种方式把 Wolfram 语言中编写的代码记录在文件中. 最好的方法是写清晰的代码,而且尽量使用明确的对象名.
有时为了便于理解需要在代码中加入
“注解文本
”. 您可以在代码的任何地方用
(* 和
*) 插入注解. 在
(* 和
*) 的注解中可以有嵌套.
在 Wolfram 语言代码的任何地方都可以加注解:
| (*text*) | 在 Wolfram 语言代码的任何地方都可以插入注解 |
Wolfram 语言中约定所有要被使用的函数有一个使用信息,该信息记录函数的基本用法. 其定义为
f::usage 的值. 当输入
?f 时就显示该信息.
| f::usage="text" | 定义函数的使用信息 |
| ?f | 得到函数的信息 |
| ??f | 得到函数的更多信息 |
??f 给出 Wolfram 语言所知道的
f 的全部信息,包括实际的定义:
定义一个函数
f 时,用
?f 得到值. 但对
f 定义了使用信息时,
?f 仅给出其使用信息,仅当输入
??f 时才得到
f 的详细信息,包括实际定义.
当用
? 查一个函数的信息时,Wolfram 语言显示该函数全部使用信息. 但如果同时查询多个函数的信息时,Wolfram 语言仅给出这些函数名,如有可能,还给出其使用信息的链接.
给出 Wolfram 语言中所有以 "Plot" 开头的函数:
在文本界面下使用 Wolfram 语言时,信息和注解是记录定义的基本机制, 但在笔记本界面中使用 Wolfram 语言时,可以在笔记本的文本单元中产生更全的文件.

